There is now an ONLINE option for non-clustered columnstore index builds and rebuilds
We first setup a database justdave1 with In-Memory support and then create a memory optimized table Numbers1
CREATE DATABASE justdave1; ALTER DATABASE justdave1 ADD FILEGROUP justdave1 CONTAINS MEMORY_OPTIMIZED_DATA; ALTER DATABASE justdave1 ADD FILE (name='justdave1_1', filename='C:\DATA\justdave1_1') TO FILEGROUP justdave1; USE justdave1; DROP TABLE IF EXISTS dbo.Numbers1; CREATE TABLE dbo.Numbers1 ( NumberID int NOT NULL PRIMARY KEY NONCLUSTERED ) WITH (MEMORY_OPTIMIZED=ON); WITH Pass0 as (select 1 as C union all select 1), --2 rows Pass1 as (select 1 as C from Pass0 as A, Pass0 as B),--4 rows Pass2 as (select 1 as C from Pass1 as A, Pass1 as B),--16 rows Pass3 as (select 1 as C from Pass2 as A, Pass2 as B),--256 rows Pass4 as (select 1 as C from Pass3 as A, Pass3 as B),--65536 rows Pass5 as (select 1 as C from Pass4 as A, Pass4 as B),--4,294,967,296 rows Tally as (select row_number() over(order by C) as Number from Pass5) INSERT dbo.Numbers1 (NumberID) select TOP(100000) Number from Tally;
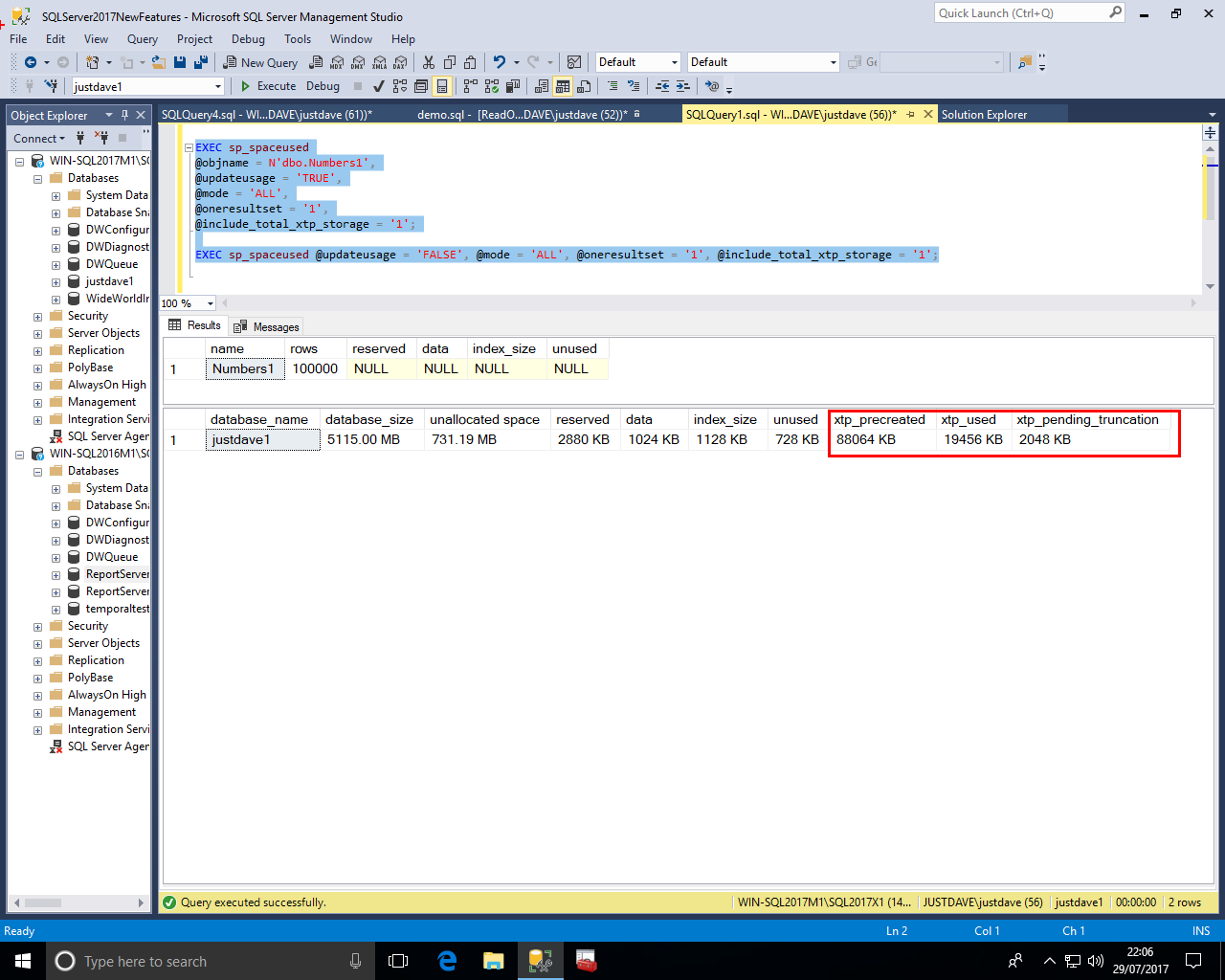
We run sp_spaceused
EXEC sp_spaceused @objname = N'dbo.Numbers1', @updateusage = 'TRUE', @mode = 'ALL', @oneresultset = '1', @include_total_xtp_storage = '1'; EXEC sp_spaceused @updateusage = 'FALSE', @mode = 'ALL', @oneresultset = '1', @include_total_xtp_storage = '1';
We first setup a database justdave1 with In-Memory support and then create a memory optimized table Numbers1
CREATE DATABASE justdave1; ALTER DATABASE justdave1 ADD FILEGROUP justdave1 CONTAINS MEMORY_OPTIMIZED_DATA; ALTER DATABASE justdave1 ADD FILE (name='justdave1_1', filename='C:\DATA\justdave1_1') TO FILEGROUP justdave1; USE justdave1; DROP TABLE IF EXISTS dbo.Numbers1; CREATE TABLE dbo.Numbers1 ( NumberID int NOT NULL PRIMARY KEY NONCLUSTERED, Quantity INT ) WITH (MEMORY_OPTIMIZED=ON);
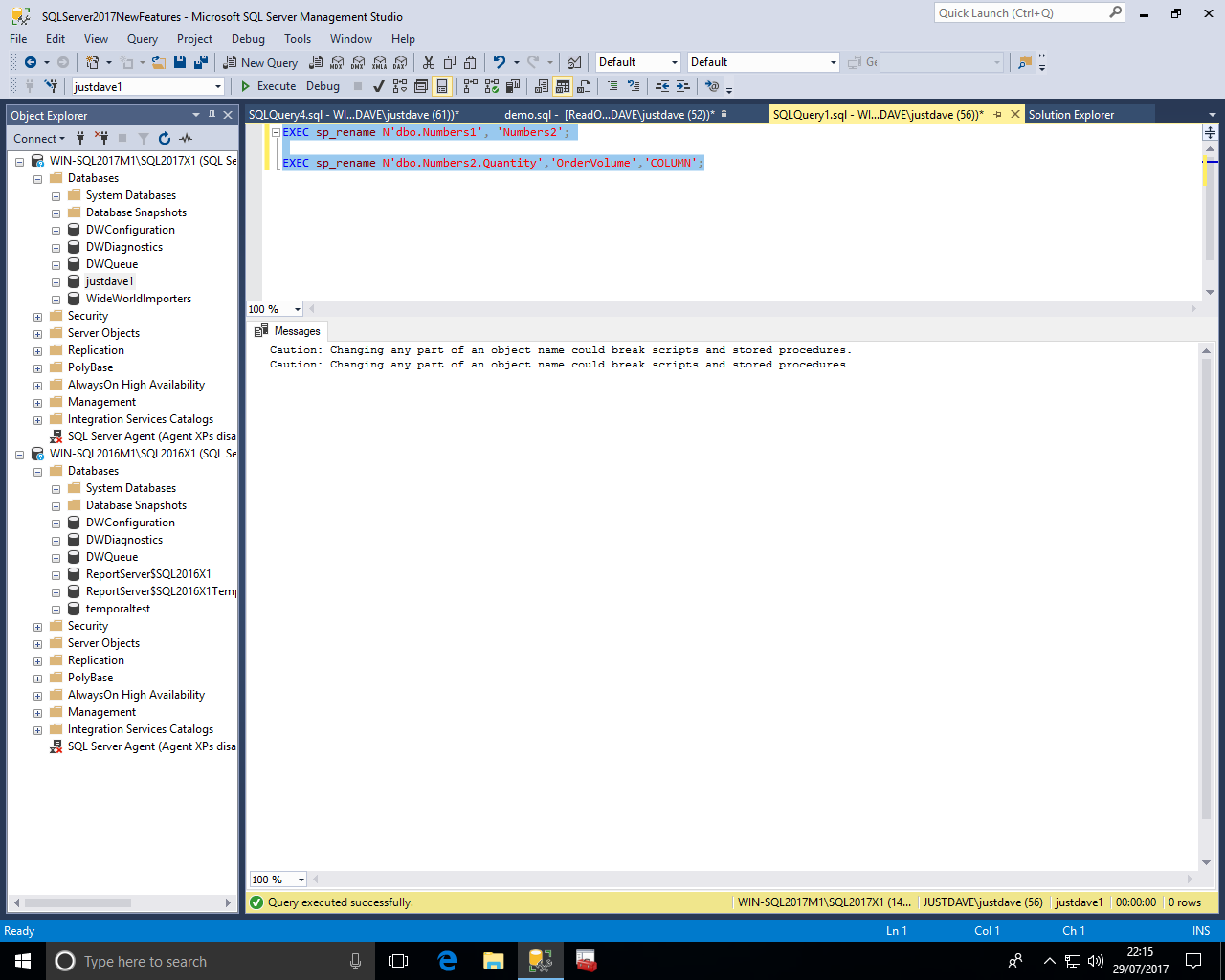
We then rename the table and then rename the column Quantity to OrderVolume
The limit of 8 indexes on a memory optimized table has been removed
ALTER TABLE against memory-optimized tables is now substantially faster in most cases.
Transaction log redo of memory-optimized tables is now done in parallel.
This can improve recovery times and Always On Availability Group throughput
Performance of bwtree (non-clustered) index rebuild for MEMORY_OPTIMIZED tables during database recovery has been significantly optimized
Optimized JSON features for In-memory processing coverL
Books Online already has a good example
Memory-optimized filegroup files can now be stored on Azure Storage.
Backup/Restore of memory-optimized files on Azure Storage is also available now.
SQL Server 2016 Query Store already has the ability to display query plan regressions and force a known good plan.
SQL Server 2017 add the ability to automatically detect plan regressions and use the LAST KNOWN GOOD plan!
This is via:
ALTER DATABASE current SET AUTOMATIC_TUNING ( FORCE_LAST_GOOD_PLAN = ON);
There is already an example from Microsoft on Github at Forcing last good plan
This is an associated new DMV sys.dm_db_tuning_recommendations
NOTE: The state changes for the tuning recommendation Active->Verifying->Success or Reverted or Expired
NOTE: We ideally want the tuning recommendation to be in the "Success" State not the "Active" state
This has several requirements
We when run the demo
In step 4 we get the tuning recommendation, the server was see the execution time for the query went from 2.4ms to 45.02ms, not something a human would notice!
We even get the script to manually force the plan.
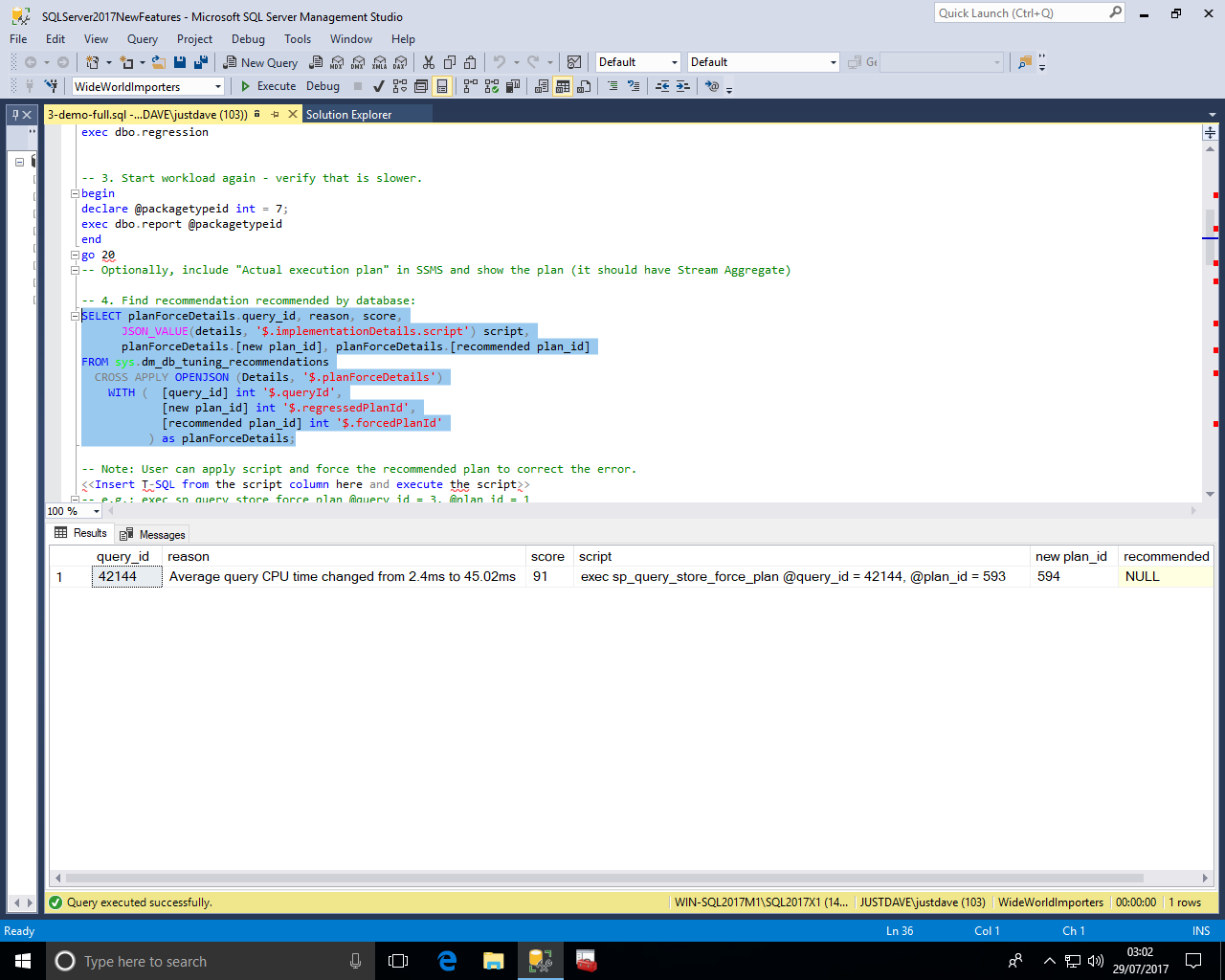
We then turn on automatic tuning and confirm automatic tuning is enabled
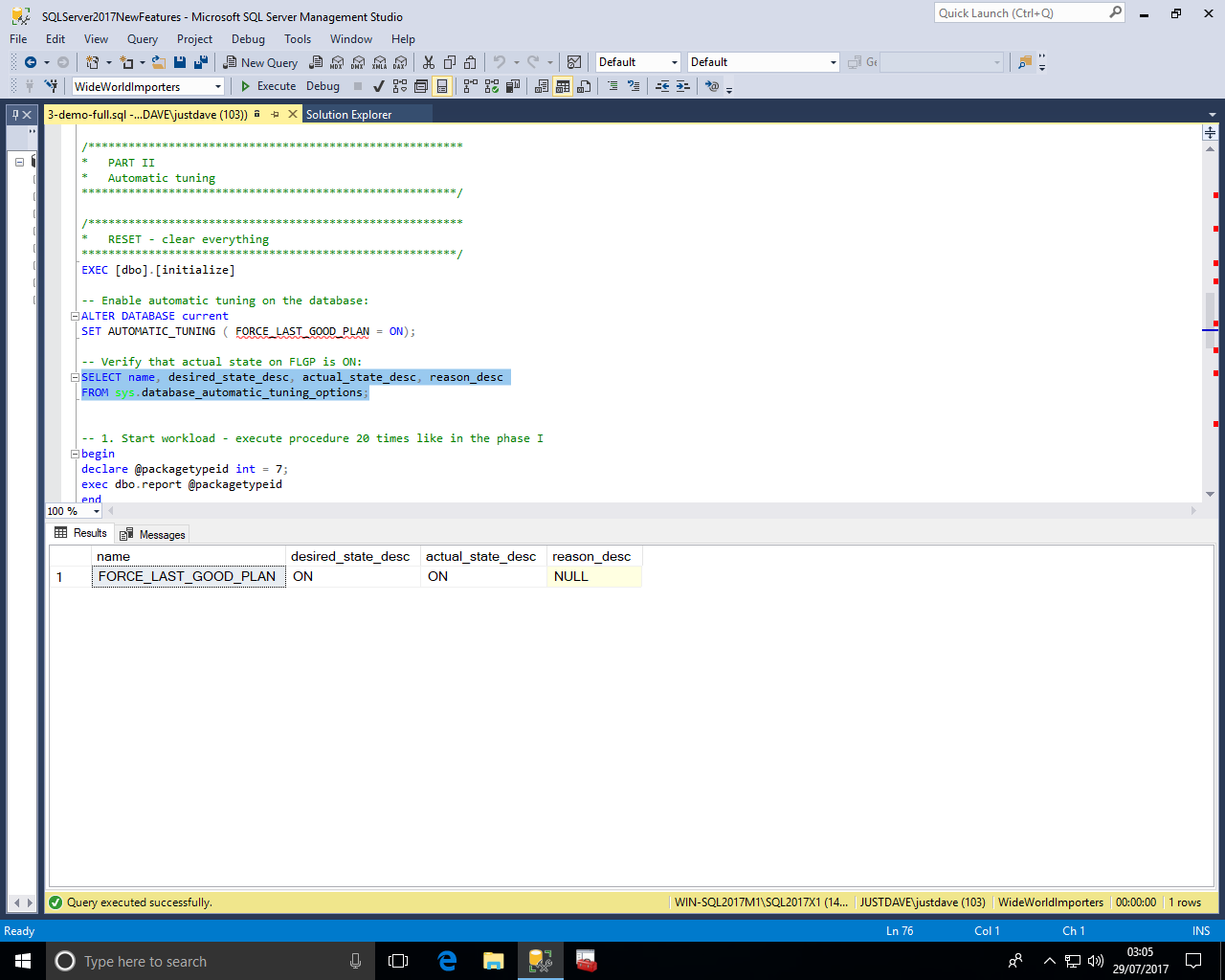
We get to step 4 again and this time see the tuning recommendation is in a "Verifying" state and the reason is "LastGoodPlanForced"!
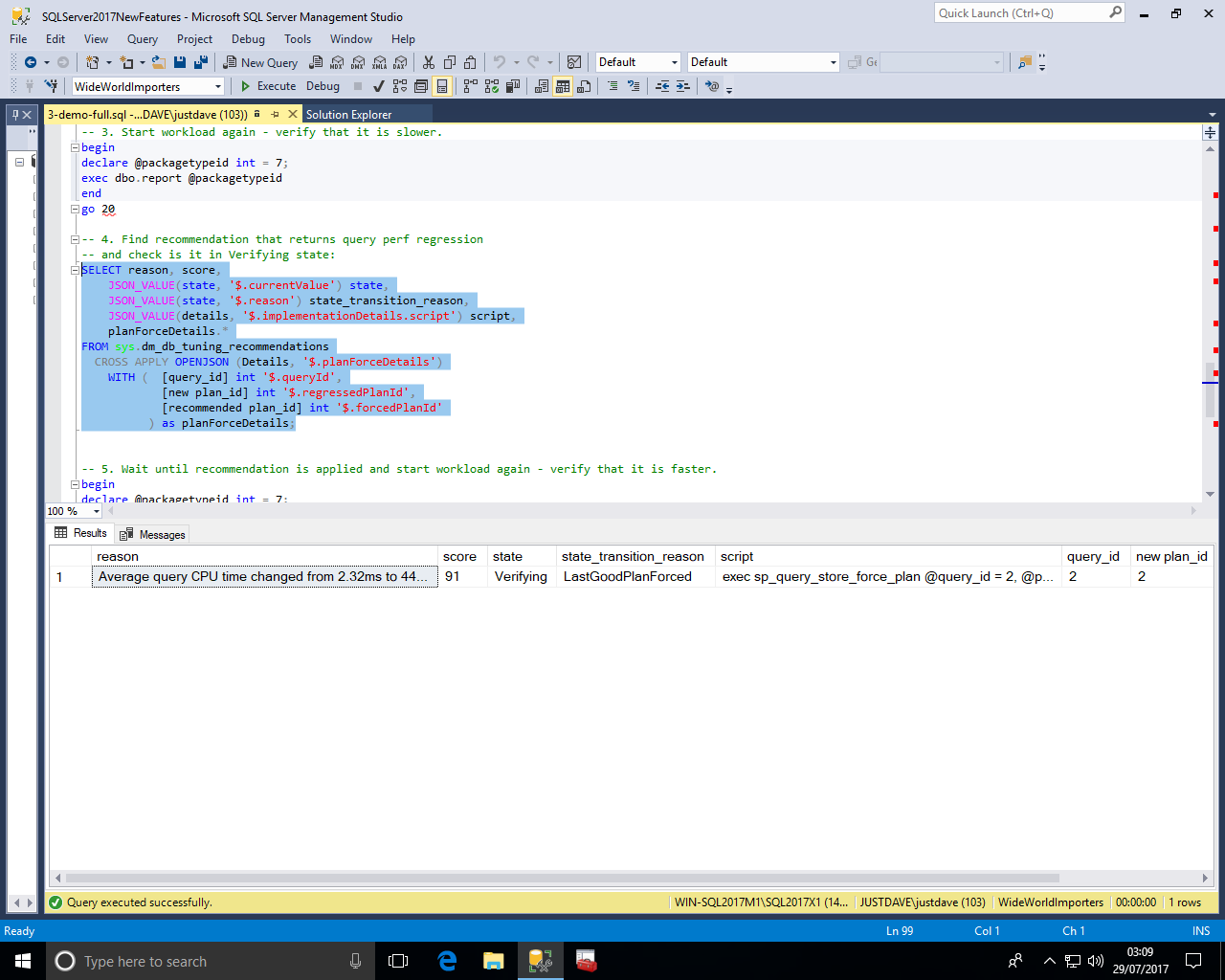
We run the workload again 20 times and then recheck the tuning recommendation which has moved to the "Success" state"
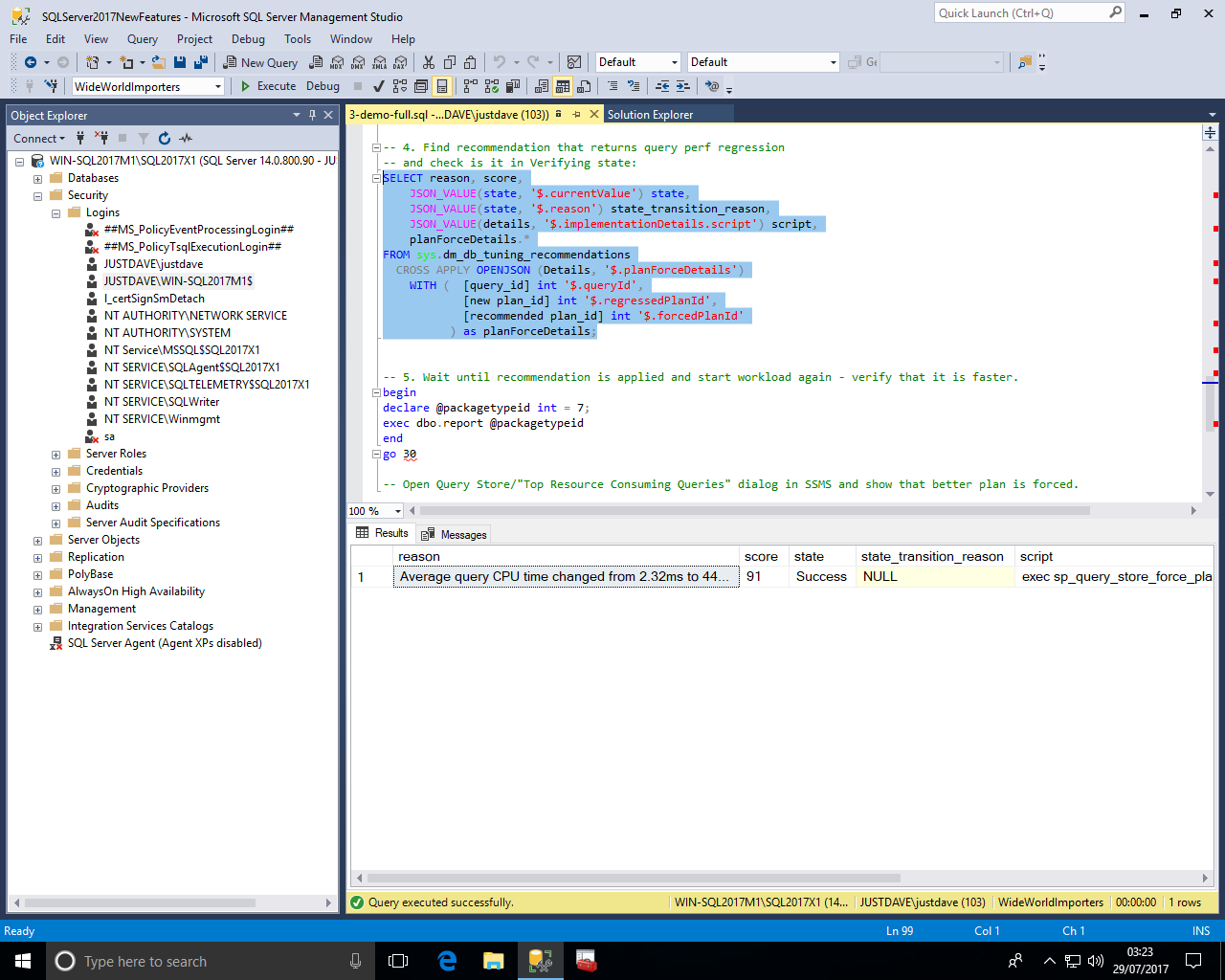
We then check the Query Store under "Top Resource Consuming Queries" and see that the better plan has now been automatically forced!
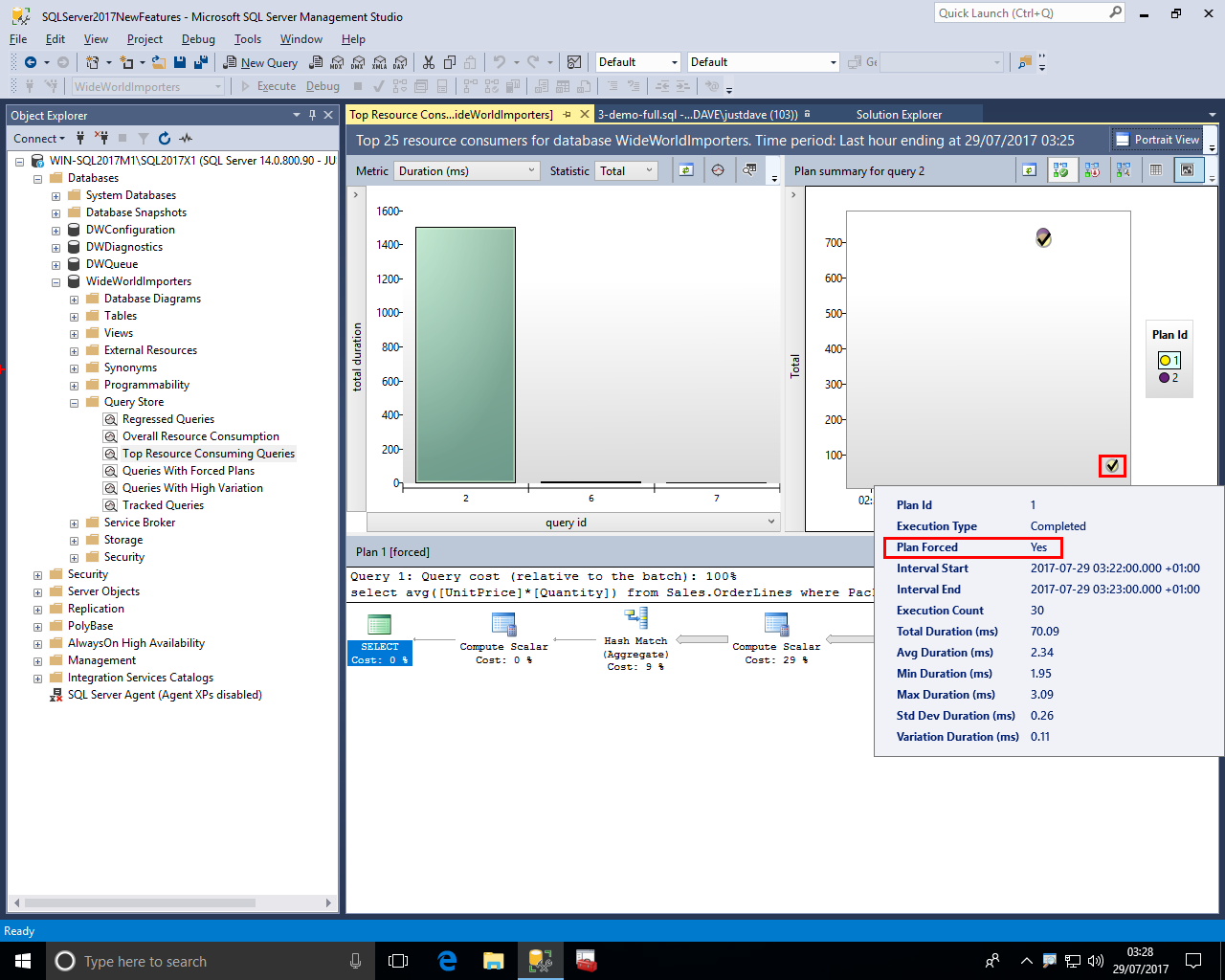
Query Store now includes a new option WAIT_STATS_CAPTURE_MODE which defaults to ON and there is a new DMV sys.query_store_wait_stats
CREATE DATABASE justdave1; ALTER DATABASE justdave1 SET QUERY_STORE = ON; ALTER DATABASE justdave1 SET QUERY_STORE (WAIT_STATS_CAPTURE_MODE = ON); -- Currently gives "Incorrect syntax near WAIT_STATS_CAPTURE_MODE."
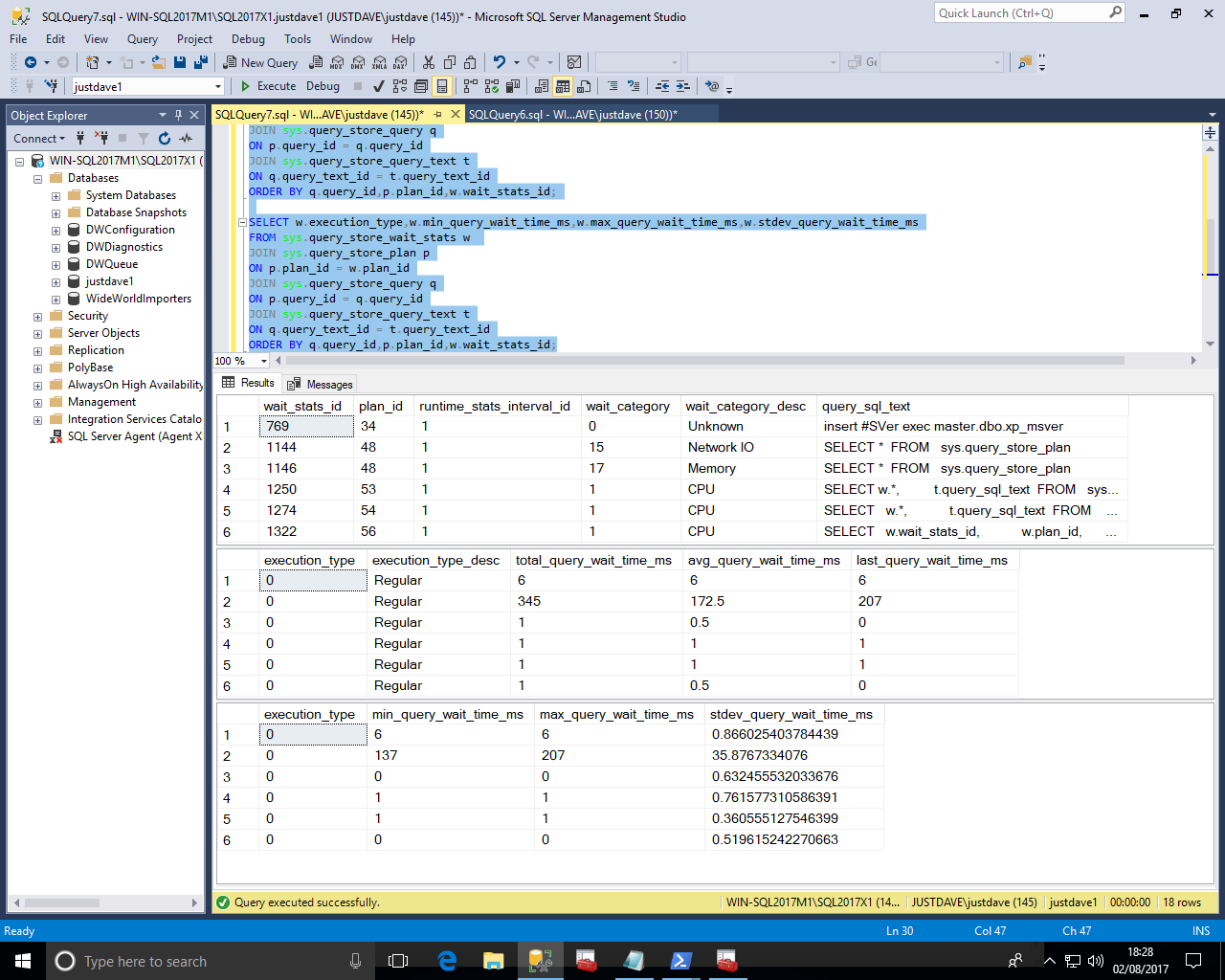
We then run queries against sys.query_store_wait_stats
SELECT w.wait_stats_id,w.plan_id,w.runtime_stats_interval_id,w.wait_category,w.wait_category_desc,t.query_sql_text FROM sys.query_store_wait_stats w JOIN sys.query_store_plan p ON p.plan_id = w.plan_id JOIN sys.query_store_query q ON p.query_id = q.query_id JOIN sys.query_store_query_text t ON q.query_text_id = t.query_text_id ORDER BY q.query_id,p.plan_id,w.wait_stats_id; SELECT w.execution_type,w.execution_type_desc,w.total_query_wait_time_ms,w.avg_query_wait_time_ms,w.last_query_wait_time_ms FROM sys.query_store_wait_stats w JOIN sys.query_store_plan p ON p.plan_id = w.plan_id JOIN sys.query_store_query q ON p.query_id = q.query_id JOIN sys.query_store_query_text t ON q.query_text_id = t.query_text_id ORDER BY q.query_id,p.plan_id,w.wait_stats_id; SELECT w.execution_type,w.min_query_wait_time_ms,w.max_query_wait_time_ms,w.stdev_query_wait_time_ms FROM sys.query_store_wait_stats w JOIN sys.query_store_plan p ON p.plan_id = w.plan_id JOIN sys.query_store_query q ON p.query_id = q.query_id JOIN sys.query_store_query_text t ON q.query_text_id = t.query_text_id ORDER BY q.query_id,p.plan_id,w.wait_stats_id;
Online Index Builds are now resumable which can be useful in the case of failure e.g. due to an Always On Availability Group Failover or lack of disk space.
Online index rebuilds can also be paused and resumed.
Resumable online index rebuild does not require significant log space, which allows you to perform log truncation while the resumable rebuild operation is running
We first create a numbers table called Numbers1 with 15,000,000 rows and a clustered index
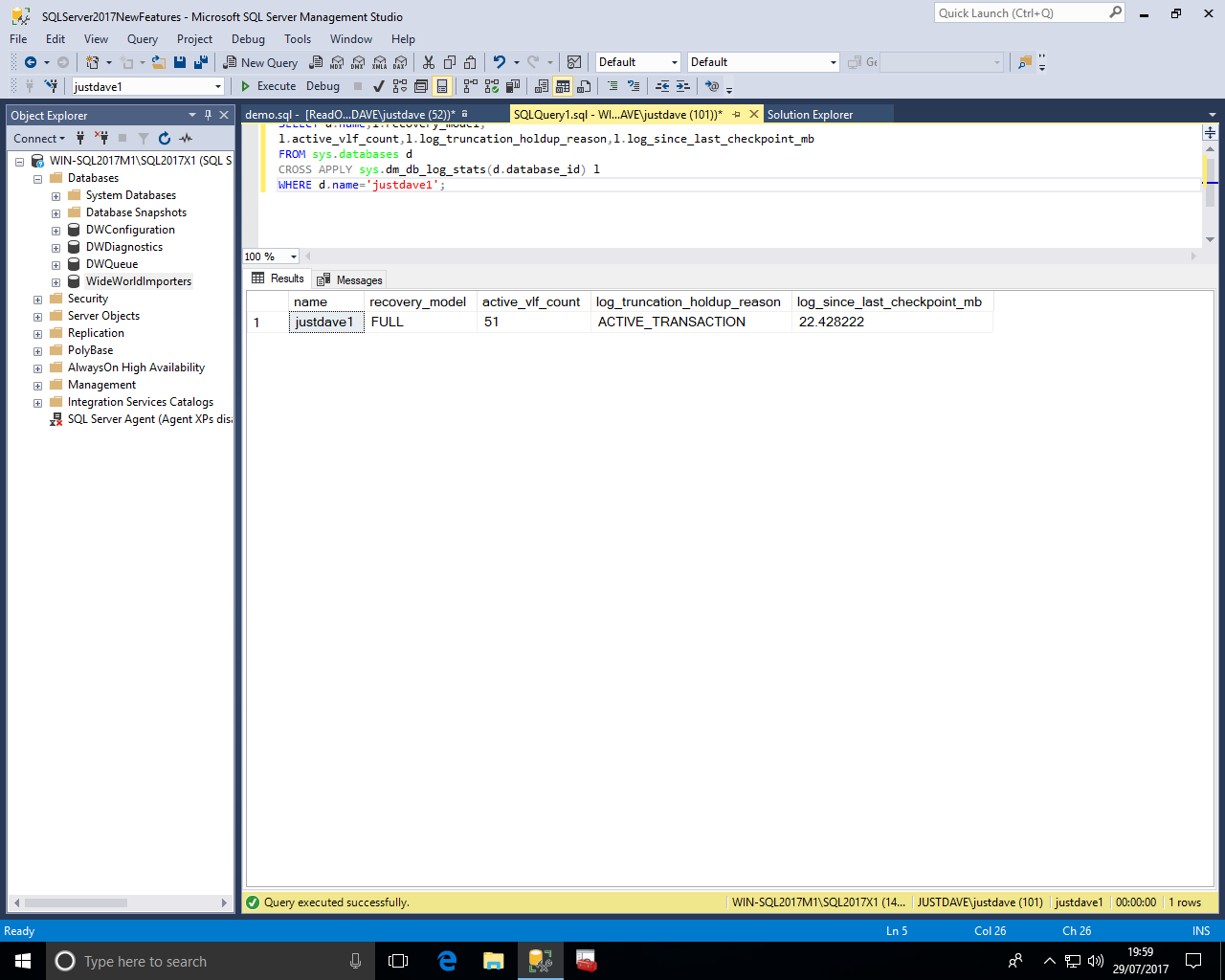
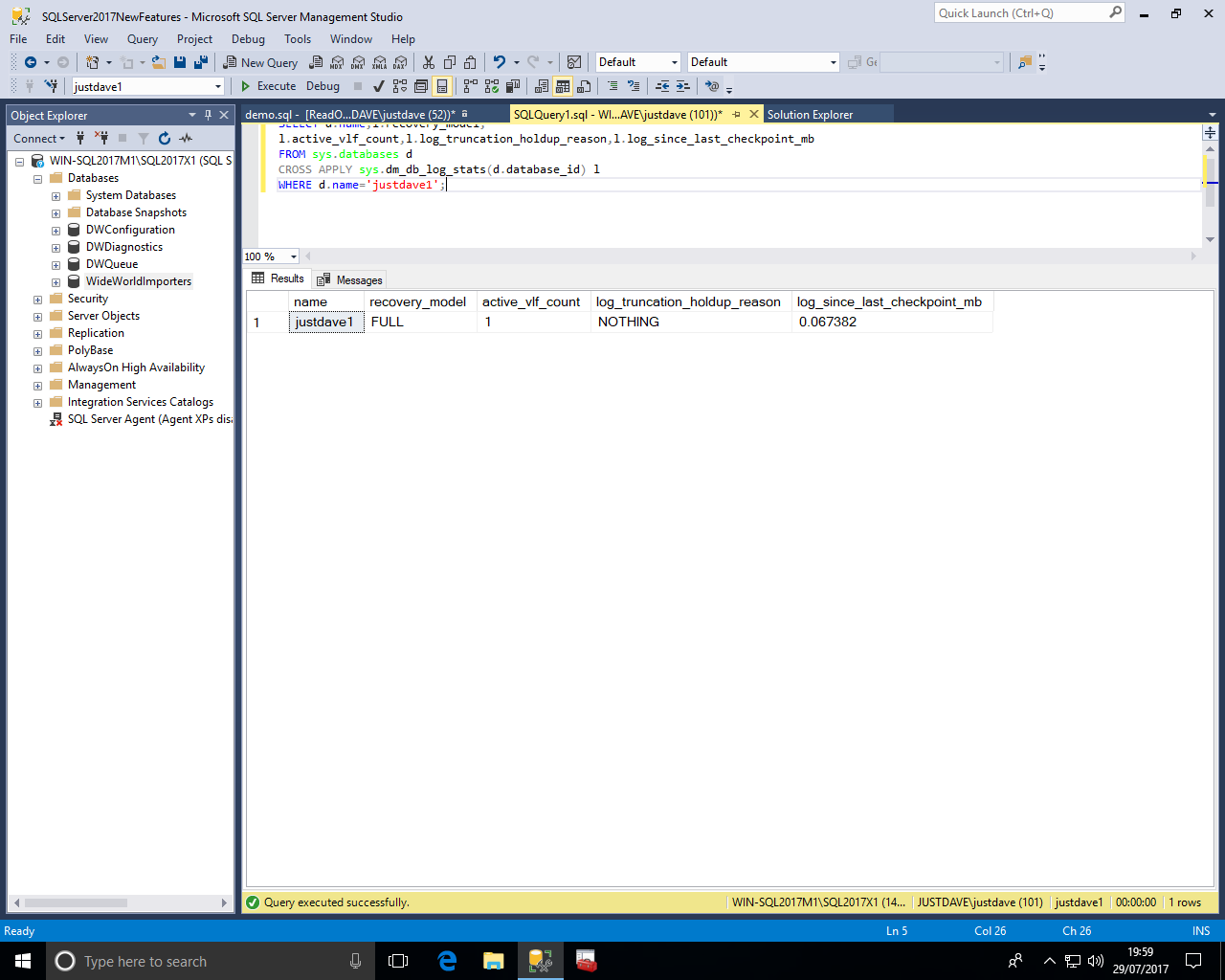
This is a new database and defaults to the SIMPLE recovery model, we checkpoint to allow the log to be cleared
CREATE DATABASE justdave1; USE justdave1; DROP TABLE IF EXISTS dbo.Numbers1; CREATE TABLE dbo.Numbers1 ( NumberID int NOT NULL ); WITH Pass0 as (select 1 as C union all select 1), --2 rows Pass1 as (select 1 as C from Pass0 as A, Pass0 as B),--4 rows Pass2 as (select 1 as C from Pass1 as A, Pass1 as B),--16 rows Pass3 as (select 1 as C from Pass2 as A, Pass2 as B),--256 rows Pass4 as (select 1 as C from Pass3 as A, Pass3 as B),--65536 rows Pass5 as (select 1 as C from Pass4 as A, Pass4 as B),--4,294,967,296 rows Tally as (select row_number() over(order by C) as Number from Pass5) INSERT dbo.Numbers1 (NumberID) select TOP(15000000) Number from Tally; CREATE CLUSTERED INDEX ix_NumberID1 ON dbo.Numbers1(NumberID); SELECT d.name,l.recovery_model, l.active_vlf_count,l.log_truncation_holdup_reason,l.log_since_last_checkpoint_mb FROM sys.databases d CROSS APPLY sys.dm_db_log_stats(d.database_id) l WHERE d.name='justdave1'; CHECKPOINT; SELECT d.name,l.recovery_model, l.active_vlf_count,l.log_truncation_holdup_reason,l.log_since_last_checkpoint_mb FROM sys.databases d CROSS APPLY sys.dm_db_log_stats(d.database_id) l WHERE d.name='justdave1';
Before the checkpoint we see
After the checkpoint we see
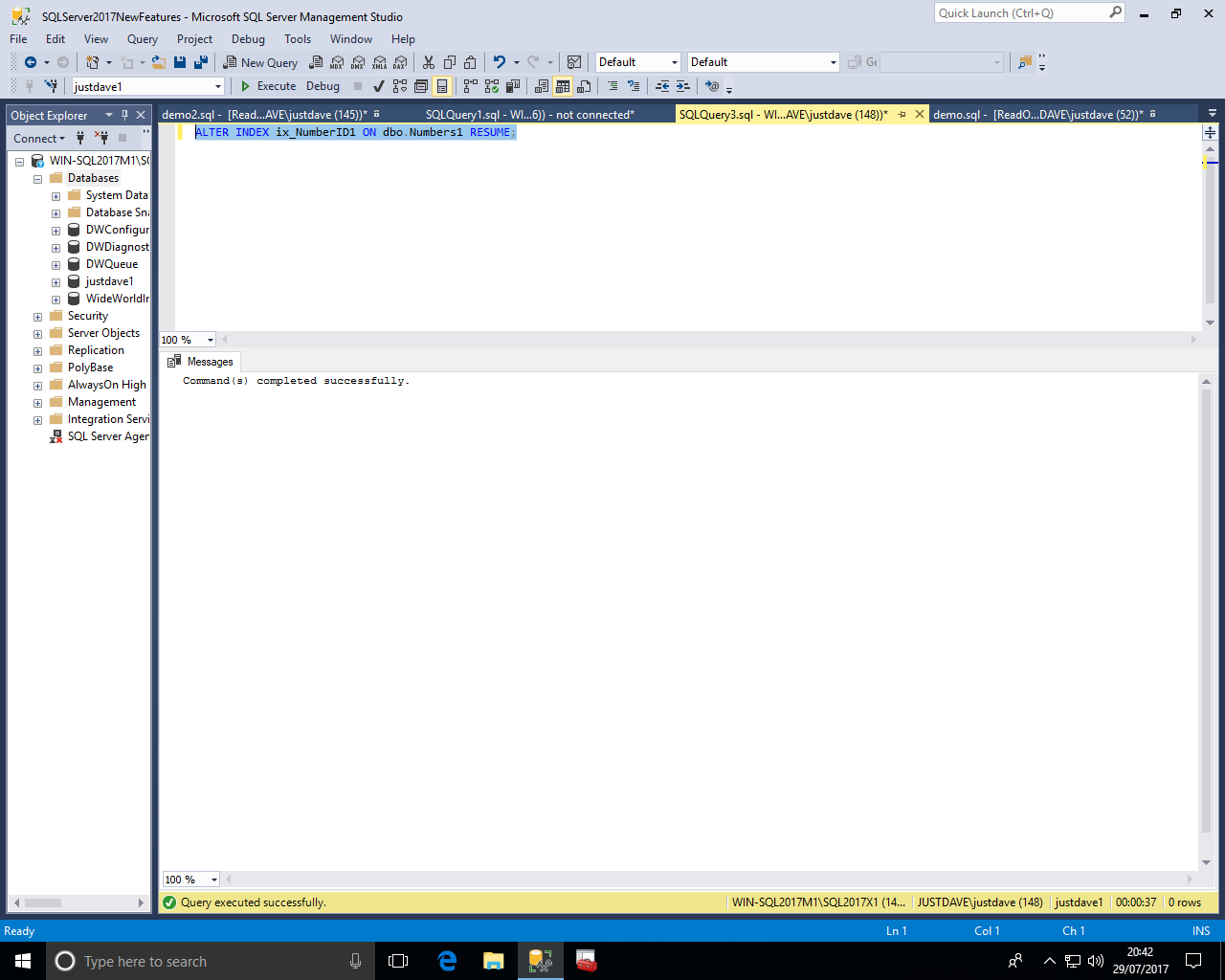
We run a resumeable index rebuild with new option "RESUMABLE=ON".
To be resumeable this must be an online index rebuild
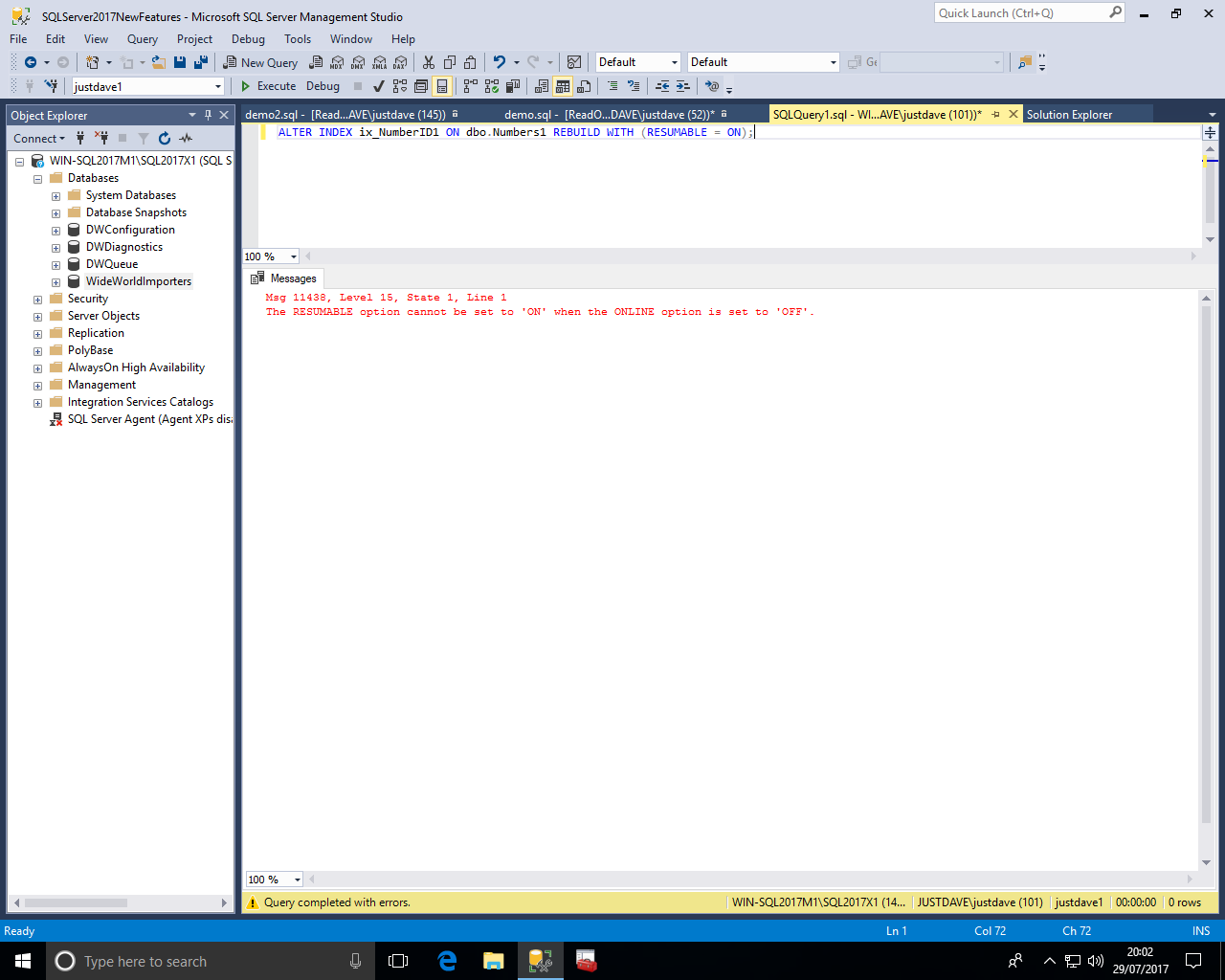
We pause online index rebuilds with a new PAUSE keyword, if we try to pause when no resumable operations are occuring we get an error
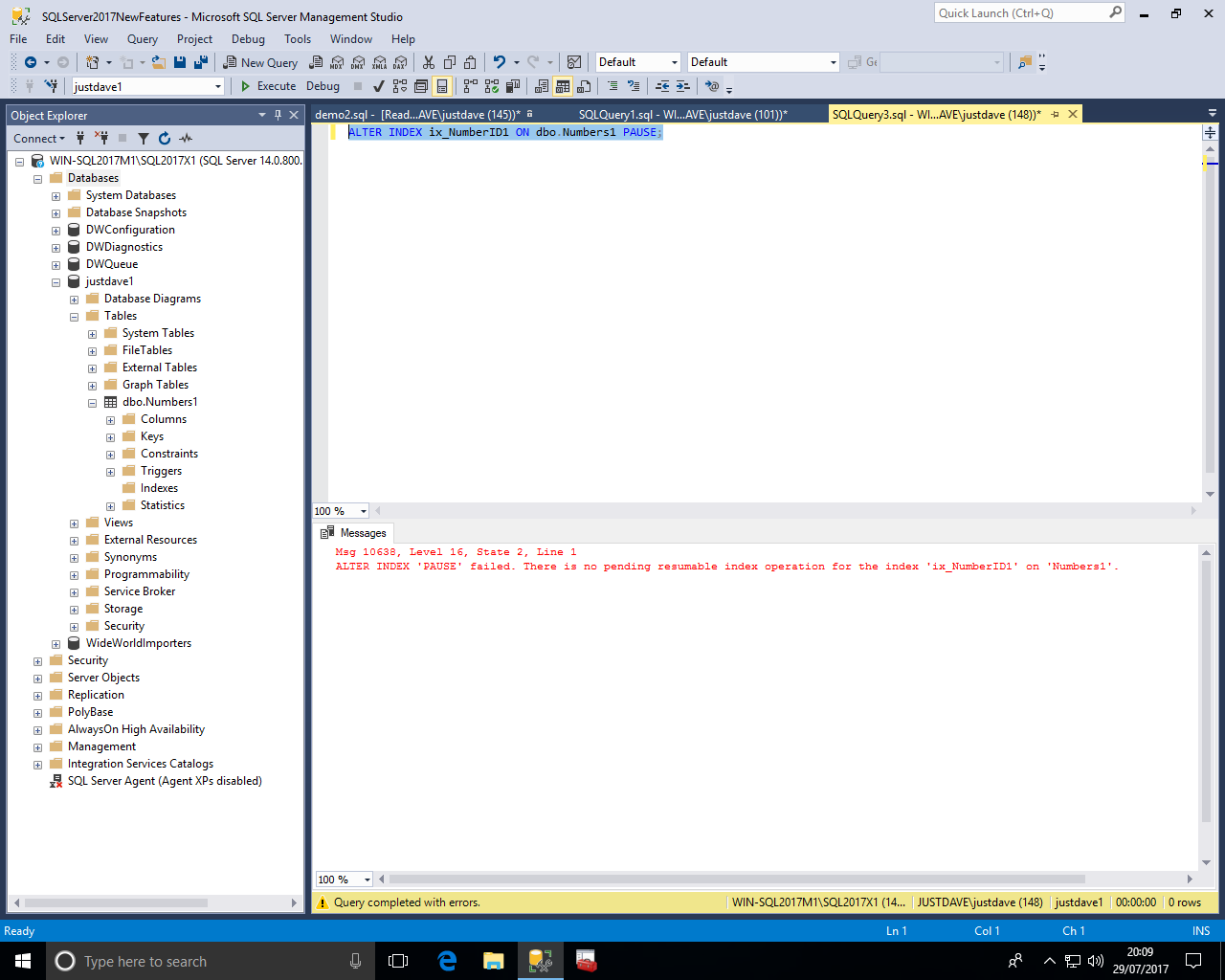
We execute the online index rebuild and pause the operation
The connection with the paused operation received a sever error and is actually disconnected!
The connection which execute the pause operation receives a successful result with no error"
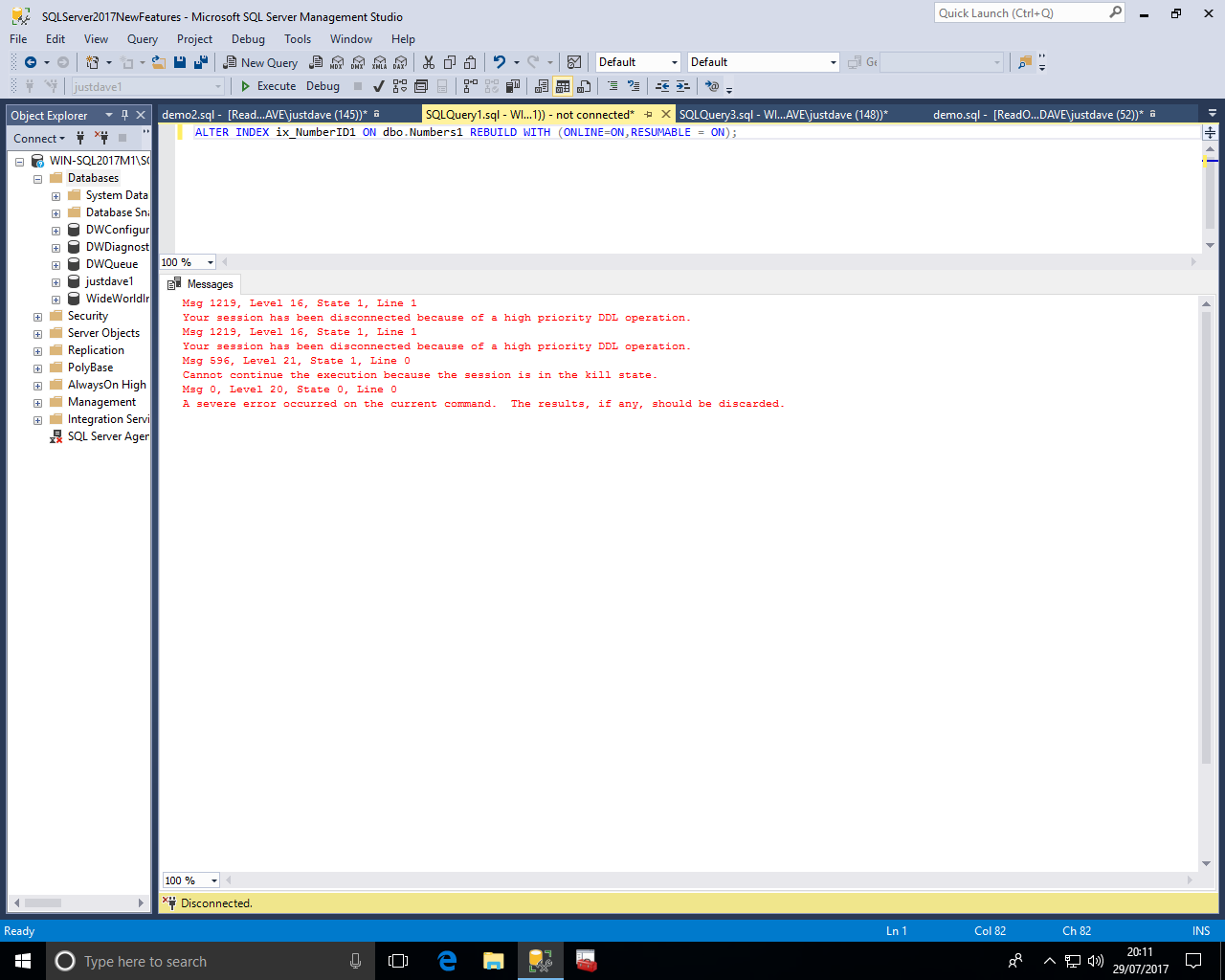
NOTE: The error received by the pause operation is similar to the SQL Server 2014 feature with for online index rebuilds with WAIT_AT_LOW_PRIORITY and ABORT_AFTER_WAIT = BLOCKERS - the session is disconnected
In the screenshot below after the delete in another sessions we run
ALTER INDEX ix_NumberID1 ON dbo.Numbers1 REBUILD WITH ( ONLINE = ON ( WAIT_AT_LOW_PRIORITY (MAX_DURATION = 0 MINUTES, ABORT_AFTER_WAIT = BLOCKERS) ) )
The commit also receives an error that the session was disconnected!
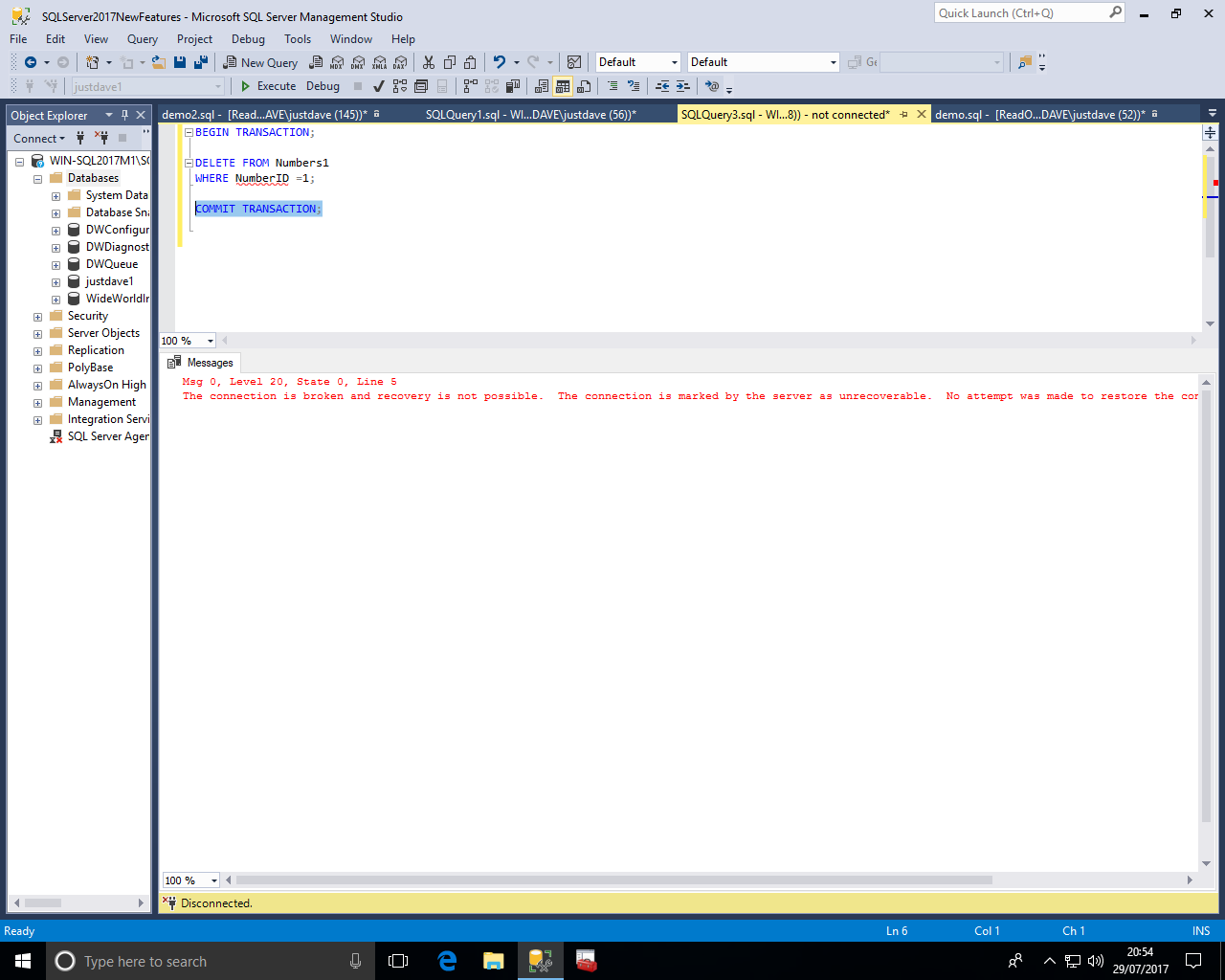
We check the log usage,checkpoint and check the log usage again
NOTE: We see the active VLF count comes down even though the online index rebuild is still paused!
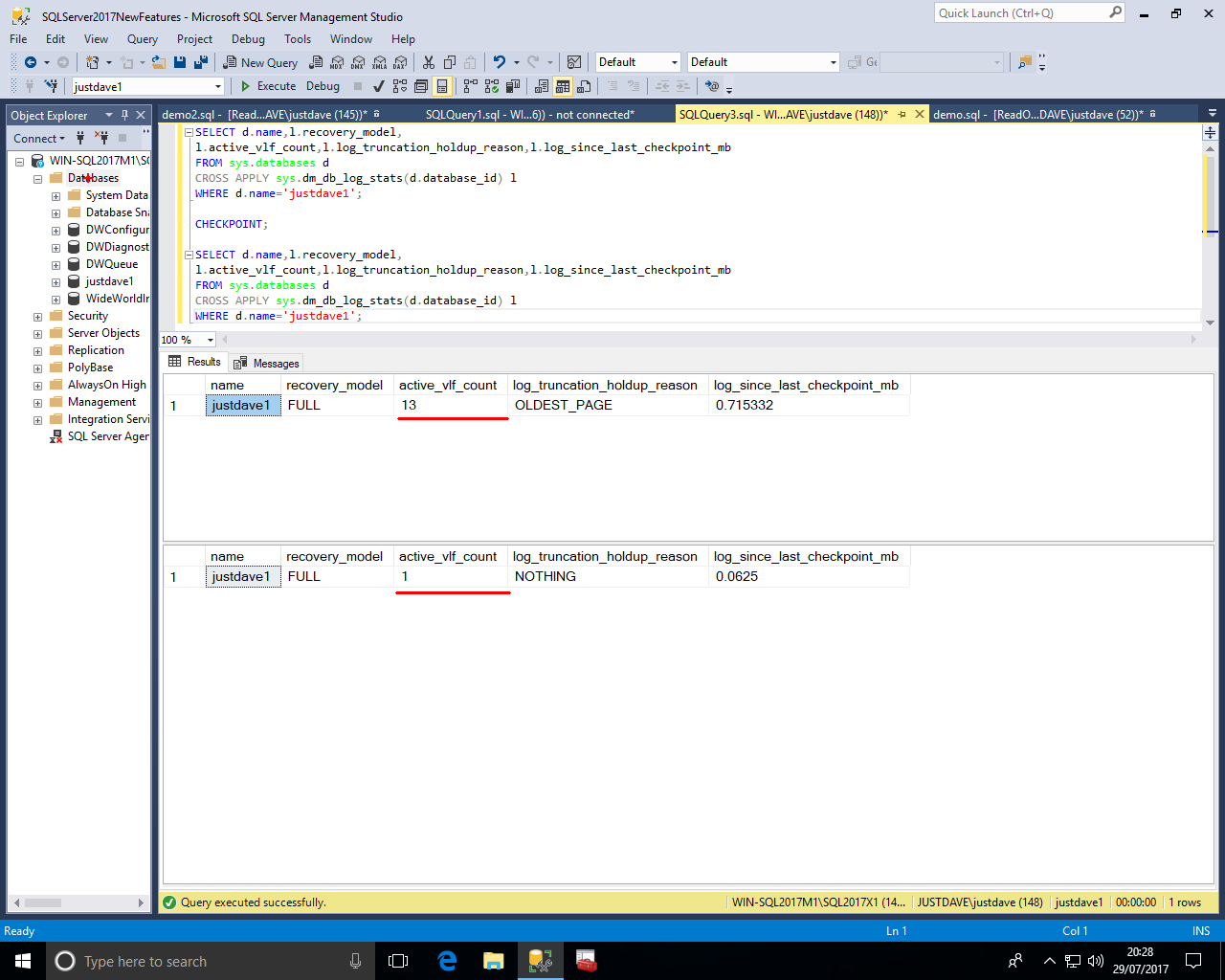
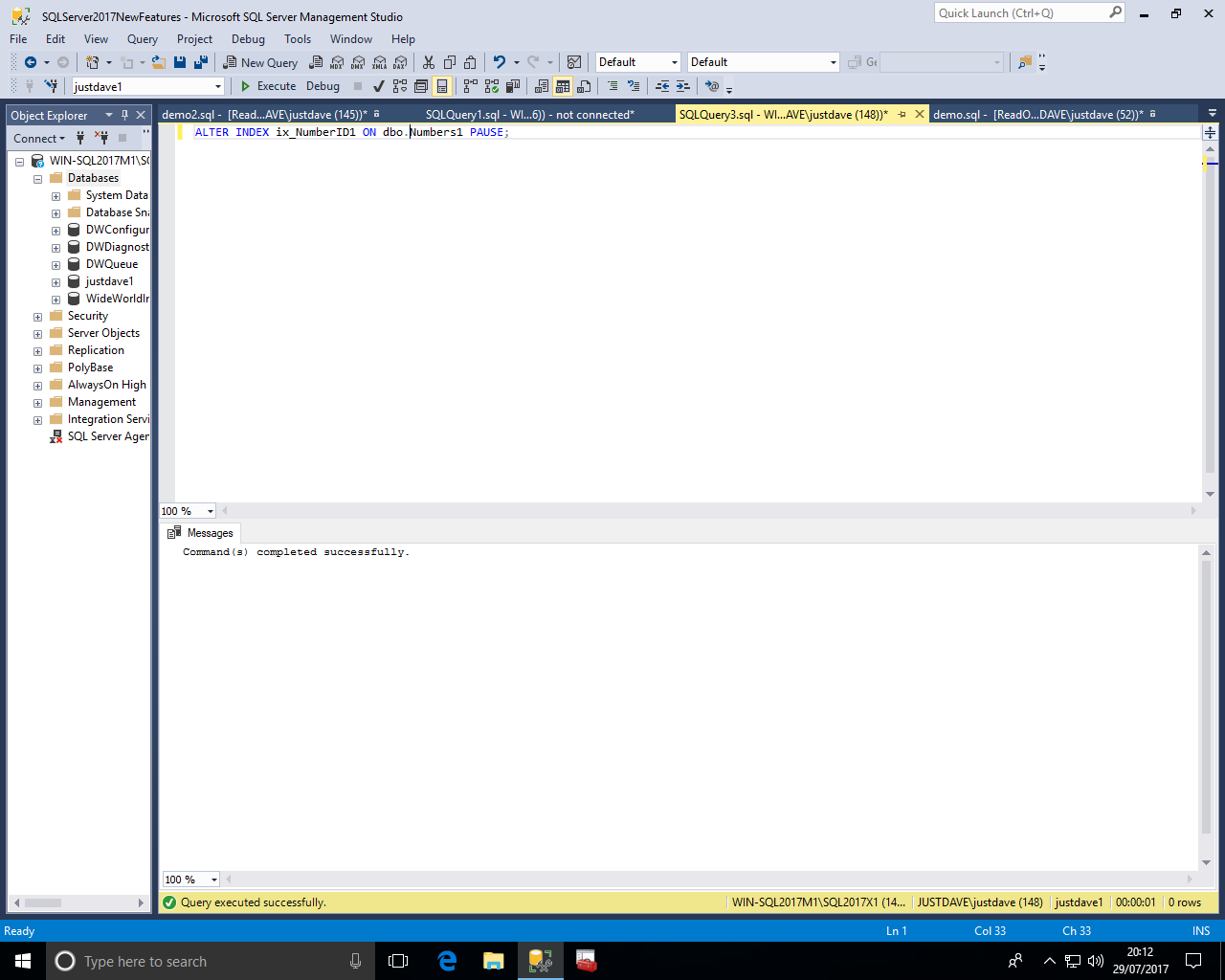
We check for the resumable online index rebuild via the new DMV sys.index_resumable_operations
We even see percentage complete and page_count which is the "Total number of index pages allocated by the index build operation for the new and mapping indexes"
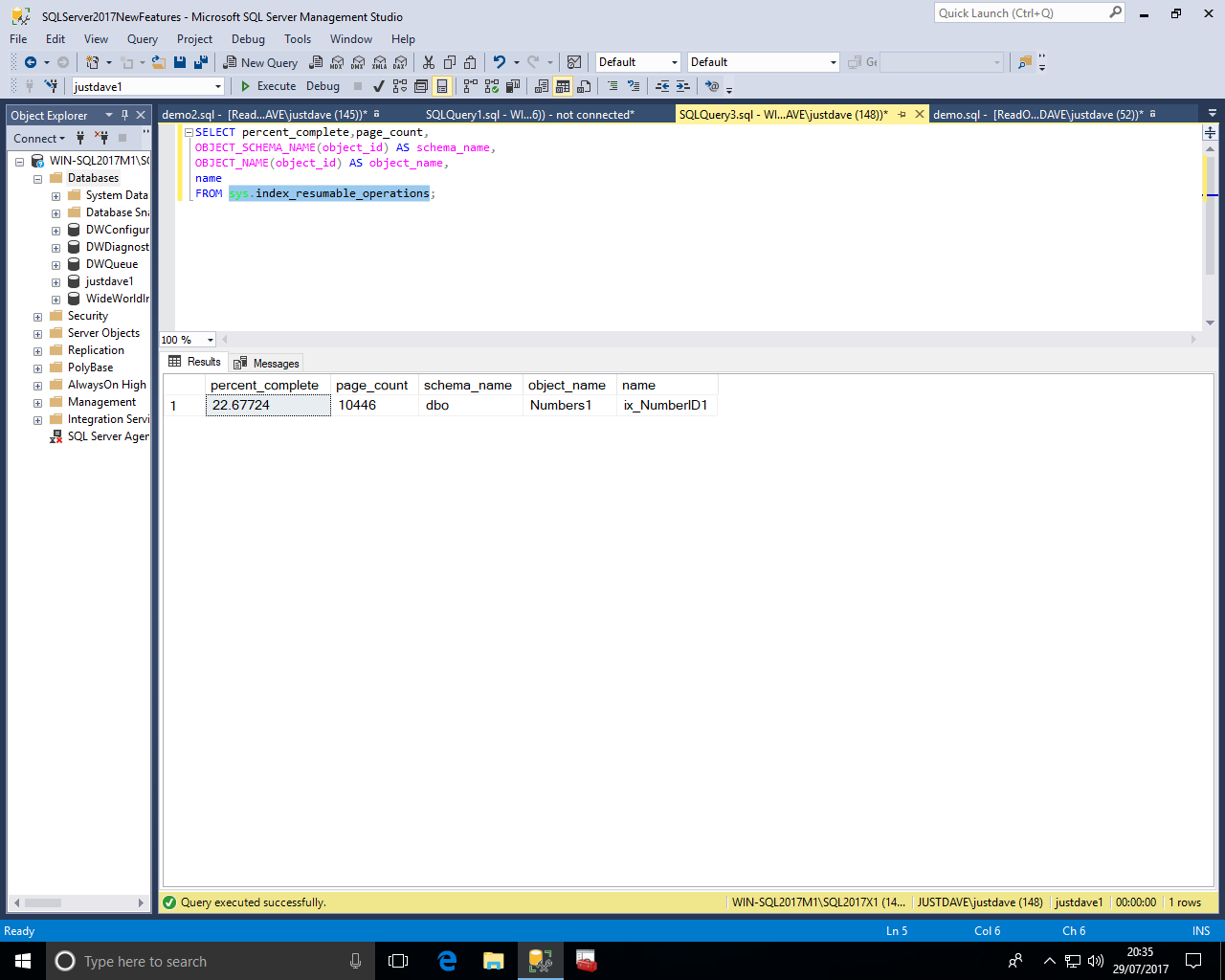
We can then resume the online index rebuild, the resume command will execute until the online index rebuild is complete
We can now directly Bulk load CSV format files e.g. for Data Scientists who love Excel 2016
First go into Excel 2016 and create a simple worksheet with no header row and 2 column
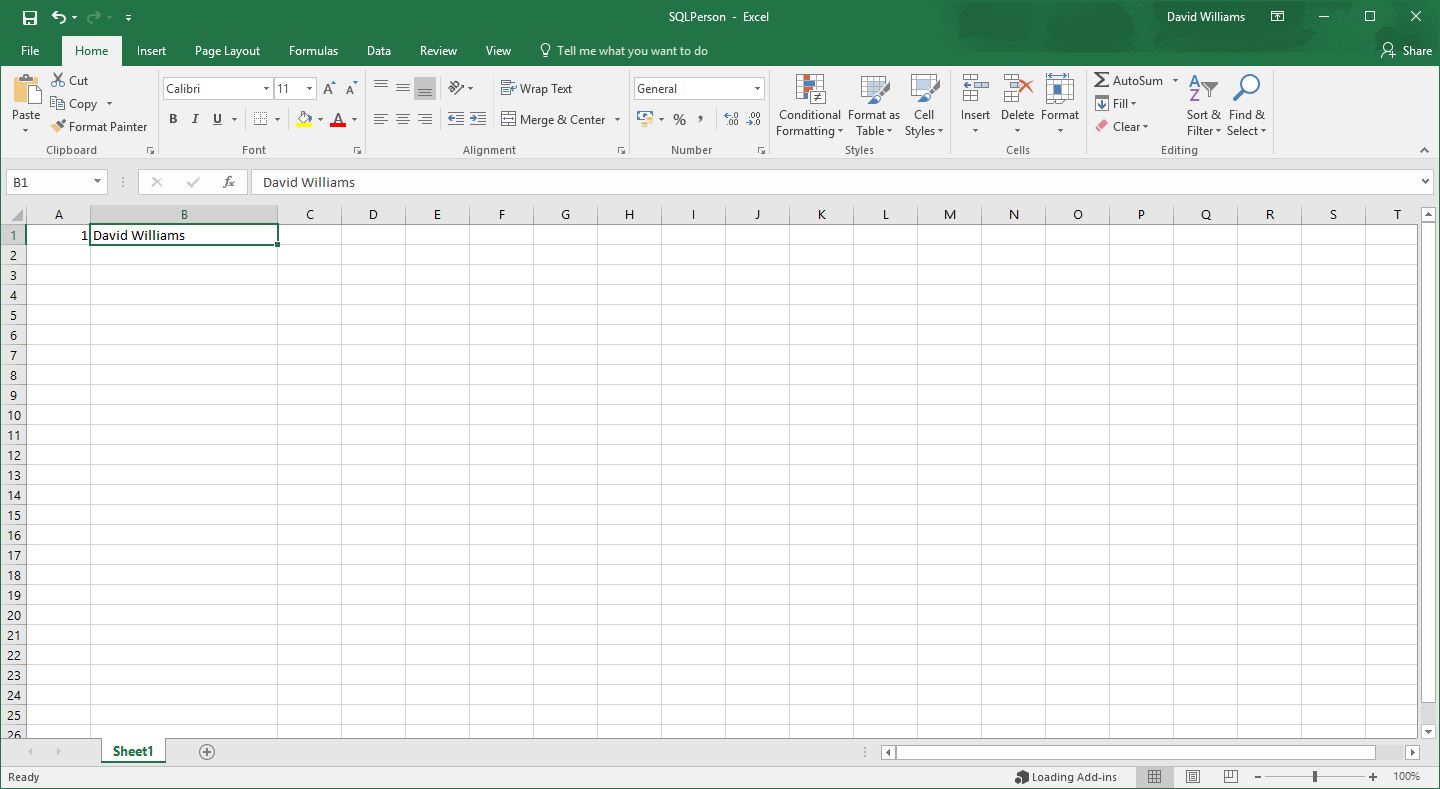
Then save as a CSV file
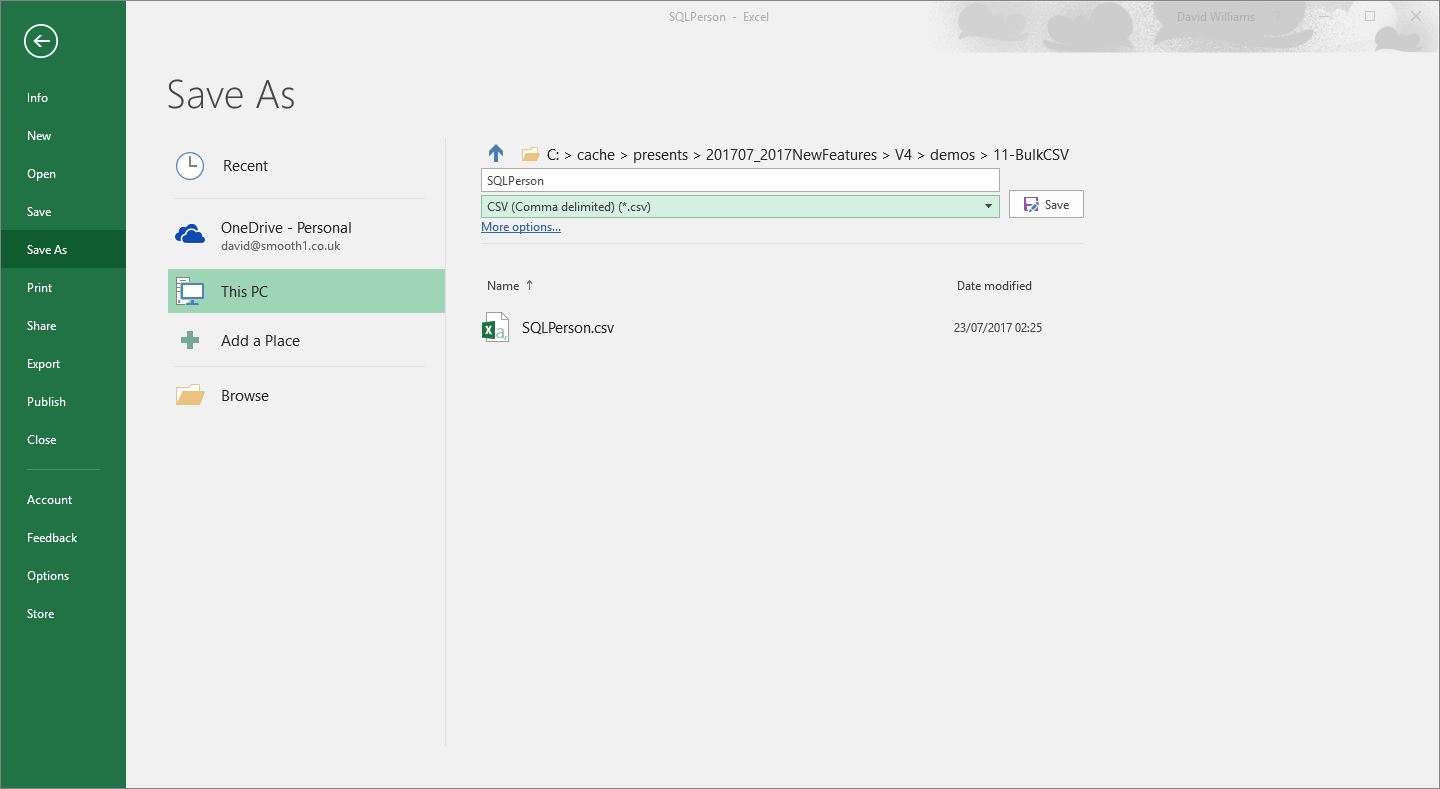
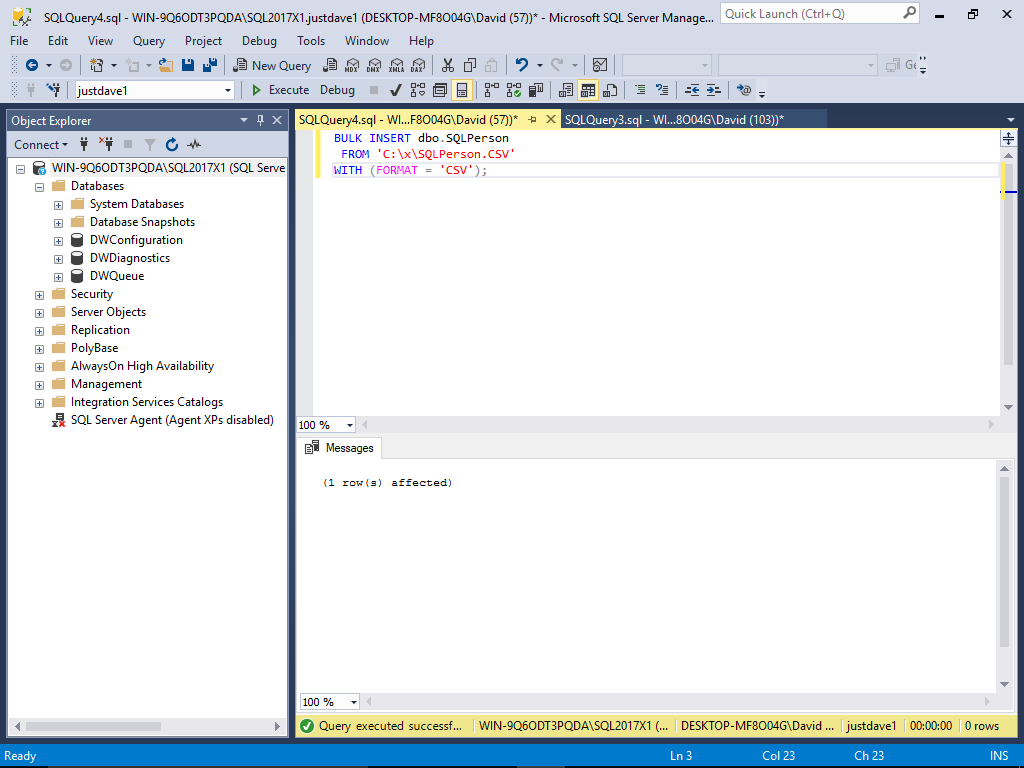
We then load the file
DROP TABLE IF EXISTS SQLPerson; CREATE TABLE SQLPerson ( [PersonID] [int] IDENTITY(1,1) NOT NULL, [PersonName] [varchar](100) NULL ); BULK INSERT dbo.SQLPerson FROM 'C:\x\SQLPerson.CSV' WITH (FORMAT = 'CSV');
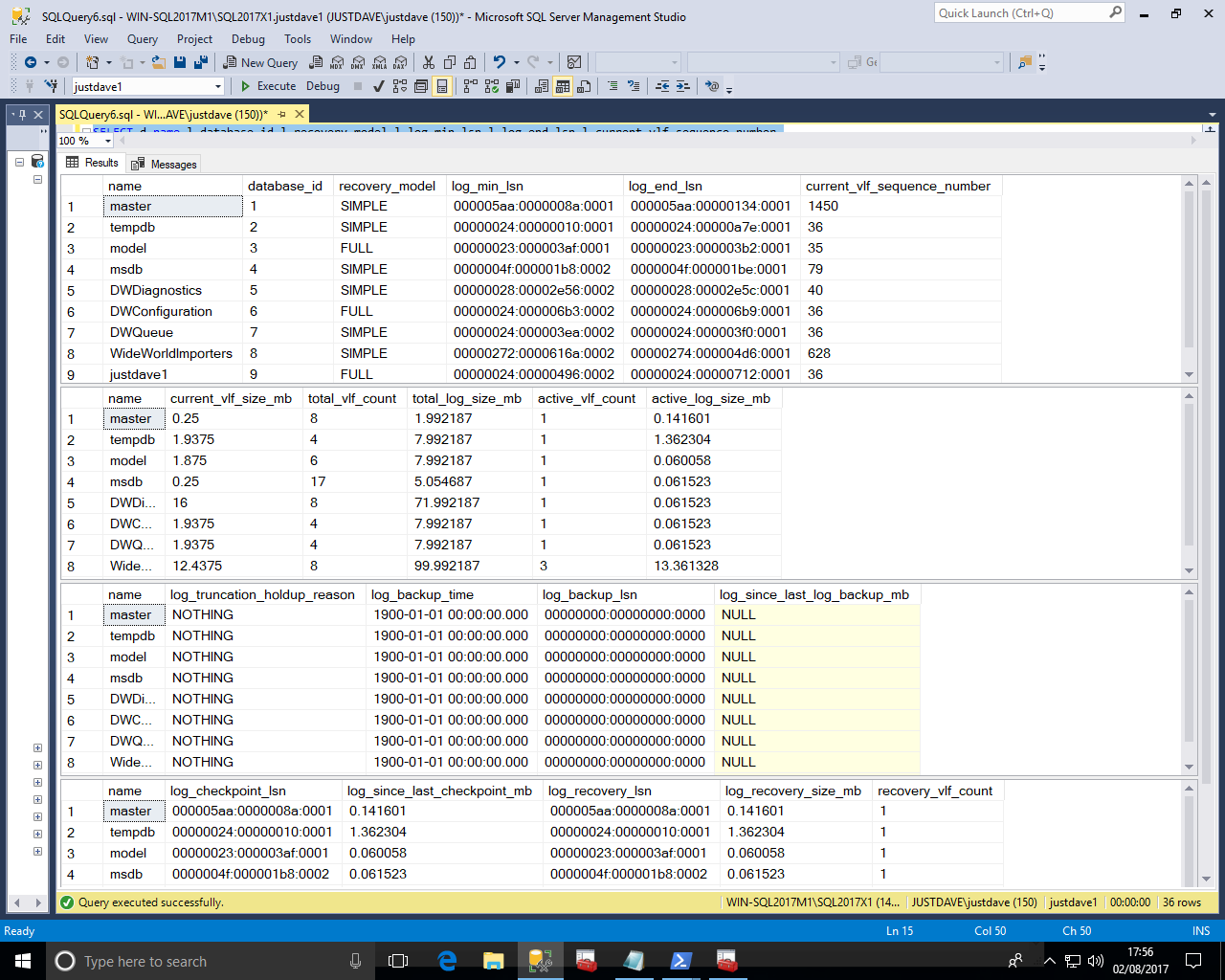
New DMF sys.dm_db_log_stats provides summary level atrribute and information for transaction logs
total_vlf_count is useful for checking for excessive VLF creation which can affect all transaction log activities including recovery,restores and transaction log backup times
Excessive VLFs issues are cover by SQLskills at 8 Steps to better Transaction Log throughputrecovery_model,log_truncation_holdup_reason,log_backup_time,log_since_last_log_backup_mb,log_since_last_checkpoint_mb are all useful to determine log growth issues and to implement a smart log backup strategy
E.g. alerting if a log backup has not been run in the last 30 minutes
SELECT d.name,l.database_id,l.recovery_model,l.log_min_lsn,l.log_end_lsn,l.current_vlf_sequence_number FROM sys.databases d CROSS APPLY sys.dm_db_log_stats(d.database_id) l; SELECT d.name,l.current_vlf_size_mb,l.total_vlf_count,l.total_log_size_mb,l.active_vlf_count,l.active_log_size_mb FROM sys.databases d CROSS APPLY sys.dm_db_log_stats(d.database_id) l; SELECT d.name,l.log_truncation_holdup_reason,l.log_backup_time,l.log_backup_lsn,l.log_since_last_log_backup_mb FROM sys.databases d CROSS APPLY sys.dm_db_log_stats(d.database_id) l; SELECT d.name,l.log_checkpoint_lsn,l.log_since_last_checkpoint_mb,log_recovery_lsn,log_recovery_size_mb,l.recovery_vlf_count FROM sys.databases d CROSS APPLY sys.dm_db_log_stats(d.database_id) l;
DMV sys.dm_os_sys_info is enhanced with new columns socket_count, cores_per_socket, numa_node_count
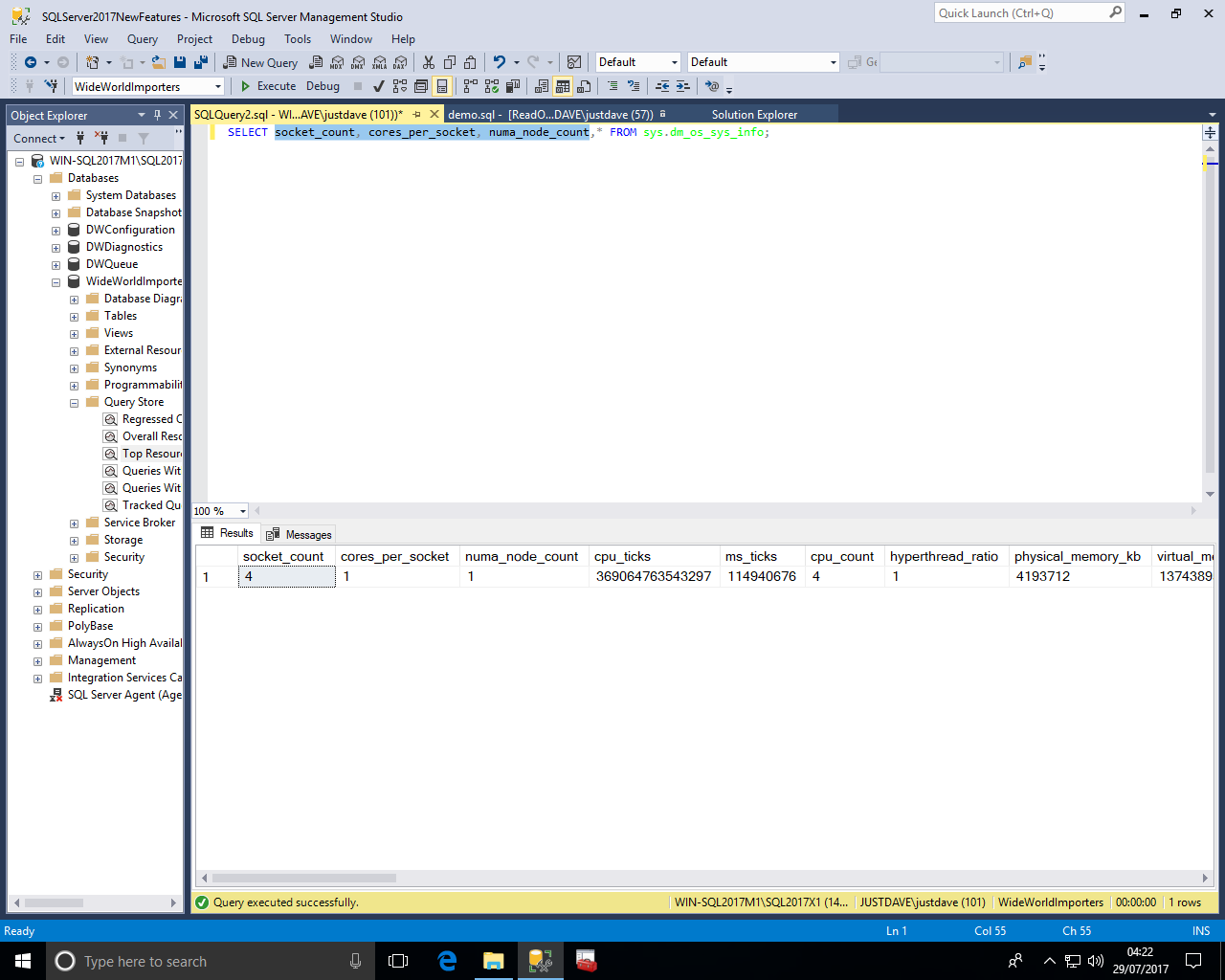
DMV sys.sys.dm_db_file_space_usage is enhanced with new column modified_extent_page_count which can be used to determine the number of modified extents since the last full backup
This can be used to implement a smart differential backup strategy e.g. if 90% of the database extent pages have been modified then run a full rather than a differential backup
NOTE: The modified_extent_page_count never drops to 0!
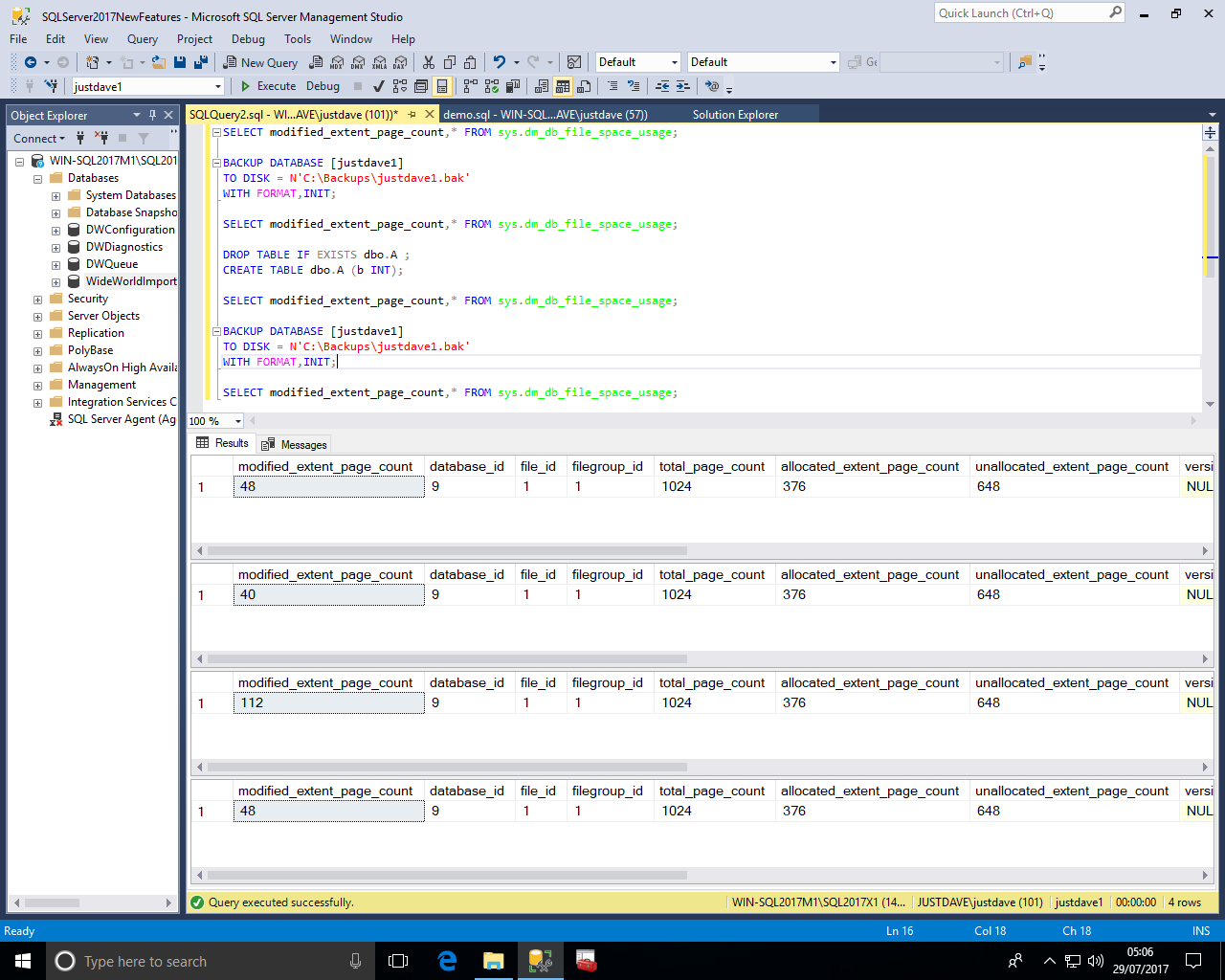
New DMF sys.dm_db_log_info provides VLF information similar to DBCC LOGINFO but via a DMO
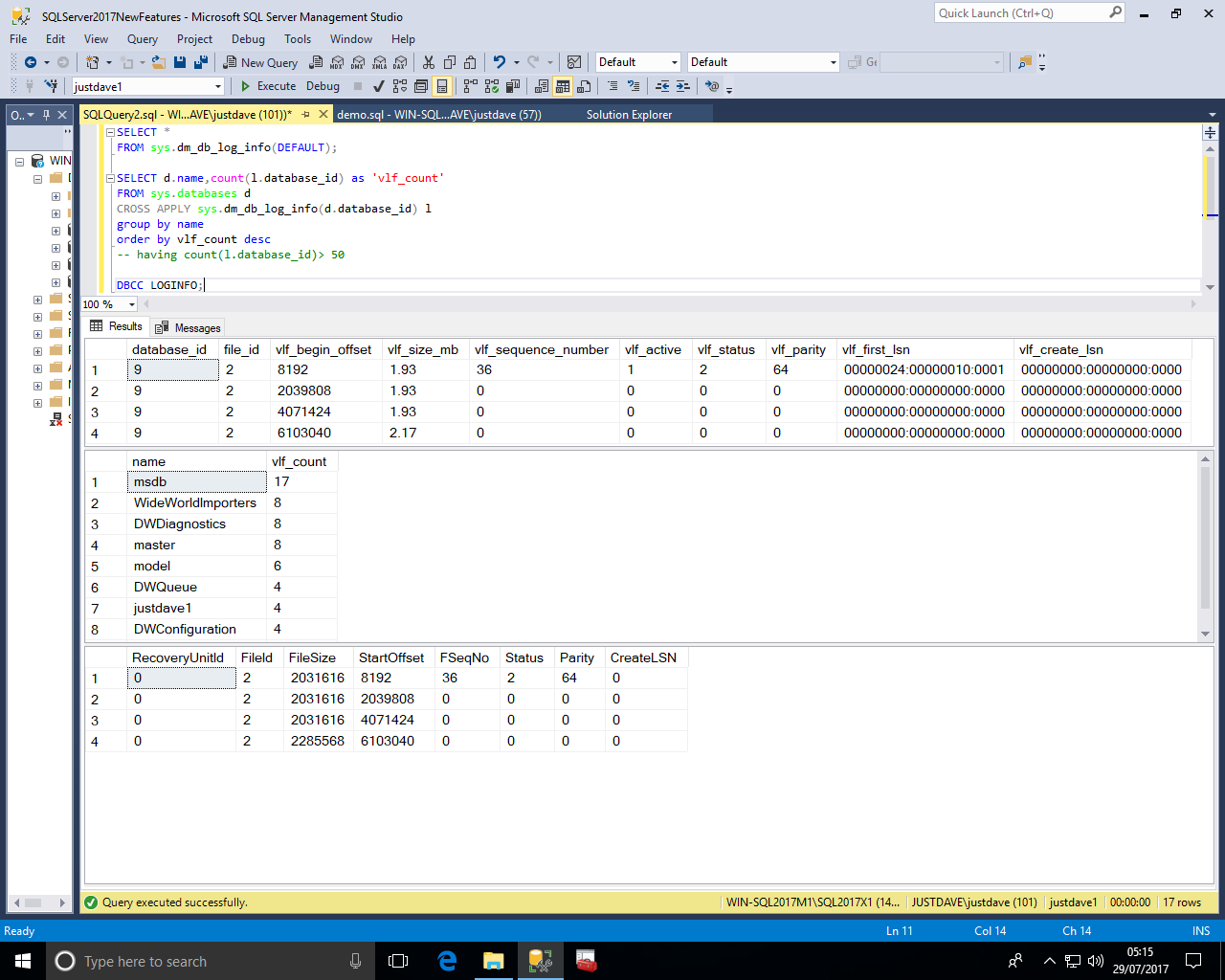
New DMV sys.dm_db_stats_histogram provides the statistics histogram for the specified database object (table or indexed view)
This is similar to DBCC SHOW_STATISTICS WITH HISTOGRAM;
We first create a numbers table with a clustered index and update statistics with fullscan:
DROP TABLE IF EXISTS dbo.Numbers1; CREATE TABLE dbo.Numbers1 ( NumberID int NOT NULL ); CREATE CLUSTERED INDEX ix_NumberID1 ON dbo.Numbers1(NumberID); WITH Pass0 as (select 1 as C union all select 1), --2 rows Pass1 as (select 1 as C from Pass0 as A, Pass0 as B),--4 rows Pass2 as (select 1 as C from Pass1 as A, Pass1 as B),--16 rows Pass3 as (select 1 as C from Pass2 as A, Pass2 as B),--256 rows Pass4 as (select 1 as C from Pass3 as A, Pass3 as B),--65536 rows Pass5 as (select 1 as C from Pass4 as A, Pass4 as B),--4,294,967,296 rows Tally as (select row_number() over(order by C) as Number from Pass5) INSERT dbo.Numbers1 (NumberID) select TOP(10000000) Number from Tally; UPDATE STATISTICS dbo.Numbers1 WITH FULLSCAN;
We can then either pass (object_id,stats_id from sys.stats) or cross apply to sys.stats
New DMV sys.dm_os_host_info is a platform independent (as SQL Server now runs on Linux) alternative to sys.dm_os_windows_info
This includes host_platform and host_distribution which on Windows includes Windows edition and if this is an evaluation copy
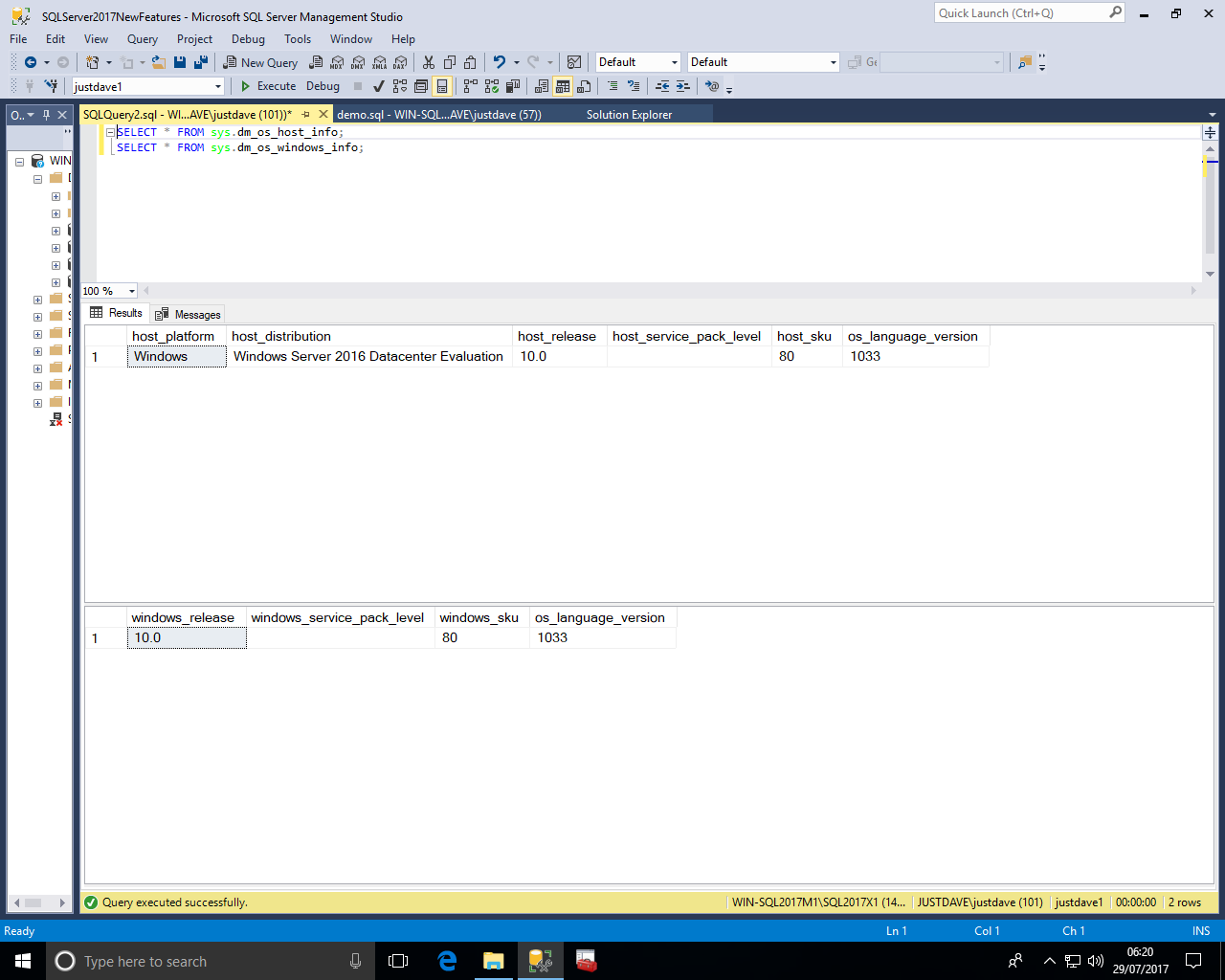
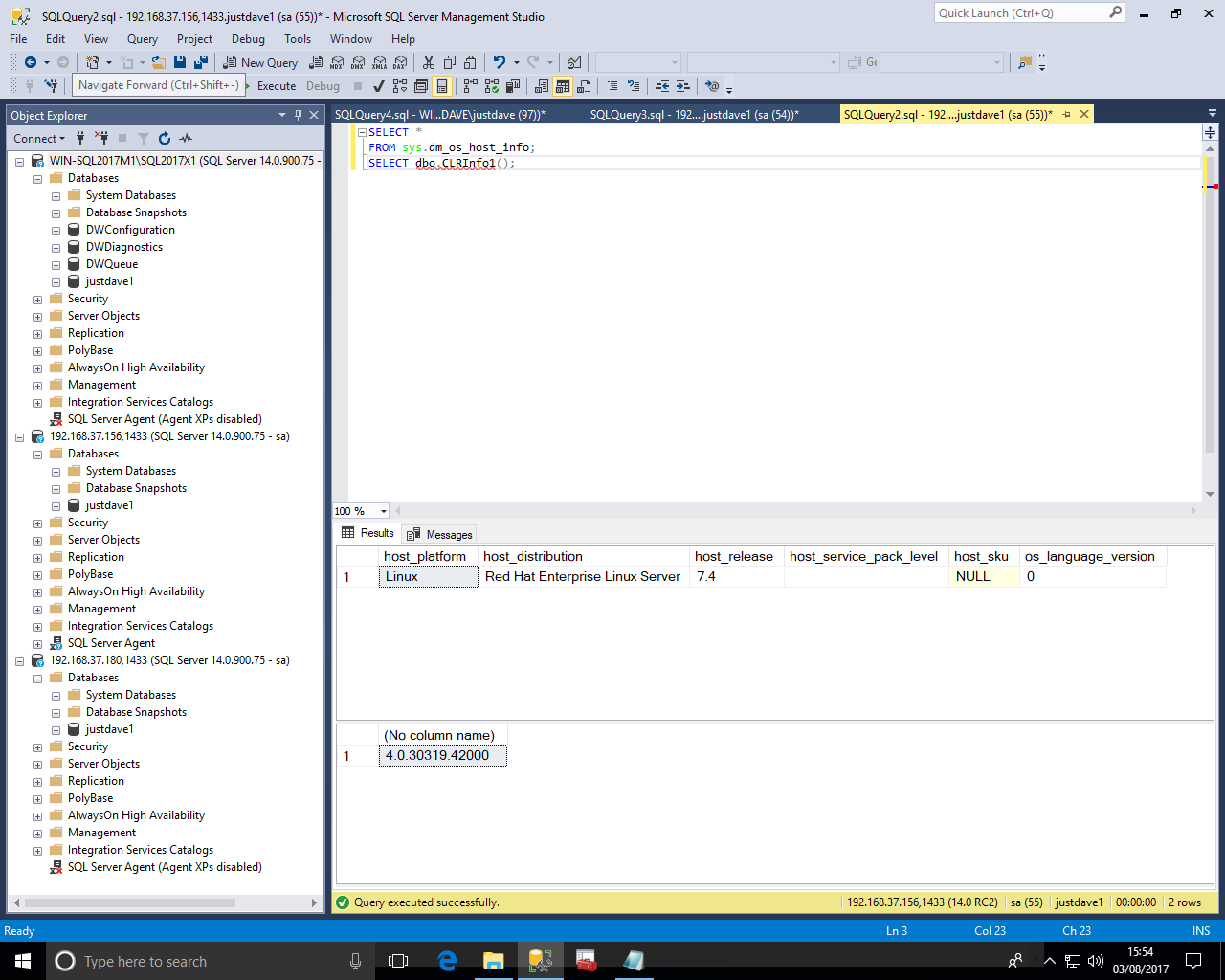
For Redhat Linux 7.3 the host_platform is "Linux" and the host_distribution shows "Red Hat Enterprise Linux Server".
NOTE: DMV sys.dm_os_windows_info contains empty and NULL fields!
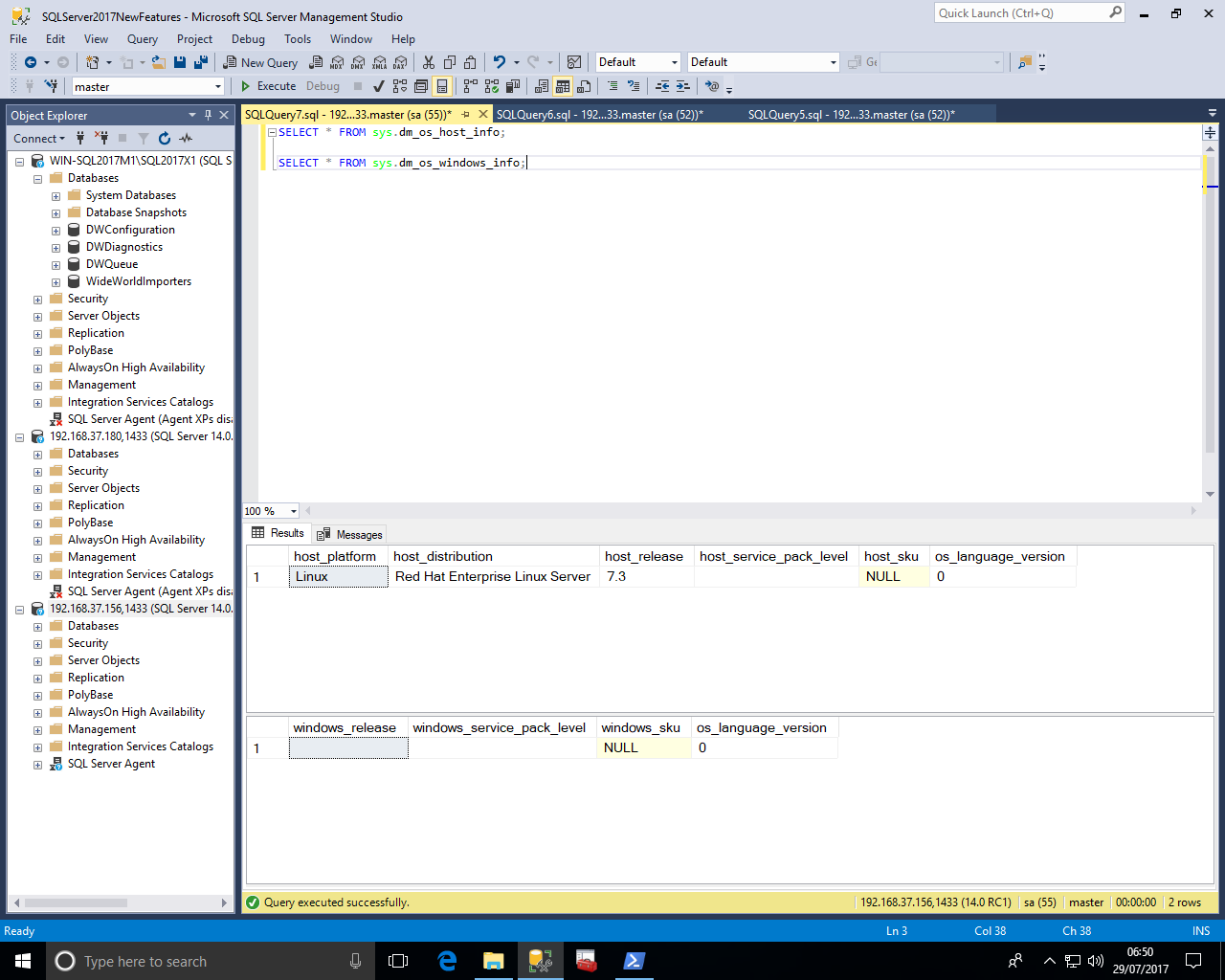
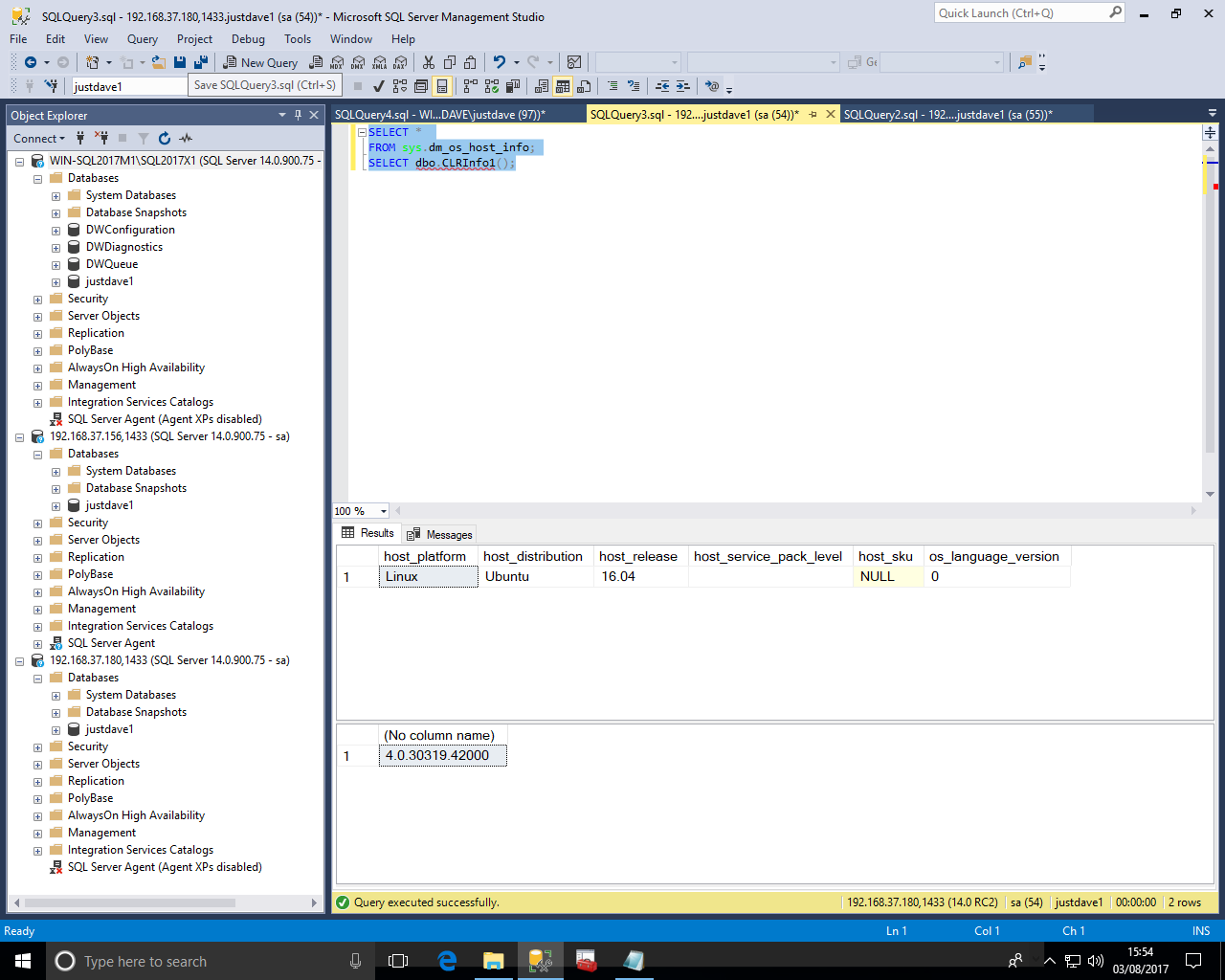
For Ubuntu 16.04 the host_platform is "Linux" and the host_distribution shows "Ubuntu"
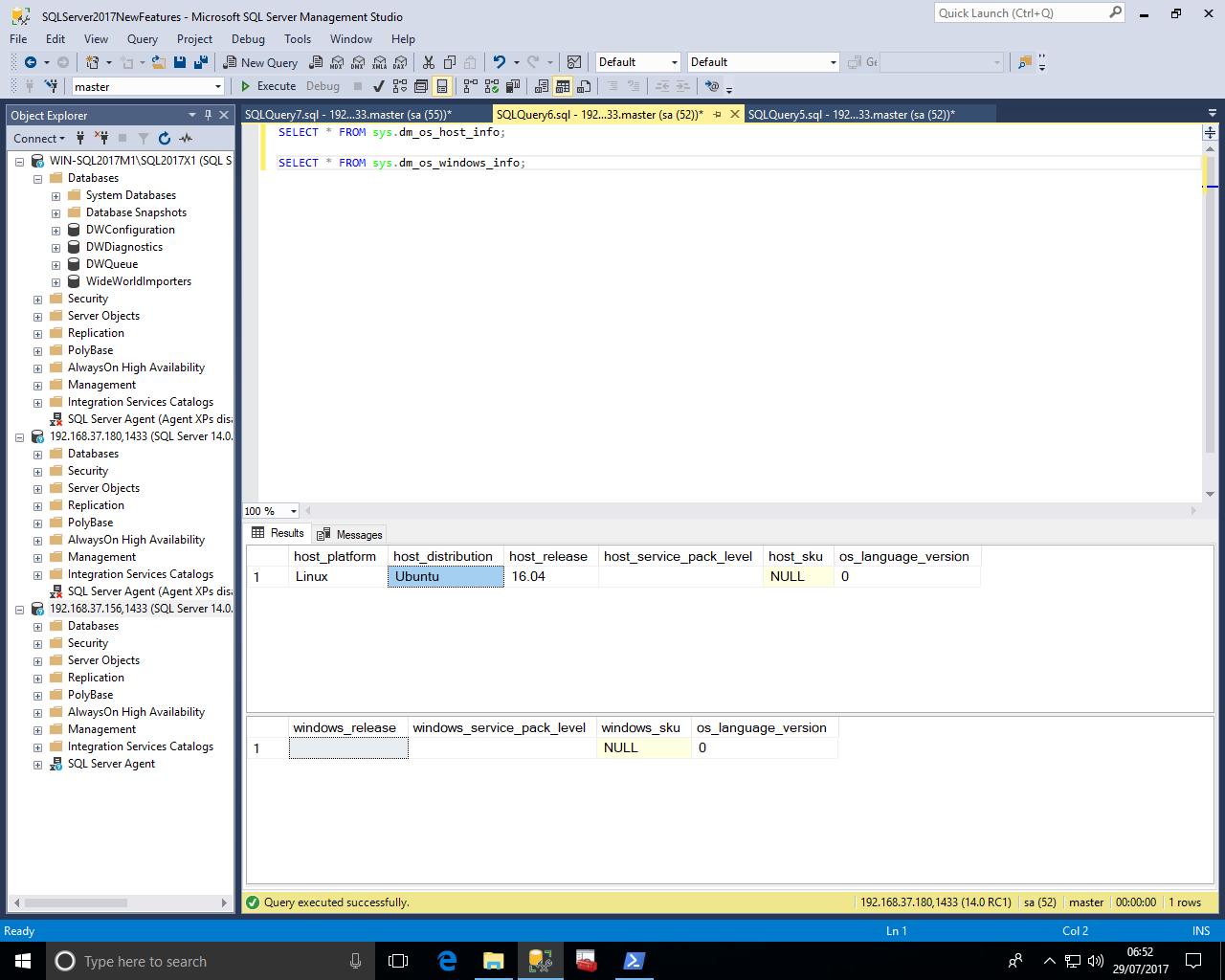
The new DMV covers tuning recommendations made by the server when automatic tunning is enabled
Currently the only option is of type "FORCE_LAST_GOOD_PLAN" for the new automatic tuning option
Note that columns state and details contain JSON documents in a DMO!
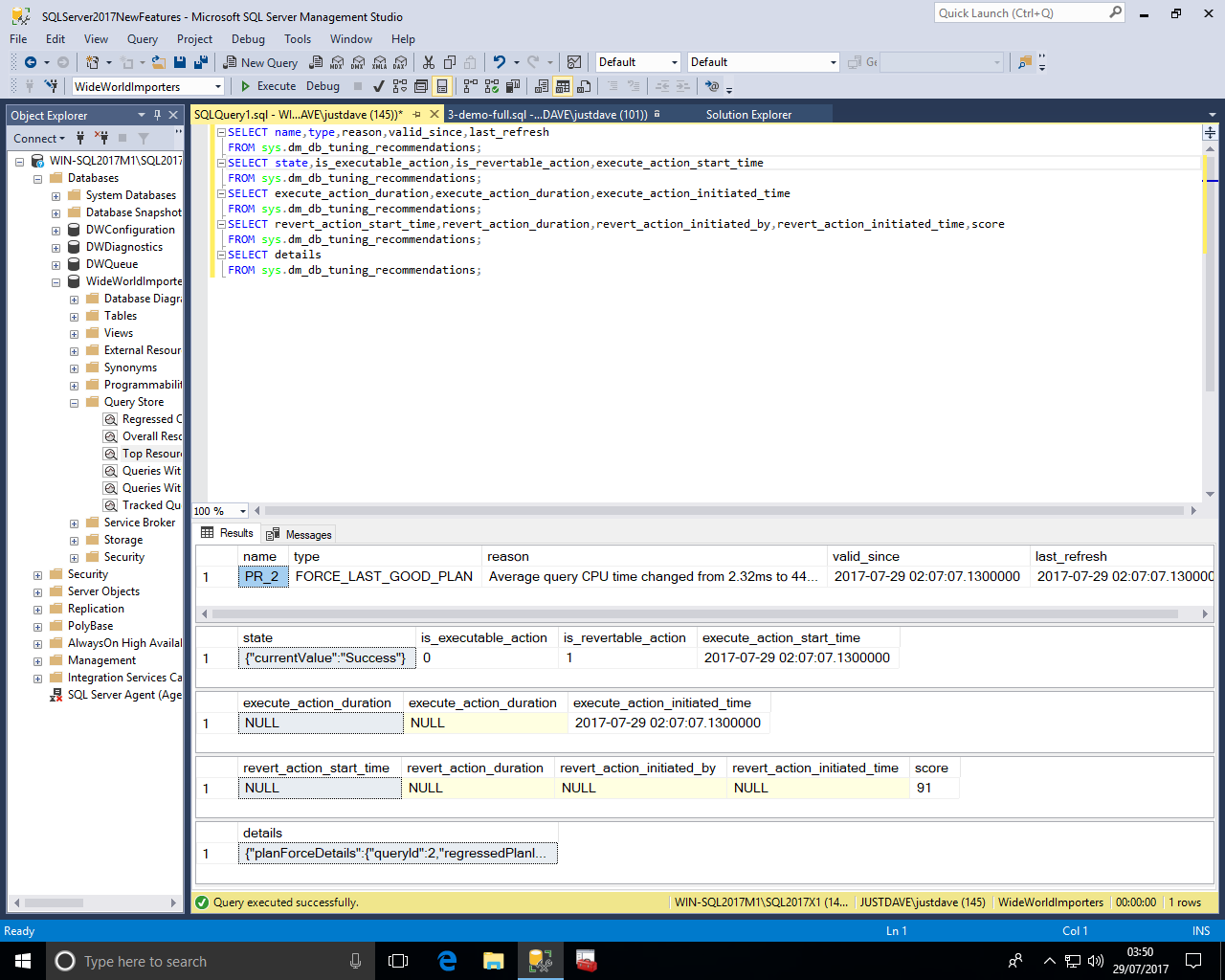
If we take the details field and on Linux use Python with json.tool we see
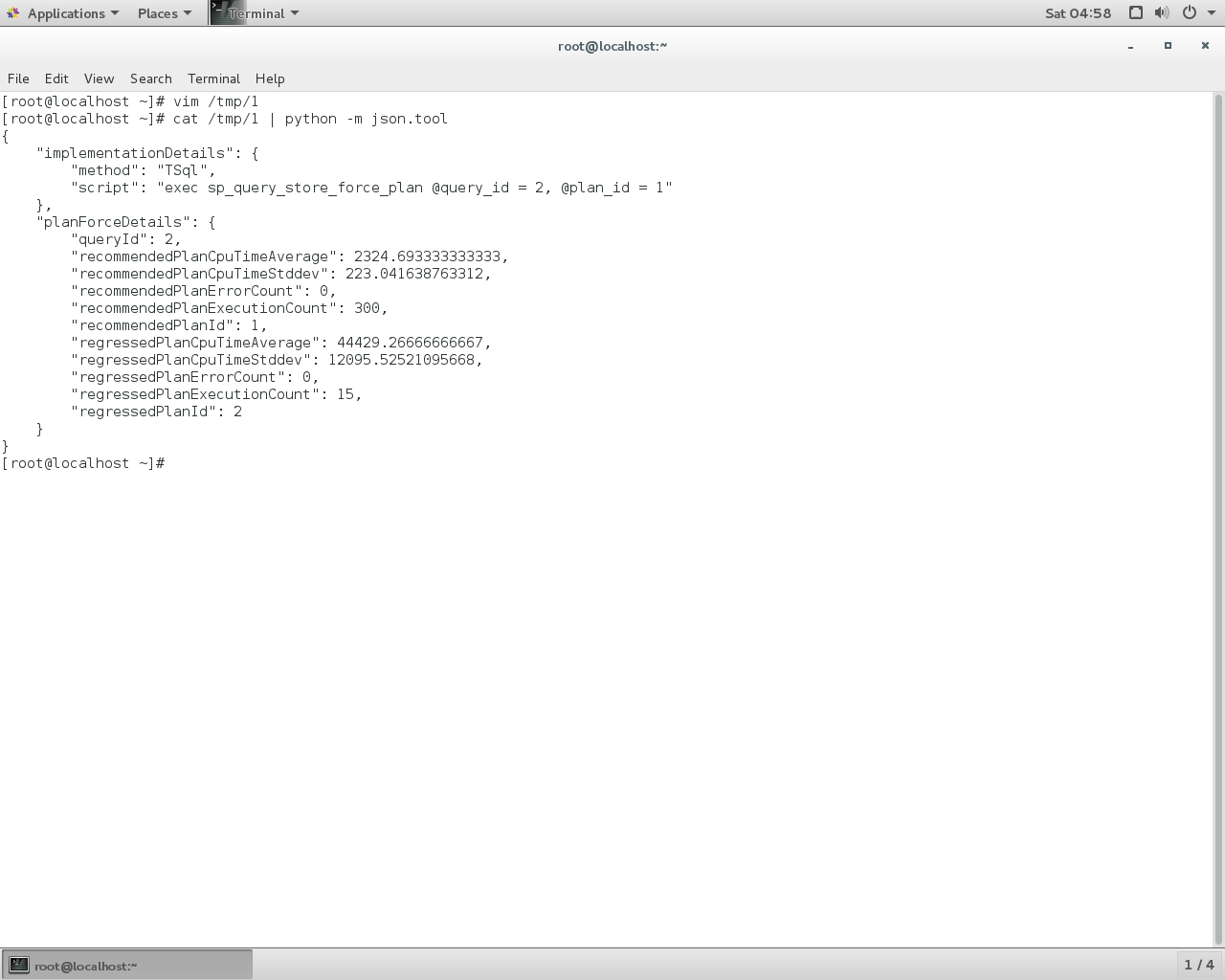
We can use a CROSS APPLY on the Json to extract the document fields as in the Query Store Automatic Tuning demo above
SELECT reason, score,
JSON_VALUE(state, '$.currentValue') state,
JSON_VALUE(state, '$.reason') state_transition_reason,
JSON_VALUE(details, '$.implementationDetails.script') script,
planForceDetails.*
FROM sys.dm_db_tuning_recommendations
CROSS APPLY OPENJSON (Details, '$.planForceDetails')
WITH ( [query_id] int '$.queryId',
[new plan_id] int '$.regressedPlanId',
[recommended plan_id] int '$.forcedPlanId'
) as planForceDetails;
CLR uses Code Access Security (CAS) in the .NET Framework, which is no longer supported as a security boundary.
A CLR assembly created with PERMISSION_SET = SAFE may be able to access external system resources, call unmanaged code, and acquire sysadmin privileges.
This is an sp_configure option 'clr strict security' which defaults to 1 (Enabled)
With the option enabled SAFE and EXTERNAL_ACCESS assemblies are treated as UNSAFE
Microsoft recommends that all assemblies be signed by a certificate or asymmetric key with a corresponding login that has been granted UNSAFE ASSEMBLY permission in the master database.
One other option is to set the DATABASE property TRUSTWORTH to ON via "ALTER DATABASE current SET TRUSTWORTHY ON"
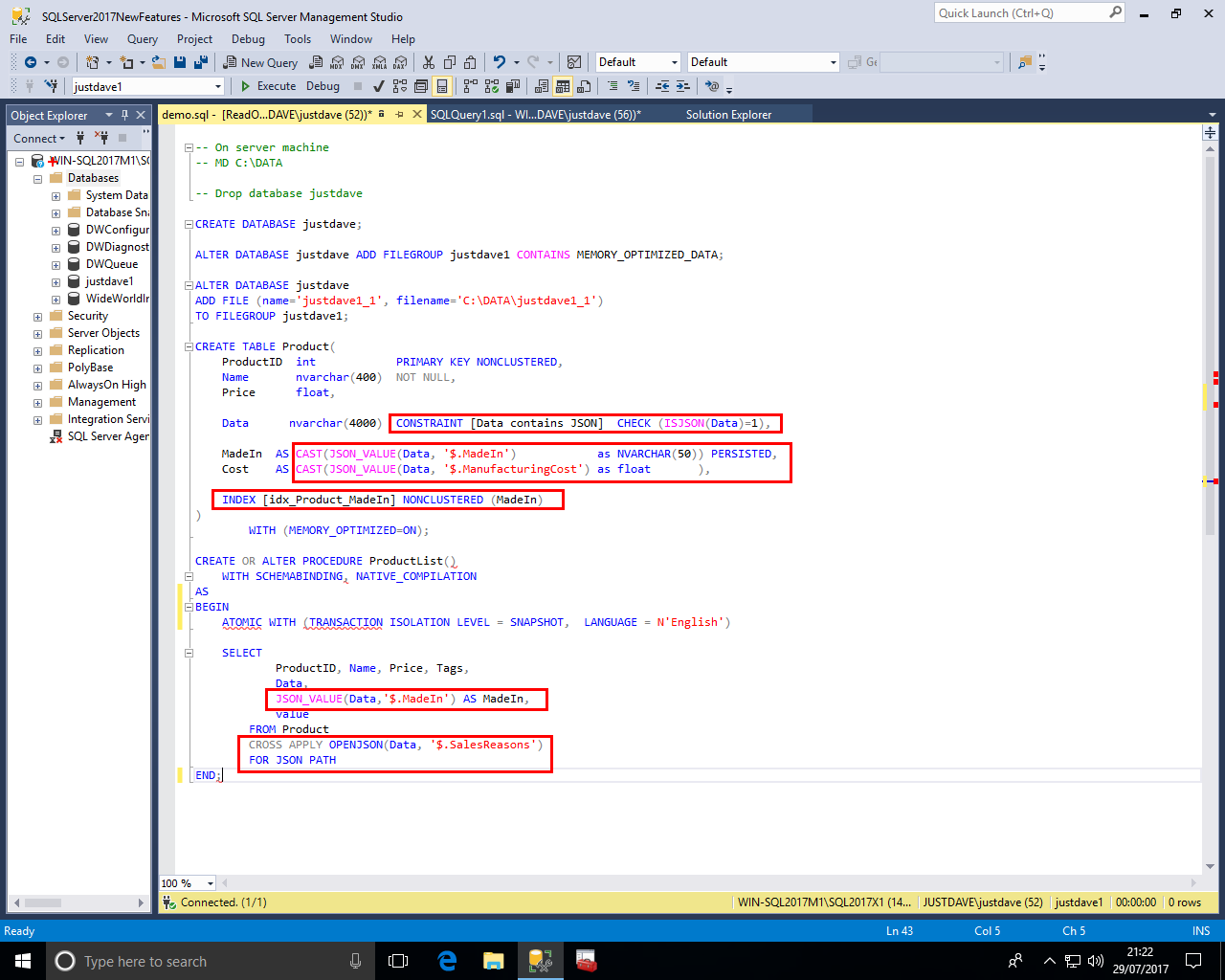
We create a new database justdave1
CREATE DATABASE justdave1; USE justdave1;
Next we turn on CLR
sp_configure 'clr enabled'; sp_configure 'clr enabled',1; RECONFIGURE; sp_configure 'clr enabled';
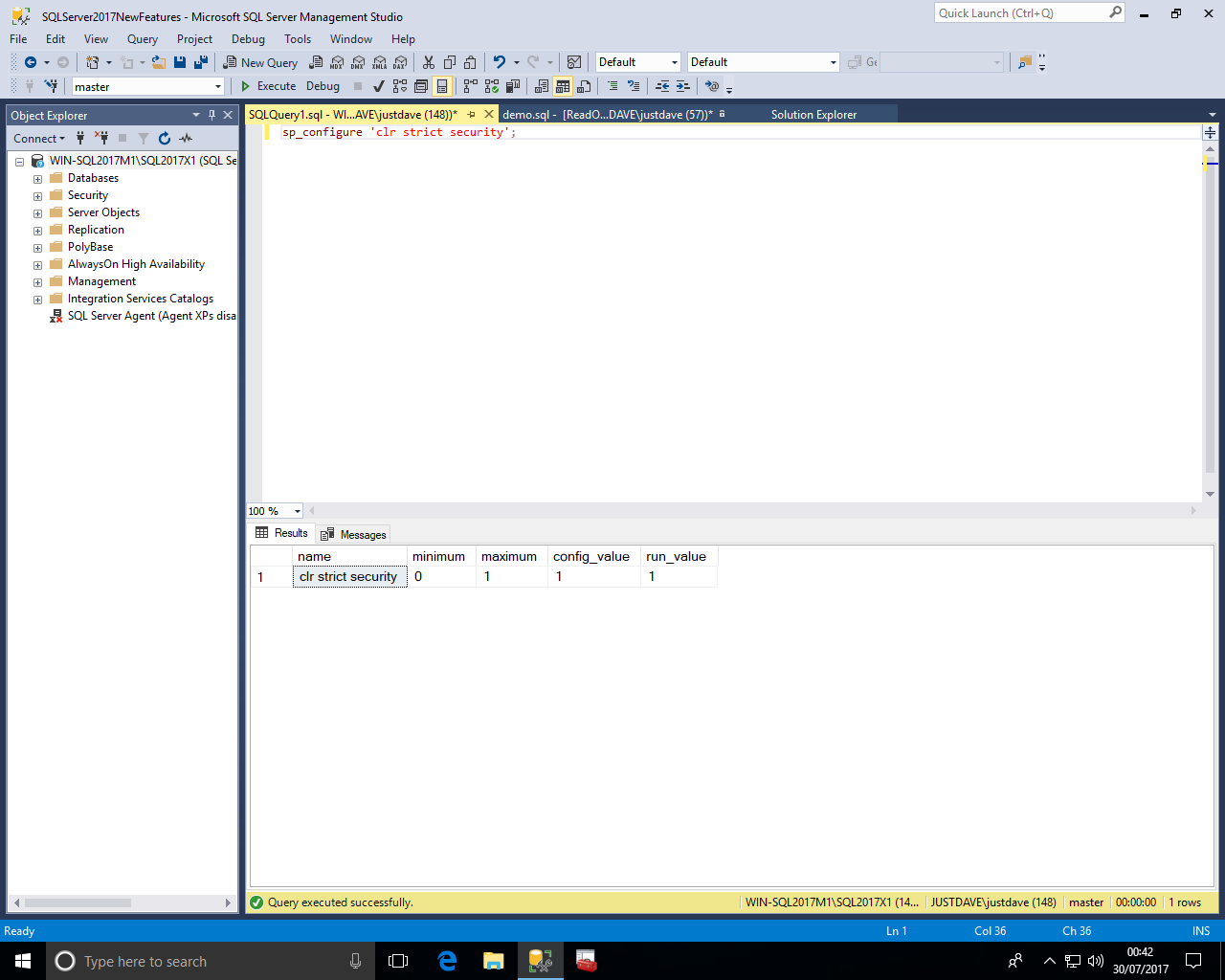
As the sp_configure option 'clr strict security' is an advanced option we first need to turn on 'show advanced options'
sp_configure 'show advanced options',1; RECONFIGURE;
We can then see the option with the default of 1 (ENABLED)
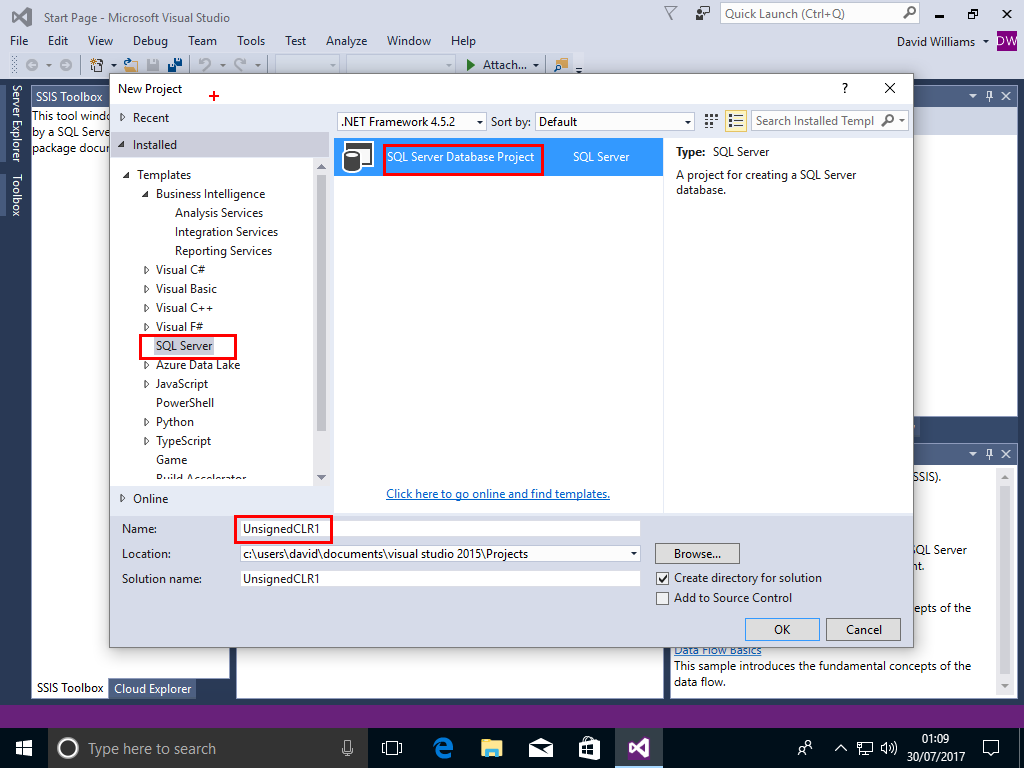
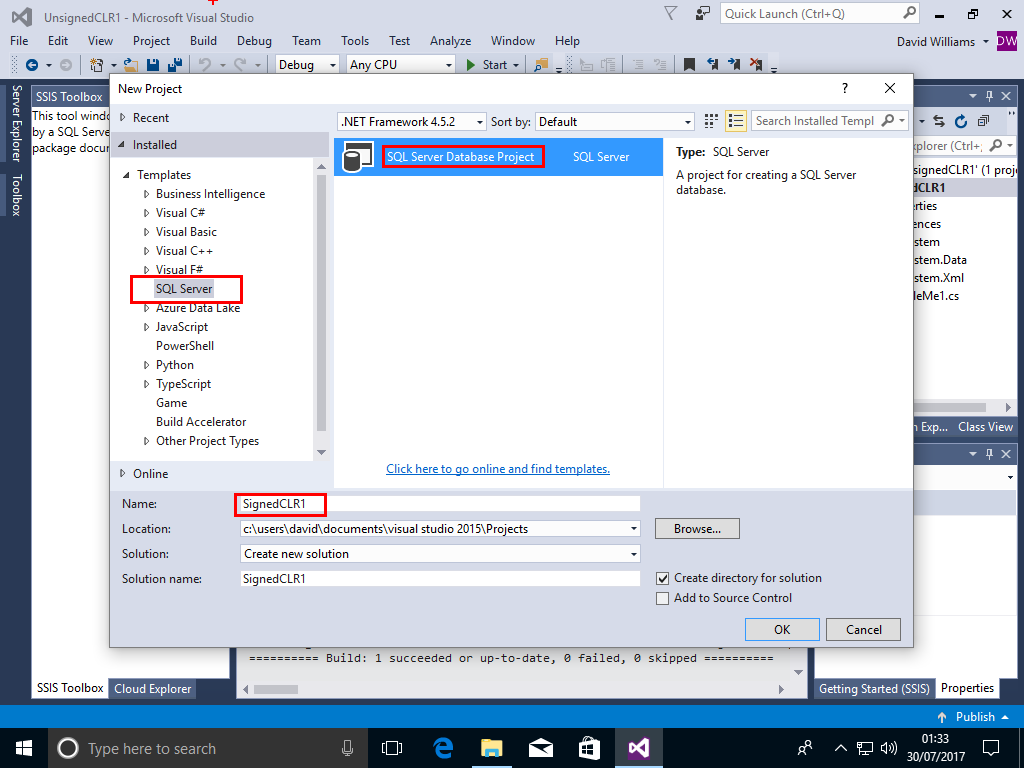
We go into Visual Studio 2015 with SSDT 2015 installed and create an default (unsigned) assembly
File->New->Project->SQL Server->SQL Server Database Project,call the Project UnsignedCLR1,then Click OK
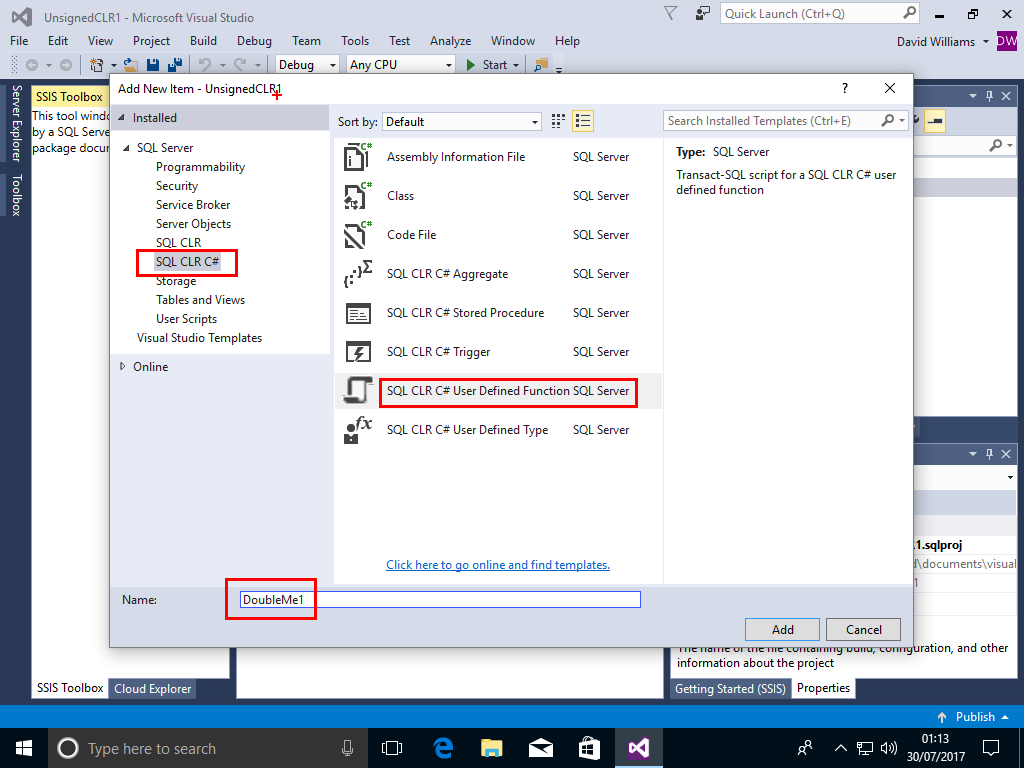
We now add a new SQL CLR# User Defined Function
Project->Add New Item->SQL CLR C#->SQL CLR# User Defined Function,call the Function DoubleMe1,then Click Add
Change the code for the function to
public partial class UserDefinedFunctions
{
public const double SALES_TAX = .086;
[SqlFunction()]
public static SqlDouble DoubleMe1(SqlDouble originalAmount)
{
SqlDouble doubleAmount = originalAmount * 2;
return doubleAmount;
}
}
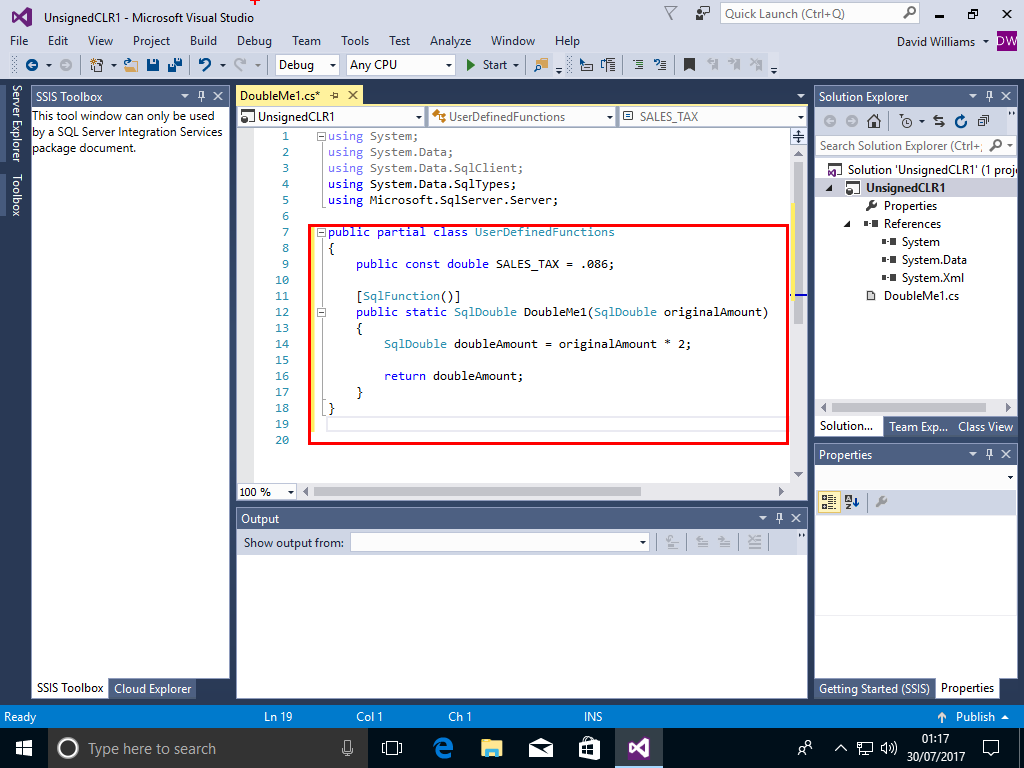
Choose Build and Build Solution
A DLL UnsignedCLR1.dll will be created in a folder similar to C:\Users\David\Documents\Visual Studio 2015\Projects\UnsignedCLR1\UnsignedCLR1\bin\Debug
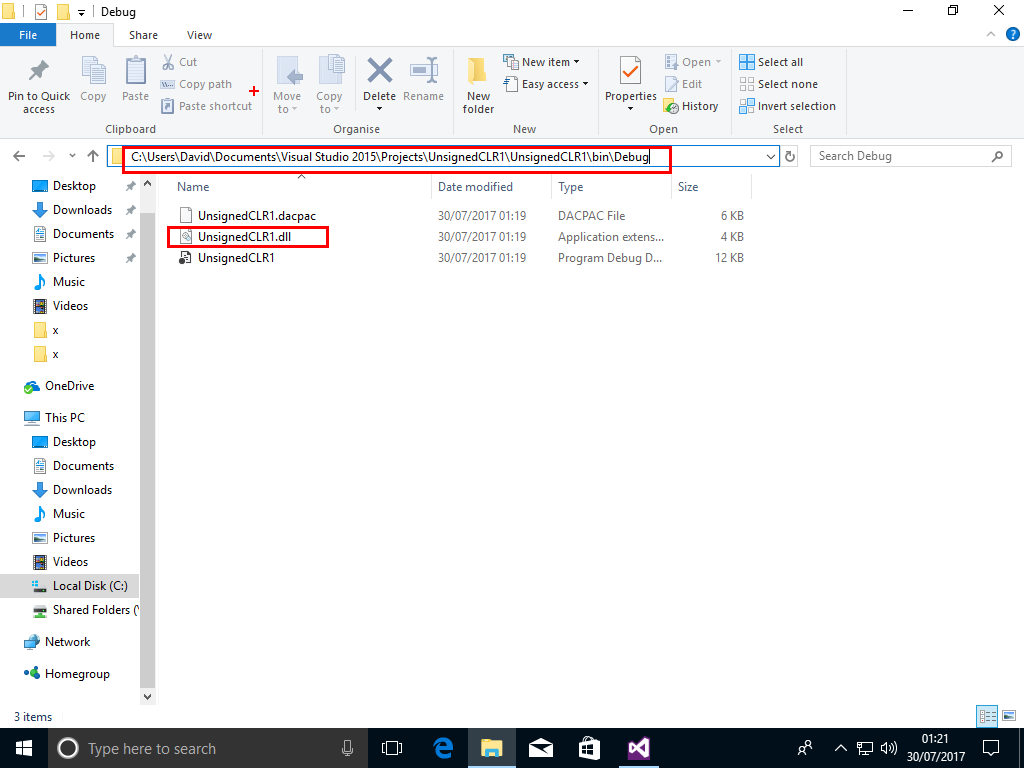
Copy the DLL to folder C:\x on the SQL Server machine (not the SSMS machine!)
In SSMS we attempt to register the assembly however this is blocked due to 'clr strict security' being set to 1
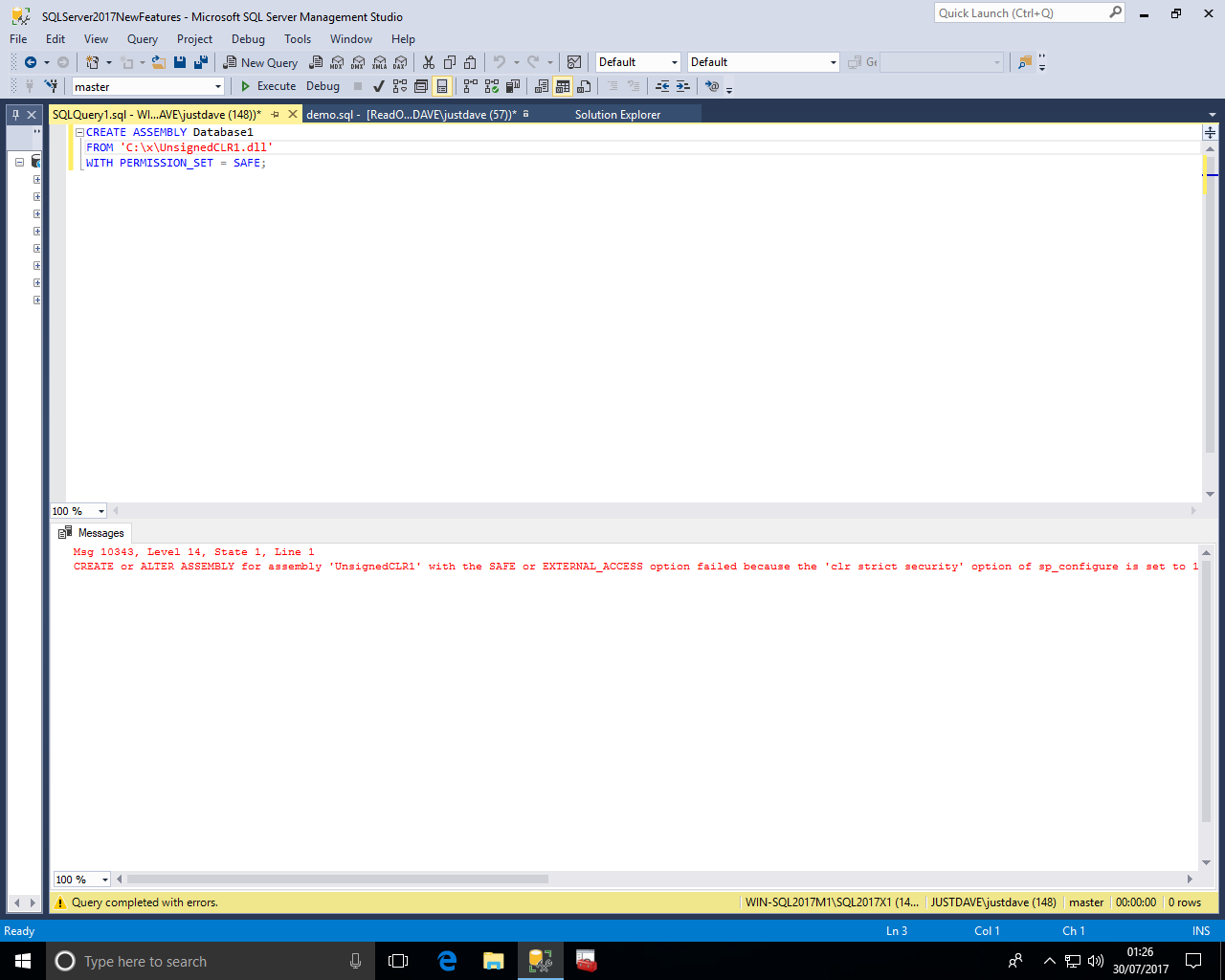
We next create a new strongly named (signed) assembly signed by a certificate or asymmetric key with a corresponding login that has been granted UNSAFE ASSEMBLY permission in the master database.
File->New->Project->SQL Server->SQL Server Database Project,call the Project SignedCLR1,then Click OK
We now add a new SQL CLR# User Defined Function
Project->Add New Item->SQL CLR C#->SQL CLR# User Defined Function,call the Function DoubleMe2,then Click Add
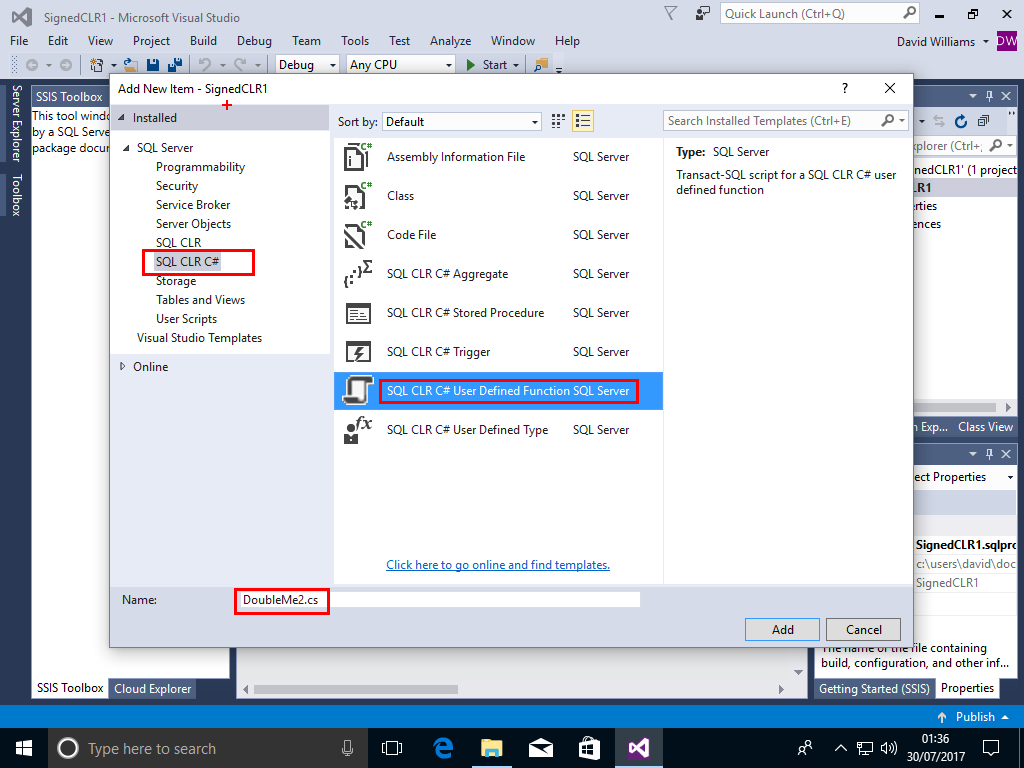
Change the code for the function to
public partial class UserDefinedFunctions
{
public const double SALES_TAX = .086;
[SqlFunction()]
public static SqlDouble DoubleMe2(SqlDouble originalAmount)
{
SqlDouble doubleAmount = originalAmount * 2;
return doubleAmount;
}
}
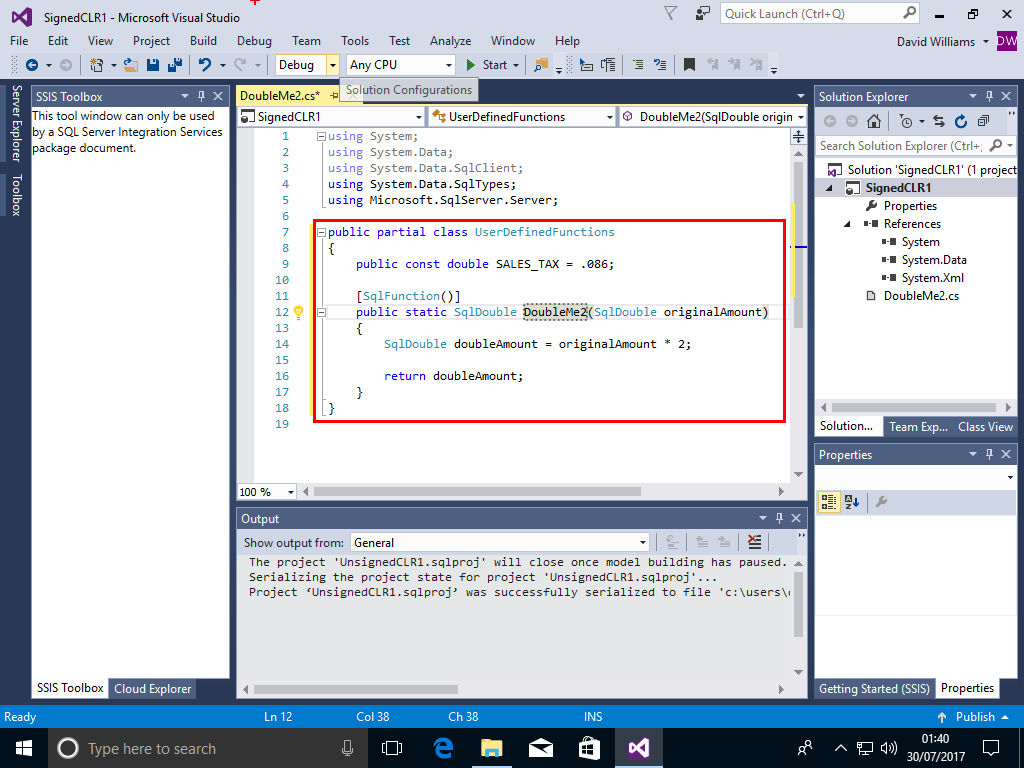
Go to Project->SignCLR1 Properties->SQLCLR-> and scroll down to the Signing button, Click on the Signing Button
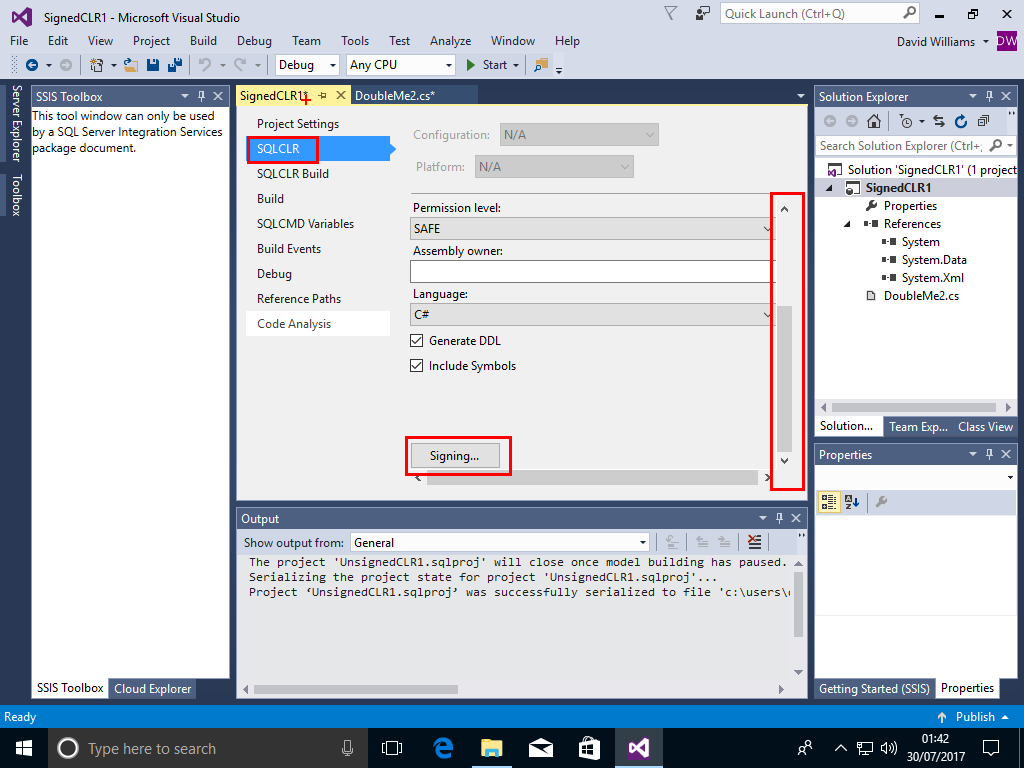
Click on "Sign the Assembly" then in the dropdown box choose New for a new "strong name key file"
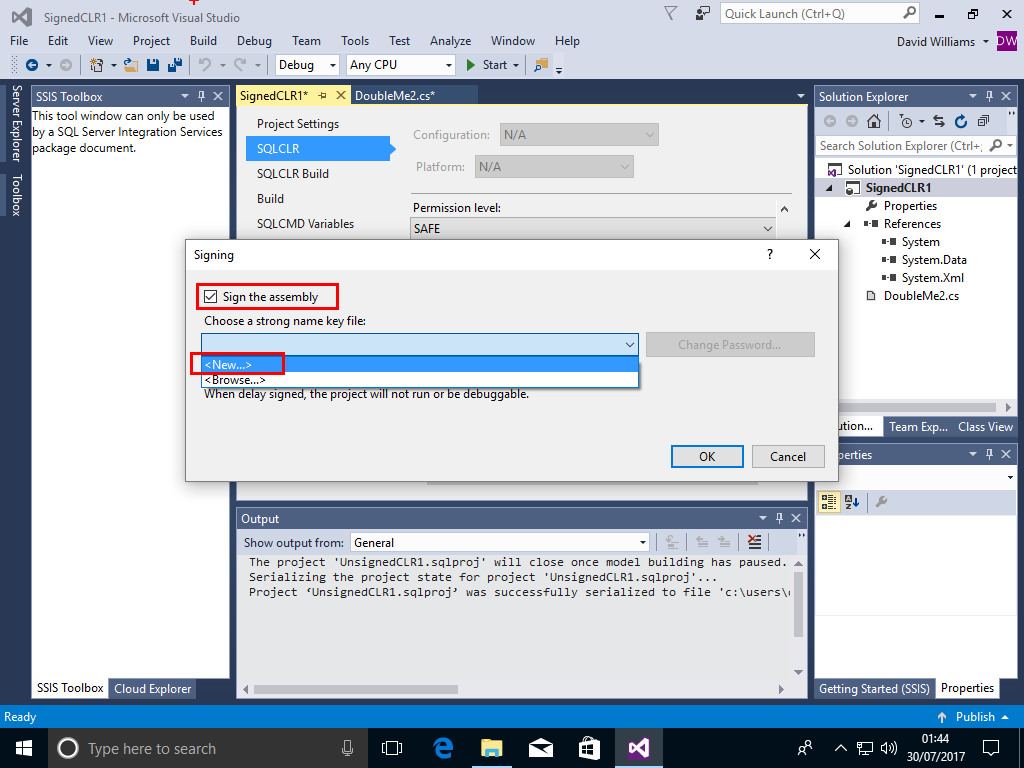
A dialog box will poup, enter a filename WITHOUT extension and a password and Click OK
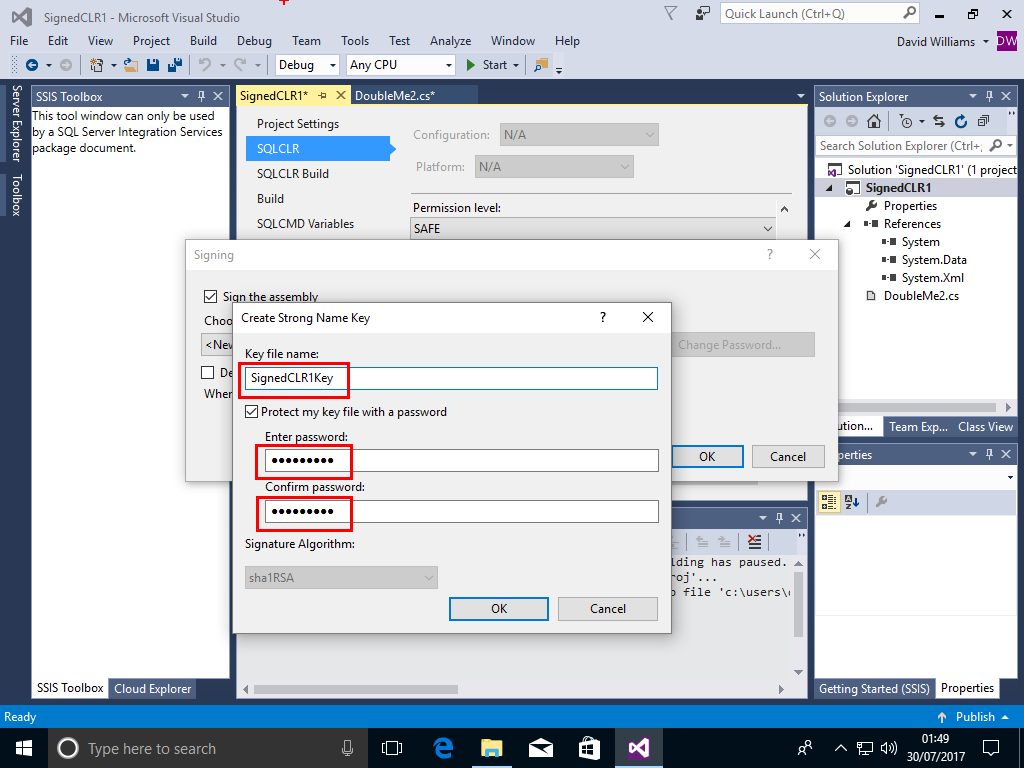
Click OK again then Choose Build and Build Solution
A DLL SignedCLR1.dll will be created in a folder similar to C:\Users\David\Documents\Visual Studio 2015\Projects\SignedCLR1\SignedCLR1\bin\Debug
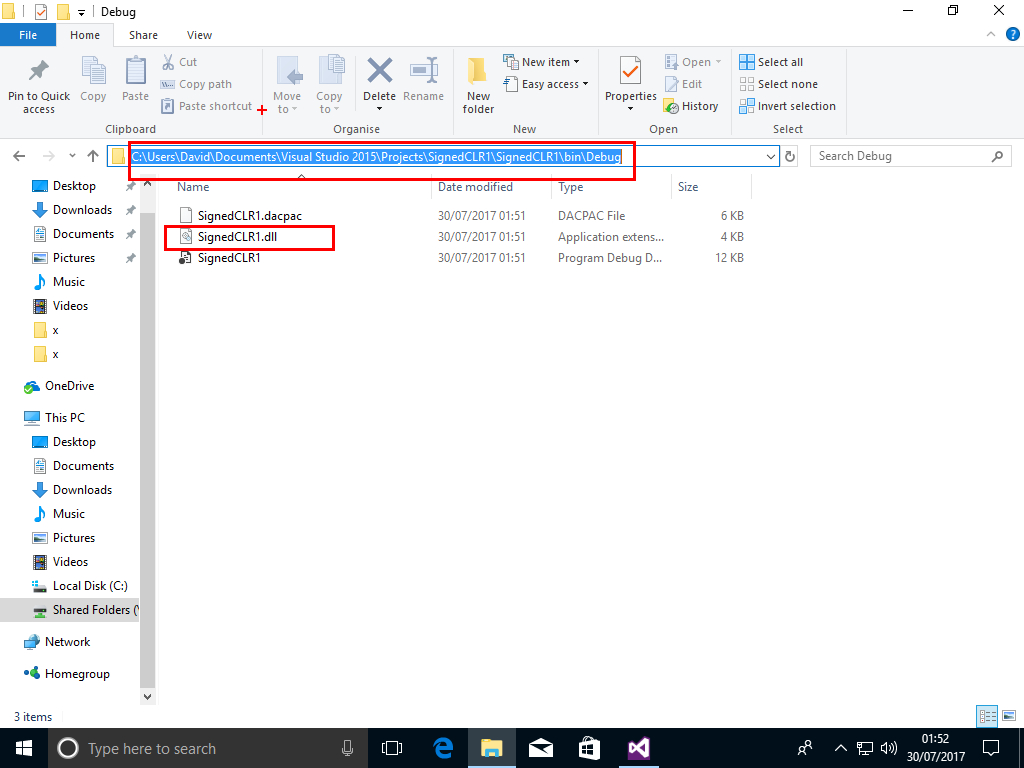
Copy the DLL to folder C:\x on the SQL Server machine (not the SSMS machine!)
In SSMS we use master (IMPORTANT!) and create an ASYMMETRIC KEY from the DLL file!
-- Return the administrator we are logged in as (JUSTDAVE\justdave) SELECT SUSER_NAME(); USE master; -- DROP ASYMMETRIC KEY SQLCLRTestKey; CREATE ASYMMETRIC KEY SQLCLRTestKey FROM EXECUTABLE FILE = 'C:\x\SignedCLR1.dll';
We then create a login from the ASYMMETRIC KEY and grant the login UNSAFE ASSEMBLY permissions
CREATE LOGIN SQLCLRTestLogin FROM ASYMMETRIC KEY SQLCLRTestKey; GRANT UNSAFE ASSEMBLY TO SQLCLRTestLogin;
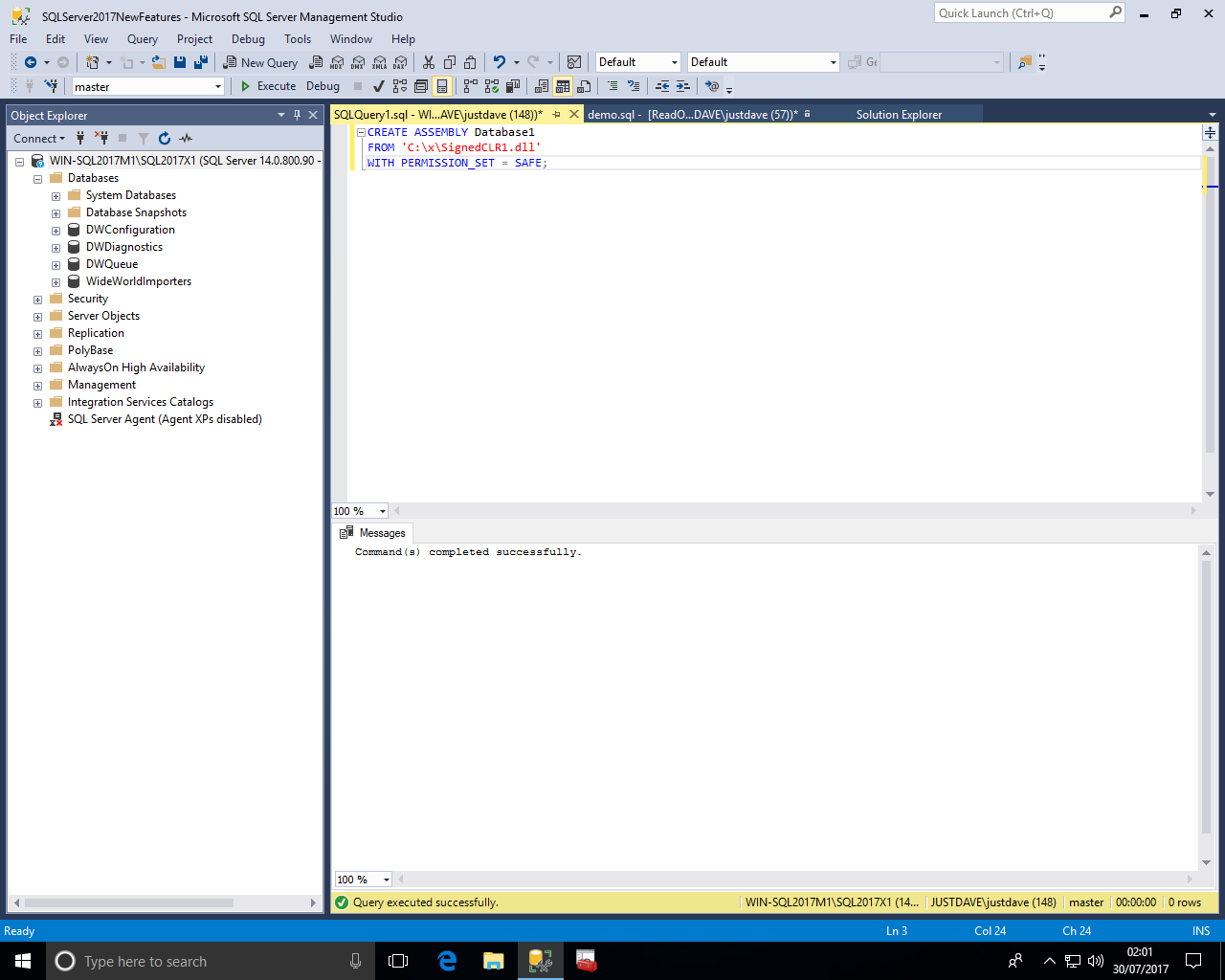
We can then register the assembly!
USE justdave1; DROP FUNCTION IF EXISTS dbo.DoubleMe2; DROP ASSEMBLY IF EXISTS Database1; CREATE ASSEMBLY Database1 FROM 'C:\x\SignedCLR1.dll' WITH PERMISSION_SET = SAFE;
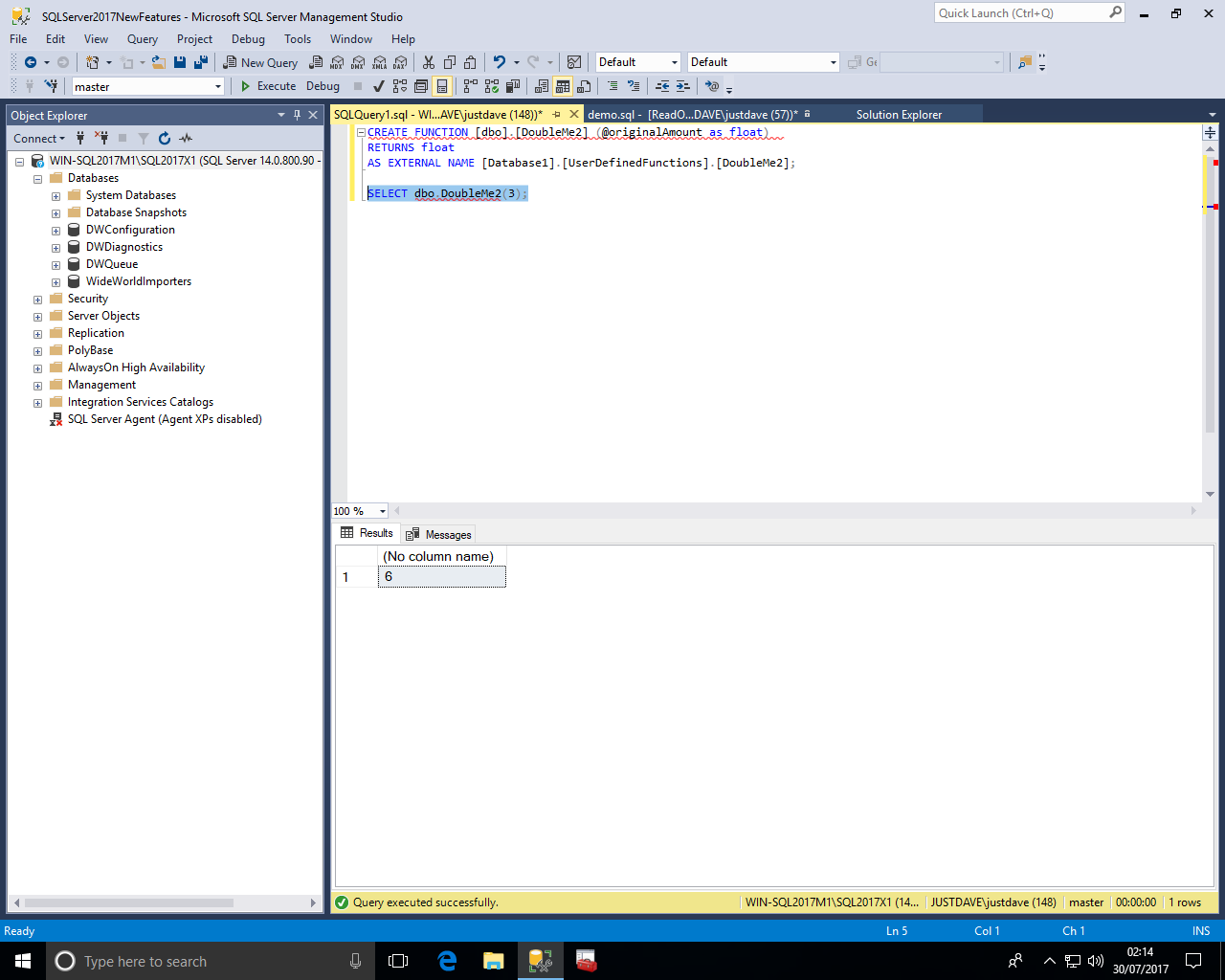
We then create the function and test the function
CREATE FUNCTION [dbo].[DoubleMe2] (@originalAmount as float) RETURNS float AS EXTERNAL NAME [Database1].[UserDefinedFunctions].[DoubleMe2]; SELECT dbo.DoubleMe2(3);
SQL Server 2017 RC1 enhances 'clr strict security' adding a way to whitelist CLR assemblies via sp_add_trusted_assembly
However this requires getting the hash value for the assembly
We use the DLL C:\x\UnsignedCLR1.dll unsigned assembly from the example above which we previously could not load with 'clr strict security' enabled.
In Visual Studio 2015 we create a new project with a Console Application
File->New->Project->Visual C#->ConsoleApplication,call the Project SHA512Finder,then Click OK
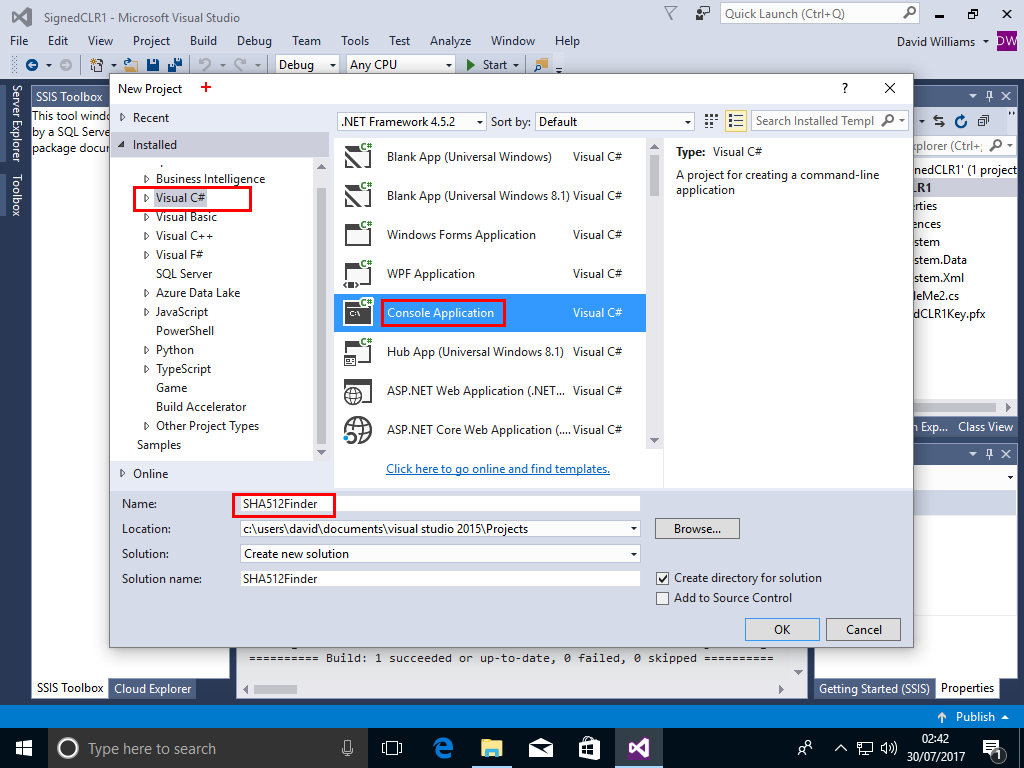
We then add the following Code to the Project
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using System.IO;
namespace SHA512Finder
{
class Program
{
static void Main(string[] args)
{
if (args.Length == 0)
{
System.Console.WriteLine("Please enter a filename argument.");
return;
}
if (args.Length == 1)
{
System.Console.WriteLine("Please also enter a clrname argument.");
return;
}
Console.Write("-- Processing ");
Console.WriteLine(args[0]);
Byte[] data = File.ReadAllBytes(args[0]);
string hex = BitConverter.ToString(data).Replace("-", string.Empty);
Console.Write("DECLARE @MyBin VARBINARY(MAX)=0x");
Console.Write(hex);
Console.WriteLine(";");
Console.WriteLine("");
Console.WriteLine("DECLARE @myhash VARBINARY(64);");
Console.WriteLine("");
Console.Write("DECLARE @mydescription NVARCHAR(4000)='");
Console.Write(args[1]);
Console.WriteLine(", version=0.0.0.0, culture=neutral, publickeytoken=null, processorarchitecture=msil';");
Console.WriteLine("");
Console.WriteLine("SELECT @myhash=HASHBYTES('SHA2_512',@myBin);");
Console.WriteLine("");
Console.WriteLine("EXEC sp_add_trusted_assembly @hash=@myhash,");
Console.WriteLine("@description=@mydescription;");
}
}
}
Choose Build->Build Solution
We then run the binary to read the DLL and generate a .sql file with HASHBYTES and sp_add_trusted_assembly to add the hash value to the listed of trusted hash values.
cd C:\Users\David\Documents\Visual Studio 2015\Projects\SHA512Finder\SHA512Finder\bin\Debug .\SHA512Finder.exe C:\x\UnsignedCLR1.dll unsignedclr1 > C:\x\1.sql
We then load the sql file into SSMS and run this whitelist the hash value for the assembly
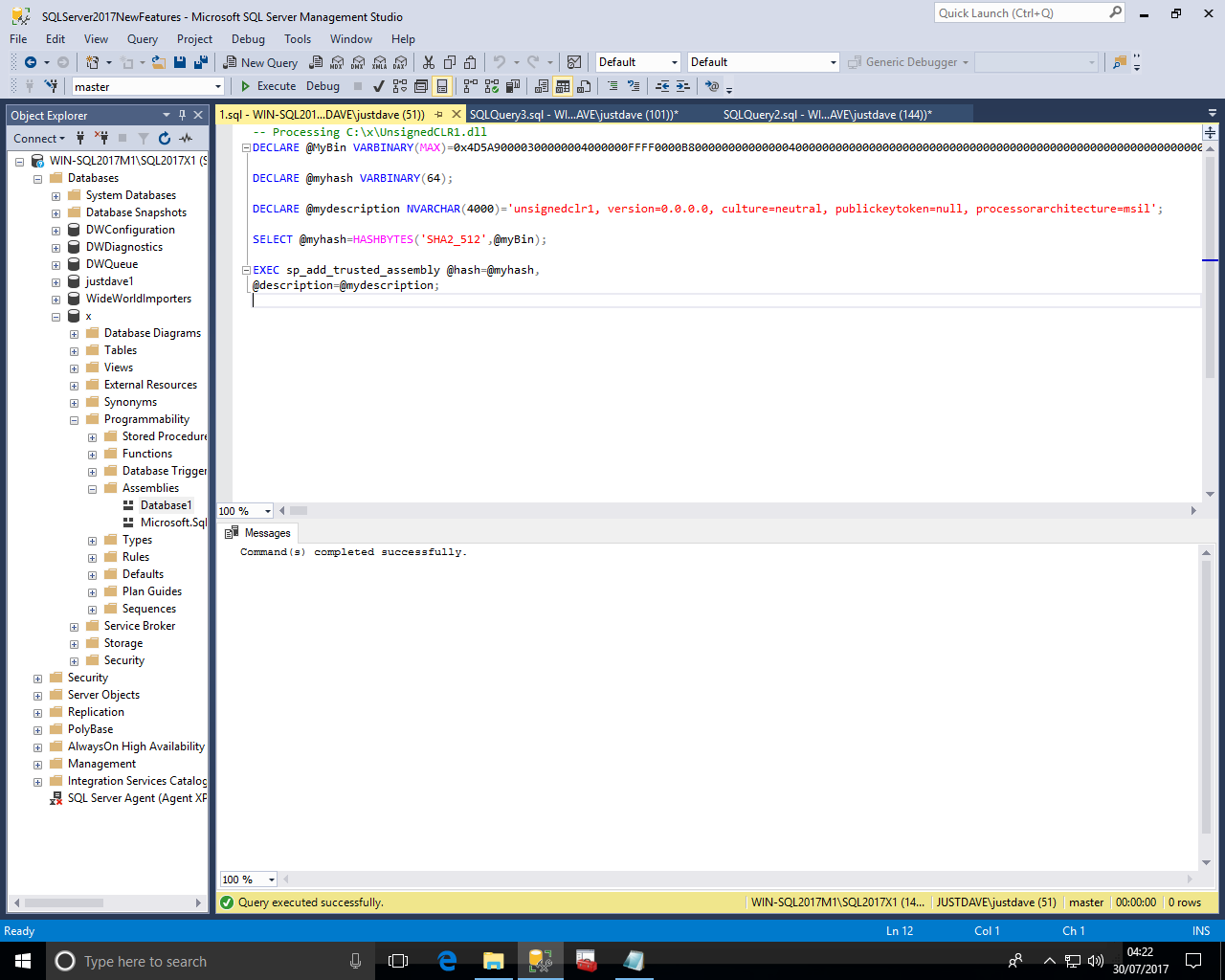
We then try creating the assembly again and this time it works even with the unsigned assembly!
CREATE ASSEMBLY Database1 FROM 'C:\x\UnSignedCLR1.dll' WITH PERMISSION_SET = SAFE;
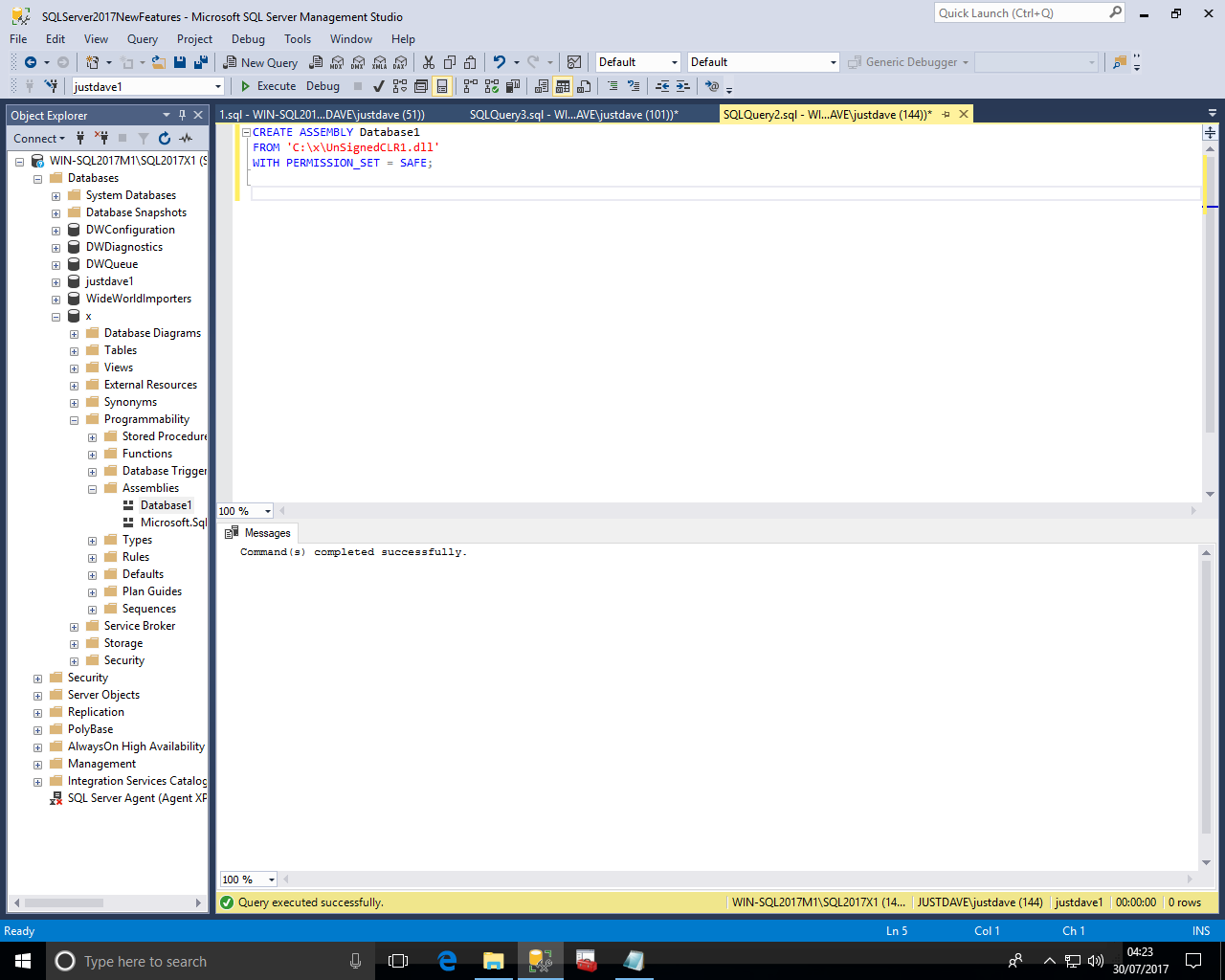
We can then test the Assembly
CREATE FUNCTION [dbo].[DoubleMe1] (@originalAmount as float) RETURNS float AS EXTERNAL NAME [Database1].[UserDefinedFunctions].[DoubleMe1]; SELECT dbo.DoubleMe1(3);
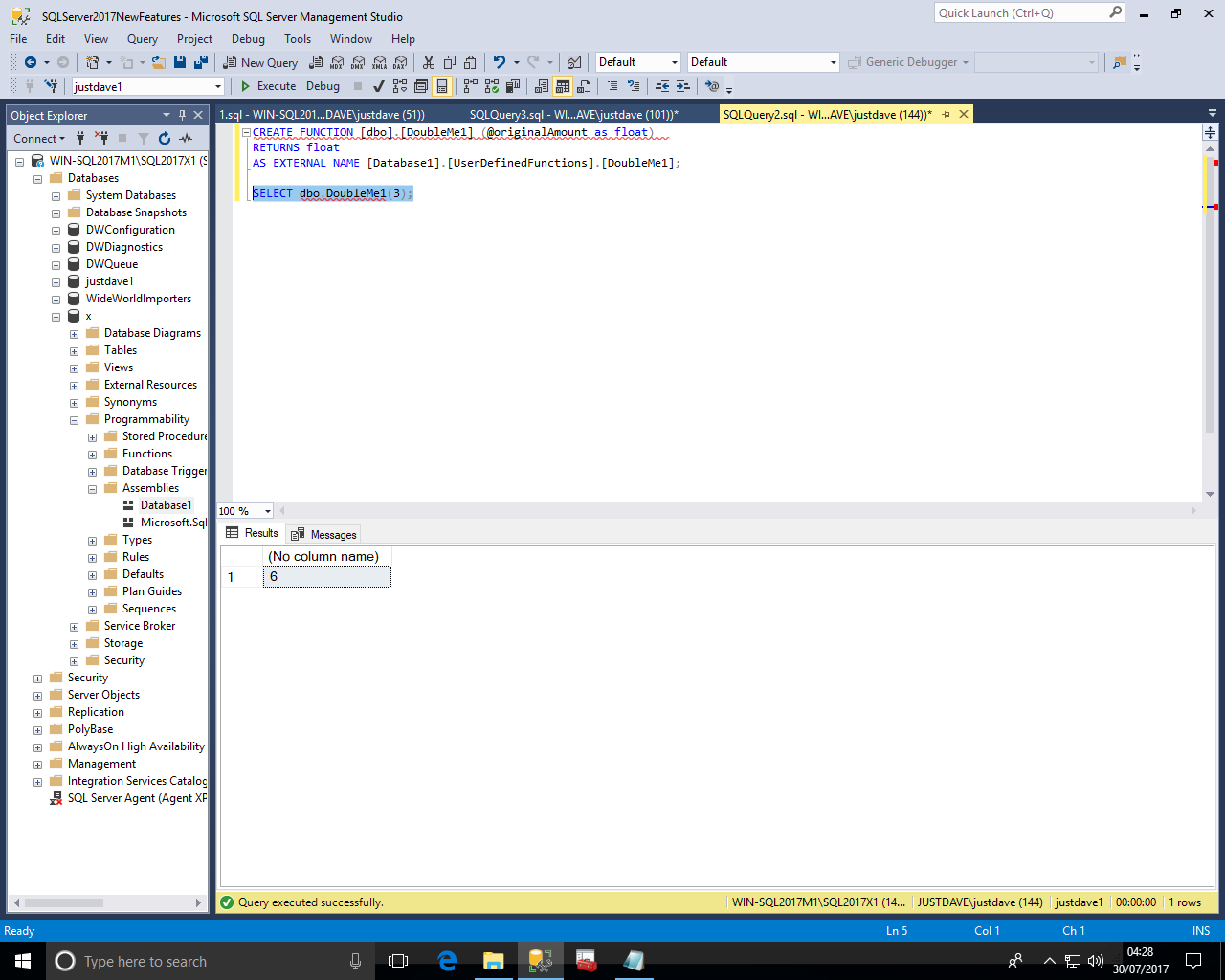
We can then query the new DMV sys.trusted_assemblies, we get the hash and description as well as create_date and created_by
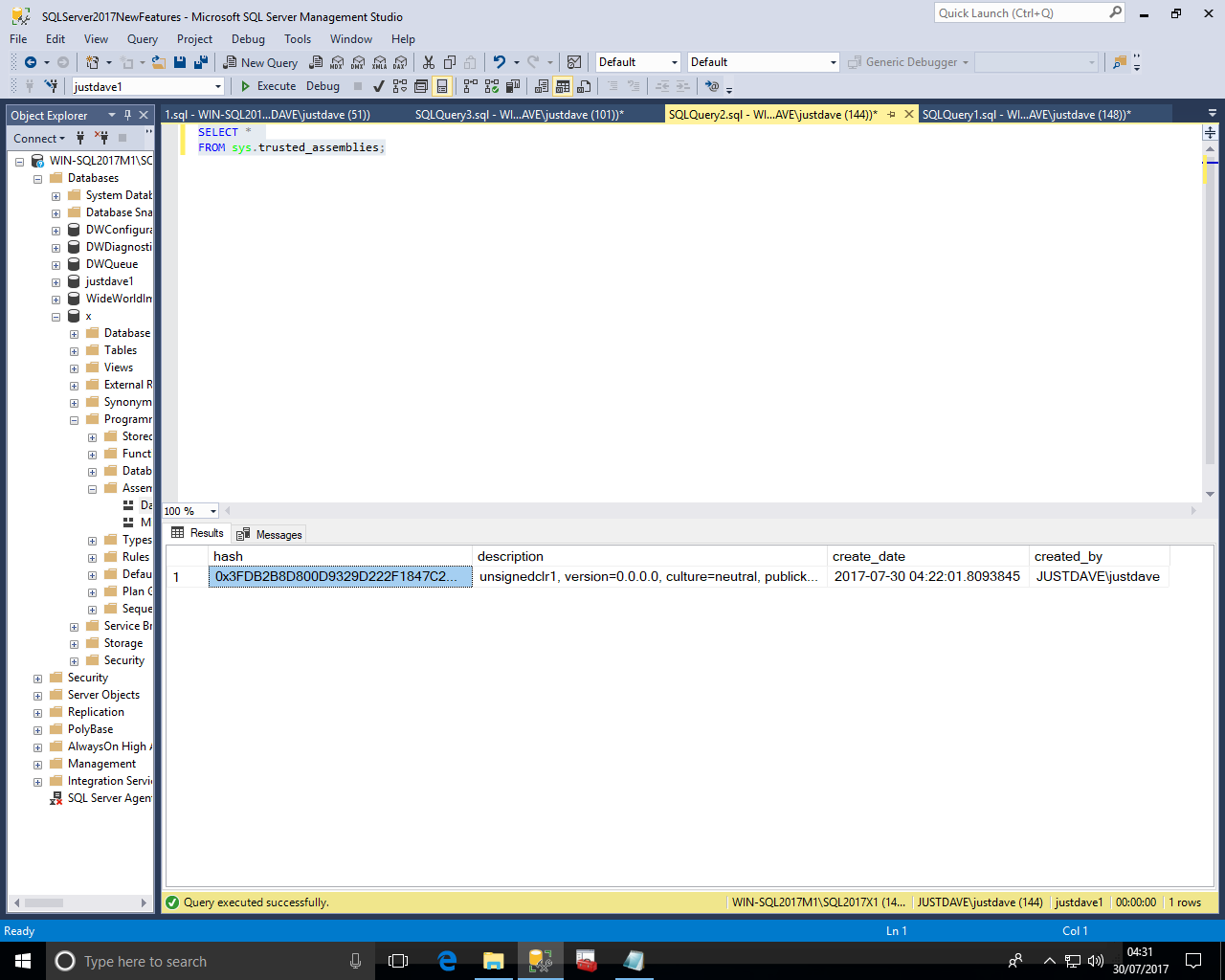
We then drop the function and assembly
DROP FUNCTION IF EXISTS dbo.DoubleMe1; DROP ASSEMBLY IF EXISTS Database1;
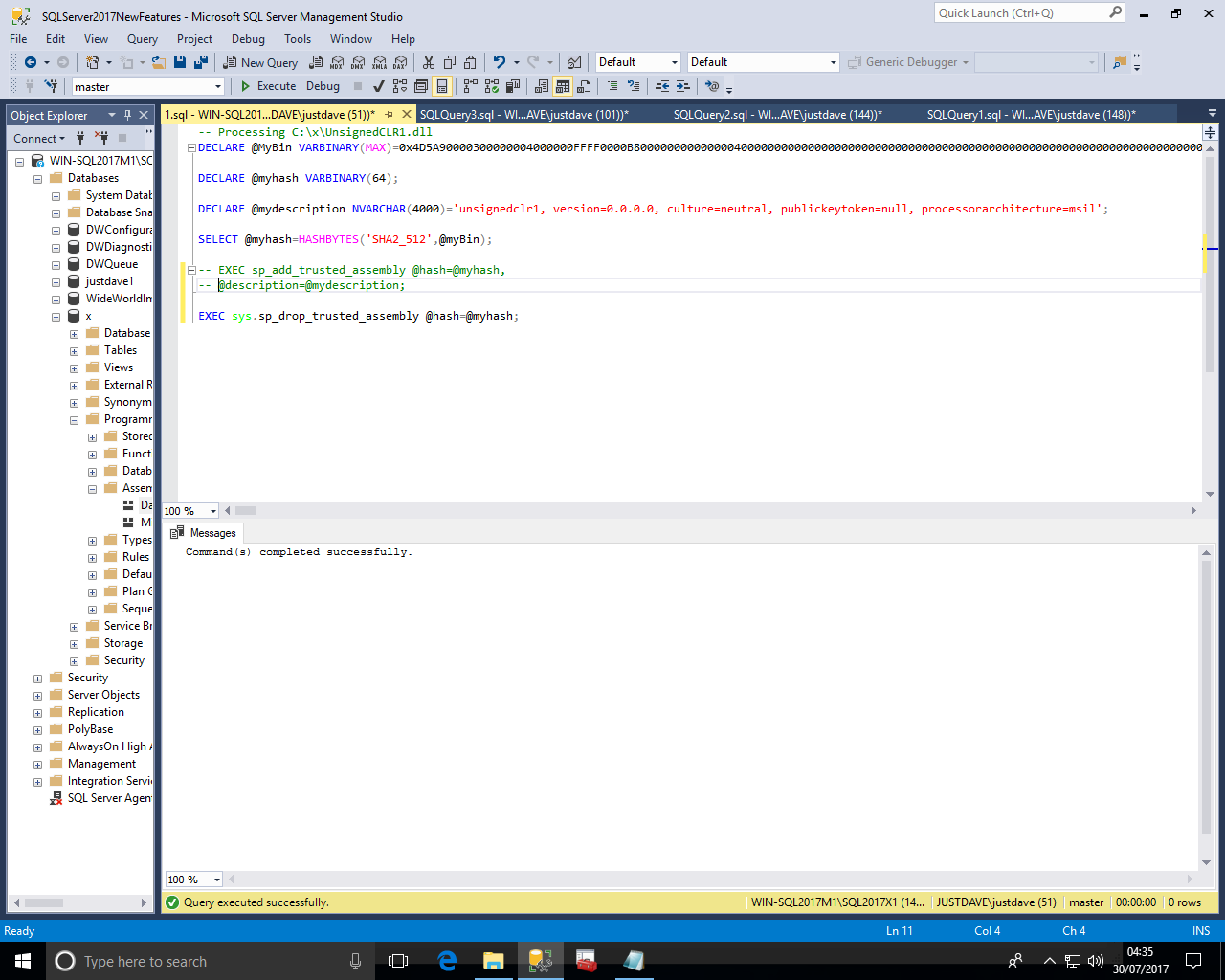
We can then edit the generated sql script to call sp_drop_trusted_assembly with the hash value
Clusterless Availability Groups are now possible e.g. From Windows to Linux.
Syntax is "CREATE AVAILABILITY GROUP [ag1] WITH (CLUSTER_TYPE = NONE)"
Since there is no cluster, automatic failover is NOT supported - THIS IS NOT AN HA SOLUTION
Clusterless Availability Groups can be used as part of a Linux migration
A Minimum Replica Commit Availability Groups setting has been added to Availability Groups
In CTP Releases the syntax was "CREATE AVAILABILITY GROUP [ag1] WITH (REQUIRED_COPIES_TO_COMMIT = 1)"
In RC1 the syntax was changed to "CREATE AVAILABILITY GROUP [ag1] WITH (REQUIRED_SYNCHRONOUS_SECONDARIES_TO_COMMIT = 1
The setting is the minimum number of synchronous secondary replicas required to commit before the primary replica commits a transaction.
This guarantees that SQL Server transactions will wait until the transaction logs are updated on the minimum number of synchronous secondary replicas.
The Default is 0, maximum is number of replicas-1.
The Relevant replicas must be in synchronous commit mode.
Normally if a secondary replica in synchronous commit mode stops responding then the primary replica marks this secondary replica as 'NOT SYNCHRONIZED' and proceeds.
When the secondary replica comes online it will be in a 'not synced' state and the replica will be marked as unhealthy until the primary can make it synchronous again
With the REQUIRED_SYNCHRONOUS_SECONDARIES_TO_COMMIT option the minimum number of synchronous commit mode secondary replicas must commit the transaction before the primary replica proceeds.
NOTE: If the minimum number of synchronous commit mode secondary replicas is not available then commits on the primary will fail!
ALTER AVAILABILITY GROUP supports the REQUIRED_SYNCHRONOUS_SECONDARIES_TO_COMMIT option.
We first create a numbers table with a clustered index and update statistics with fullscan:
DROP TABLE IF EXISTS dbo.Numbers1; CREATE TABLE dbo.Numbers1 ( NumberID int NOT NULL ); CREATE CLUSTERED INDEX ix_NumberID1 ON dbo.Numbers1(NumberID); WITH Pass0 as (select 1 as C union all select 1), --2 rows Pass1 as (select 1 as C from Pass0 as A, Pass0 as B),--4 rows Pass2 as (select 1 as C from Pass1 as A, Pass1 as B),--16 rows Pass3 as (select 1 as C from Pass2 as A, Pass2 as B),--256 rows Pass4 as (select 1 as C from Pass3 as A, Pass3 as B),--65536 rows Pass5 as (select 1 as C from Pass4 as A, Pass4 as B),--4,294,967,296 rows Tally as (select row_number() over(order by C) as Number from Pass5) INSERT dbo.Numbers1 (NumberID) select TOP(10000000) Number from Tally; UPDATE STATISTICS dbo.Numbers1 WITH FULLSCAN;
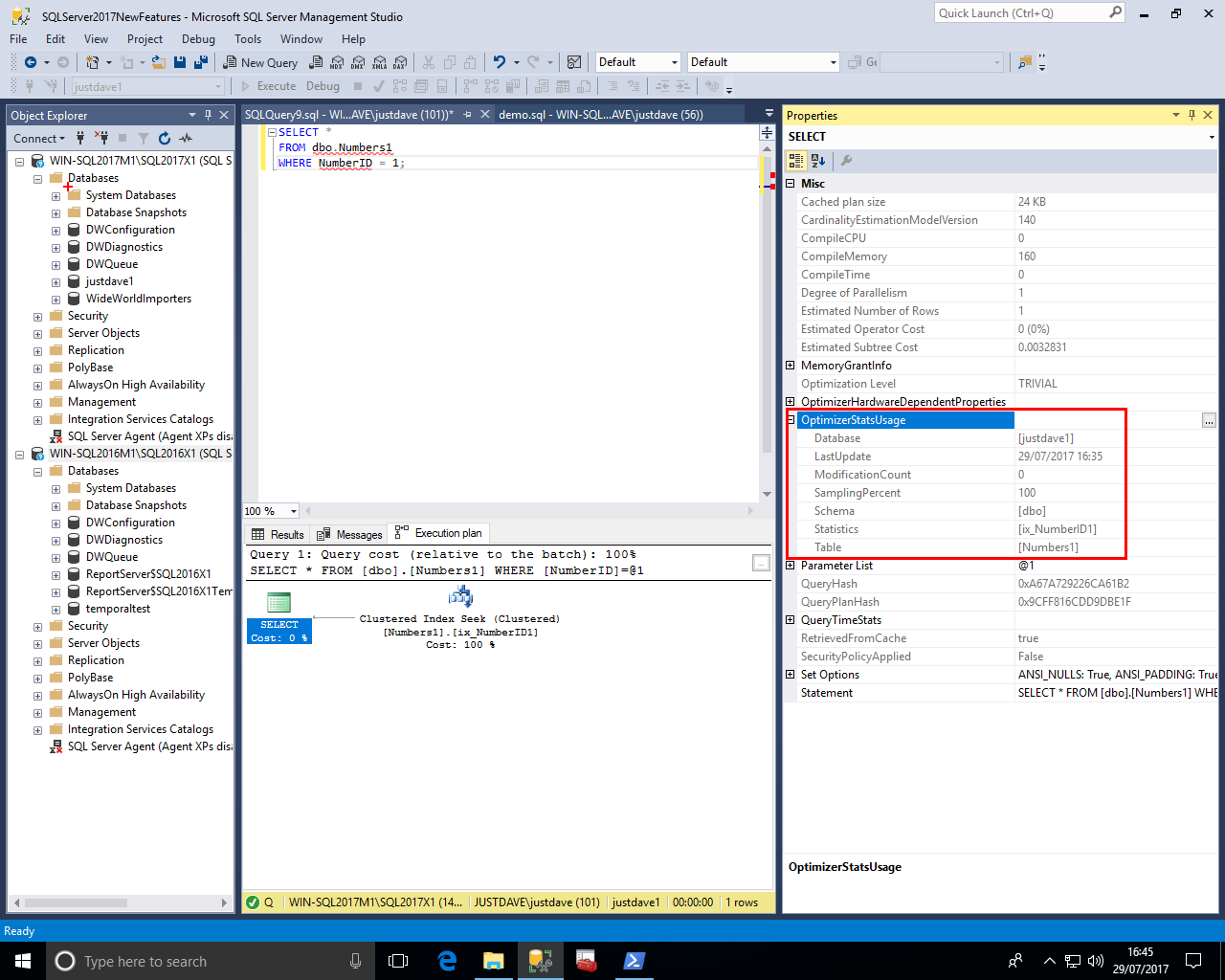
We then turn on Include Actual Execution Plan (or Estimated Execution Plan) and we see the properties for the root node of the query include the "OptimizerStatsUsage"
This includes "Modification Count", Last Update time, and the sampling percent used
The optimizer is now capable of interleaved execution, this means rather than optimization then execution we now:
This COULD give better optimization as the actual cardinality values are known by the optimizer
For SQL Server 2014 with Multi-Statement Table Valued Functions the number of rows procedure by the function was estimated as 1
For SQL Server 2016 this estimate was changed to 100
Having a fixed estimate does not always work hence in SQL Server 2017 the Multi-Statement Table Valued Function is fully executed i.e. materialzed and the actual number of rows produced is used for another round of optimization
We create our Numbers table with a clustered index
DROP TABLE IF EXISTS dbo.Numbers1; CREATE TABLE dbo.Numbers1 ( NumberID int NOT NULL ); CREATE CLUSTERED INDEX ix_NumberID1 ON dbo.Numbers1(NumberID); WITH Pass0 as (select 1 as C union all select 1), --2 rows Pass1 as (select 1 as C from Pass0 as A, Pass0 as B),--4 rows Pass2 as (select 1 as C from Pass1 as A, Pass1 as B),--16 rows Pass3 as (select 1 as C from Pass2 as A, Pass2 as B),--256 rows Pass4 as (select 1 as C from Pass3 as A, Pass3 as B),--65536 rows Pass5 as (select 1 as C from Pass4 as A, Pass4 as B),--4,294,967,296 rows Tally as (select row_number() over(order by C) as Number from Pass5) INSERT dbo.Numbers1 (NumberID) select TOP(1000) Number from Tally;
We then create a Multi-Statement Table Valued Function which returns a table containing the rows in our Numbers table which are greater than a given value
DROP FUNCTION IF EXISTS [dbo].[MSTVF_1];
CREATE FUNCTION [dbo].[MSTVF_1] (@i INT)
RETURNS @Out TABLE (NumberID INT)
AS
BEGIN
INSERT INTO @Out
(NumberID)
SELECT NumberID
FROM dbo.Numbers1
WHERE NumberID > @i
RETURN;
END;
We turn on Include Actual Execution Plan and execute the function with a value of 800 i.e. to produce 200 rows
We see that the estimated rows is 200 (NEW!) and the actual rows is 0 (same as for SQL Server 2016)
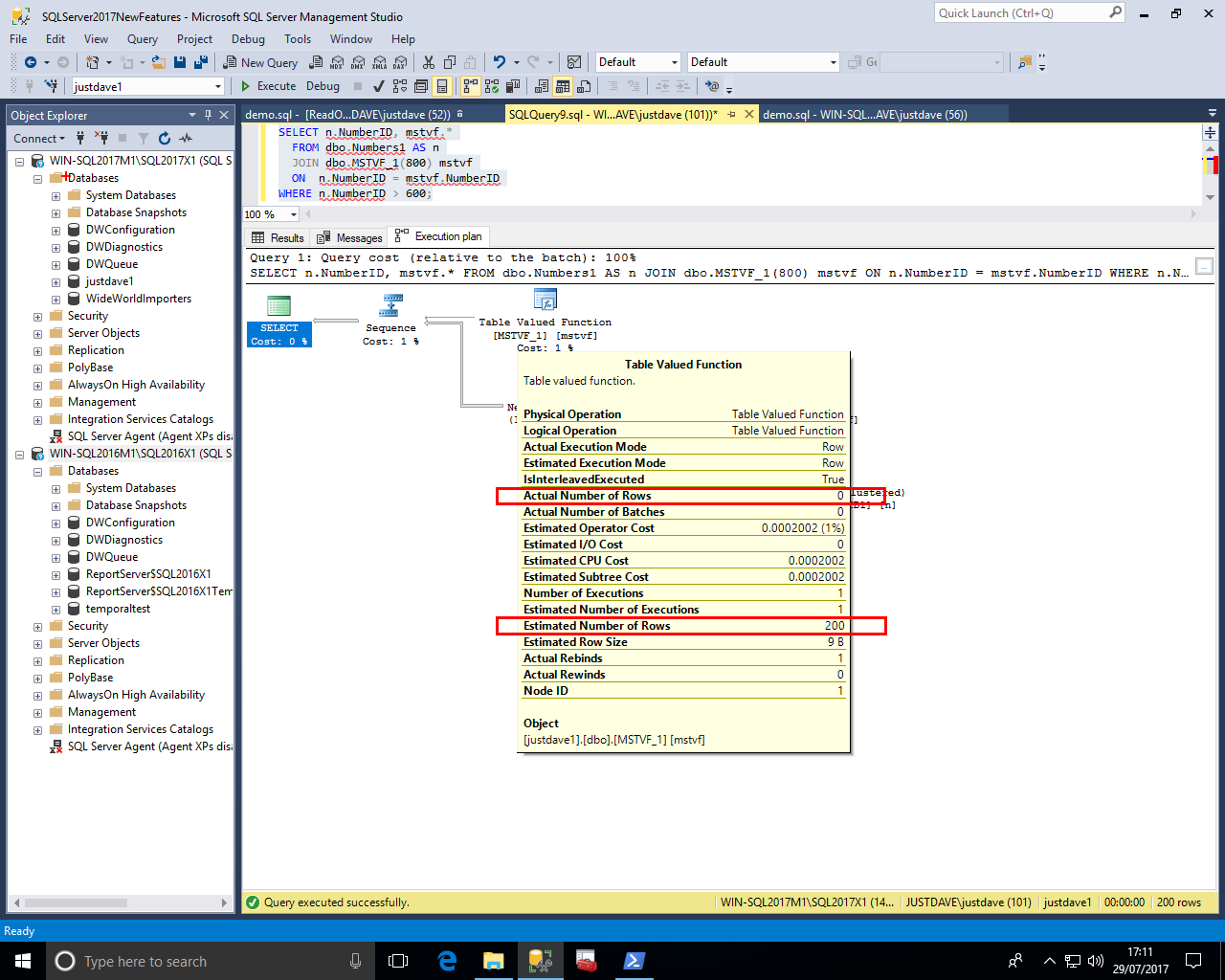
We execute the MSTVF again with a value of 700 i.e. to produced 300 rows
We see that the estimated rows is now 300 and the actual rows is 0
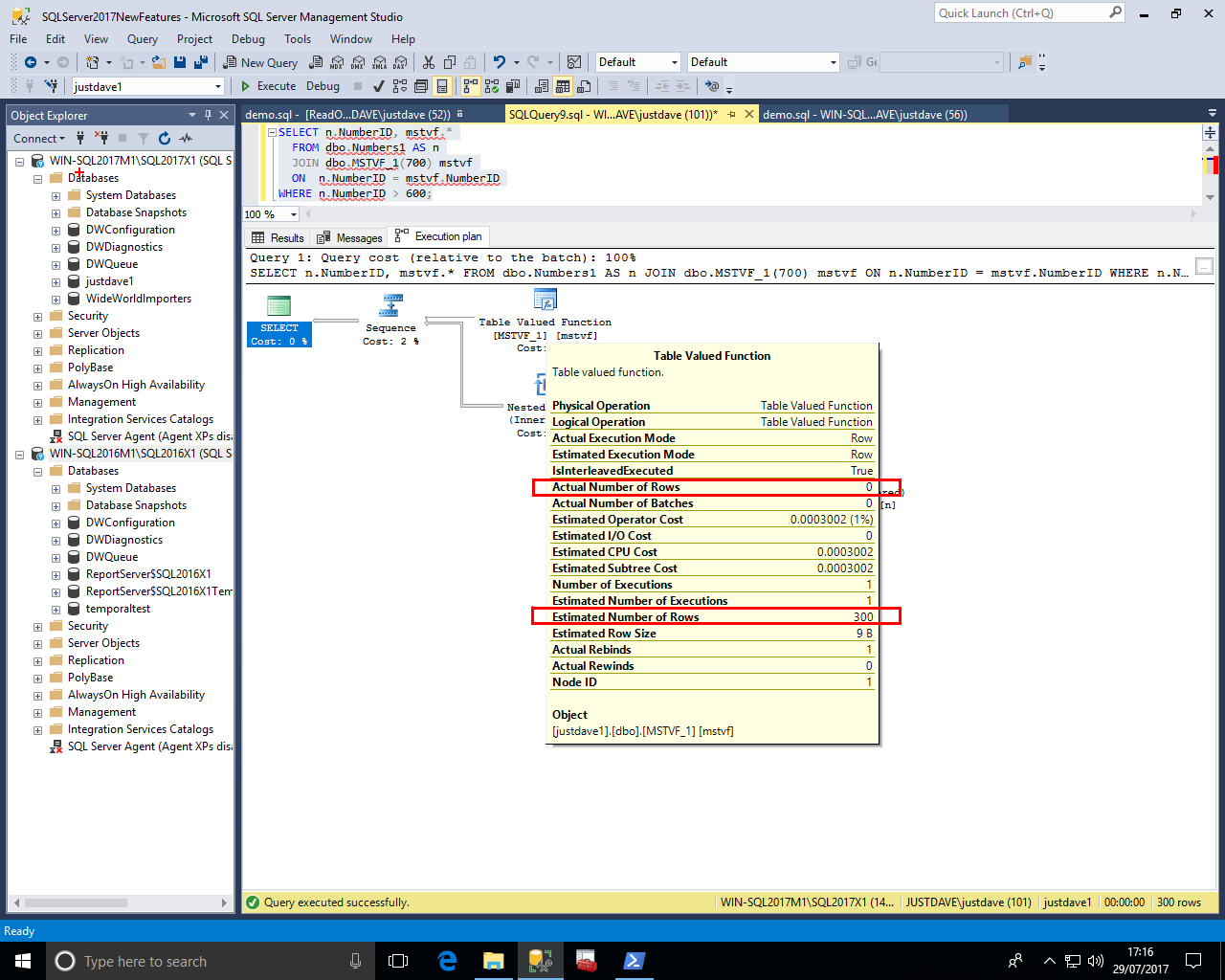
In this FIRST version of interleaved execution the MS-TVF statements must be read-only and not part of a data modification operation.
Also interleaved execution is not used if they are on the inside of a CROSS APPLY.
This feature requires NEW database compatability level 140
This is another form of interleaved execution
NOTE: SSMS 17 is required to be able to see the new Adaptive Join Operator in the plan.
Adaptive Join means the decision whether to use a hash join or nested loop join is DEFERRED until the first input table has been scanned
We have a Columnstore Index Scan used to provide rows for the hash join build phase.
This operator defines a threshold below which we switch to a nested loop join
A range of rows and associated costs is defined for both join types to determine the threshold where we switch to a nested loop join.
Once compiled, new executions are still adaptive based on the compiled adaptive join threshold and runtime (actual) number of rows flowing through the build phase of the Columnstore Index Scan.
NOTE: Additional memory is needed as if the nested loop join was a hash join.
There is a NEW extended event adaptive_join_skipped which tracks the reason why an AJ was not chosen
Query processing is:
We setup 2 Numbers tables
DROP TABLE IF EXISTS dbo.Numbers1; CREATE TABLE dbo.Numbers1 ( NumberID1 int NOT NULL, Quantity INT ); CREATE CLUSTERED COLUMNSTORE INDEX ix_NumberID1 ON dbo.Numbers1; WITH Pass0 as (select 1 as C union all select 1), --2 rows Pass1 as (select 1 as C from Pass0 as A, Pass0 as B),--4 rows Pass2 as (select 1 as C from Pass1 as A, Pass1 as B),--16 rows Pass3 as (select 1 as C from Pass2 as A, Pass2 as B),--256 rows Pass4 as (select 1 as C from Pass3 as A, Pass3 as B),--65536 rows Pass5 as (select 1 as C from Pass4 as A, Pass4 as B),--4,294,967,296 rows Tally as (select row_number() over(order by C) as Number from Pass5) INSERT dbo.Numbers1 (NumberID1,Quantity) select TOP(10) Number,1 from Tally; WITH Pass0 as (select 1 as C union all select 1), --2 rows Pass1 as (select 1 as C from Pass0 as A, Pass0 as B),--4 rows Pass2 as (select 1 as C from Pass1 as A, Pass1 as B),--16 rows Pass3 as (select 1 as C from Pass2 as A, Pass2 as B),--256 rows Pass4 as (select 1 as C from Pass3 as A, Pass3 as B),--65536 rows Pass5 as (select 1 as C from Pass4 as A, Pass4 as B),--4,294,967,296 rows Tally as (select row_number() over(order by C) as Number from Pass5) INSERT dbo.Numbers1 (NumberID1,Quantity) select TOP(100000) Number,2 from Tally; ALTER INDEX ix_NumberID1 ON dbo.Numbers1 REORGANIZE; DROP TABLE IF EXISTS dbo.Numbers2; CREATE TABLE dbo.Numbers2 ( NumberID2 int NOT NULL, ); CREATE NONCLUSTERED INDEX ix_NumberID2 ON [dbo].[Numbers2] ([NumberID2]); WITH Pass0 as (select 1 as C union all select 1), --2 rows Pass1 as (select 1 as C from Pass0 as A, Pass0 as B),--4 rows Pass2 as (select 1 as C from Pass1 as A, Pass1 as B),--16 rows Pass3 as (select 1 as C from Pass2 as A, Pass2 as B),--256 rows Pass4 as (select 1 as C from Pass3 as A, Pass3 as B),--65536 rows Pass5 as (select 1 as C from Pass4 as A, Pass4 as B),--4,294,967,296 rows Tally as (select row_number() over(order by C) as Number from Pass5) INSERT dbo.Numbers2 (NumberID2) select TOP(100000) Number from Tally; ALTER INDEX ix_NumberID2 ON dbo.Numbers2 REORGANIZE;
We then execute a query joins table Numbers1 to table Numbers2 where the Quantity is 1 i.e. pulling 10 rows from the first table Numbers1
We get an adaptive join operator with 3 input even though there are only 2 tables in the join
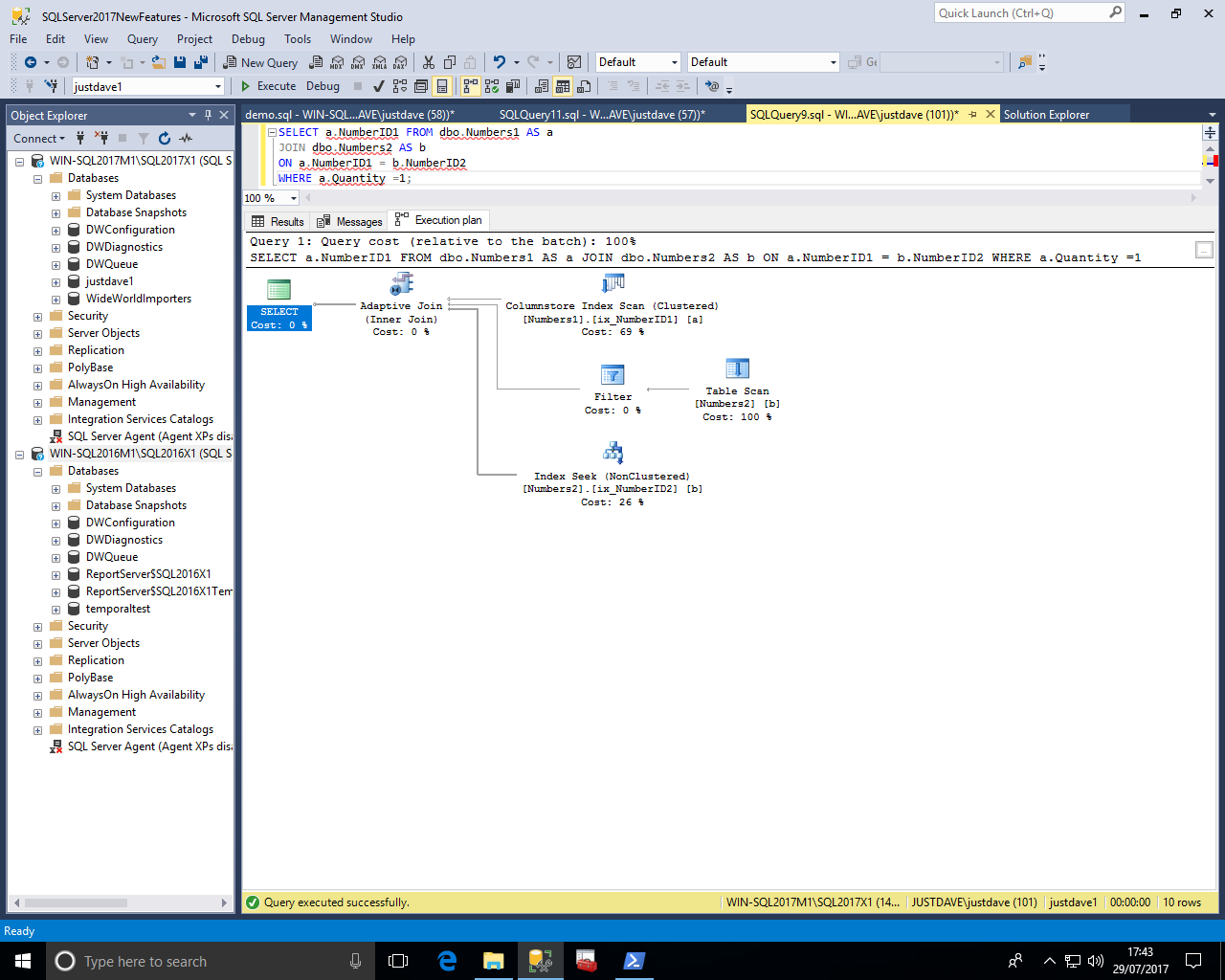
If we look at the Adaptive Join operator we see:
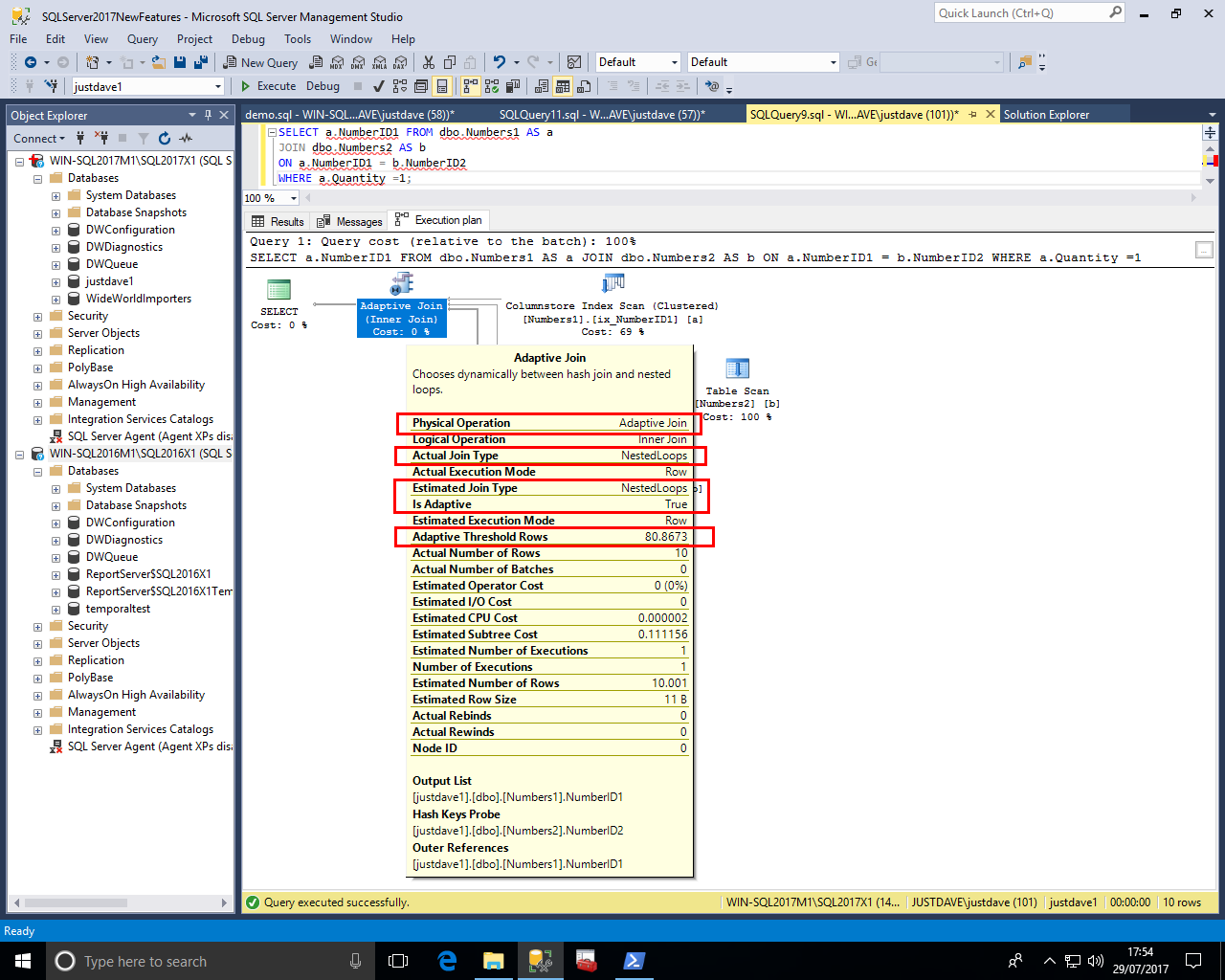
We can compare this against the SQL Server 2016 SP1 CU3 nexted loop join operator for reference
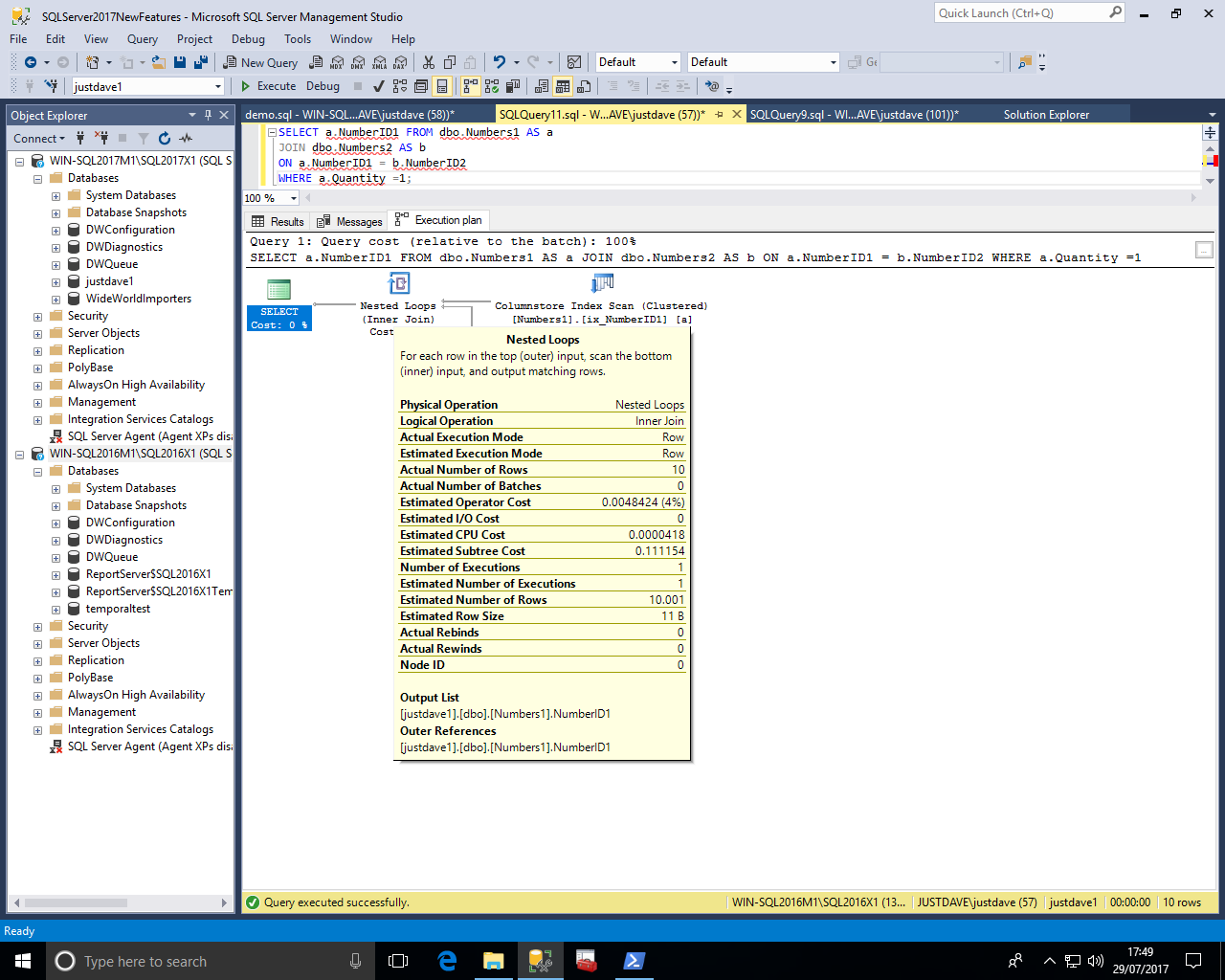
Back to the Adaptive Join, in the first branch we see a COLUMNSTORE index scan on the first table in batch mode with an "Actual Execution Mode" and "Actual/Estimated Rows" being 10 but "Estimated Number of Rows to be Read" as the whole table
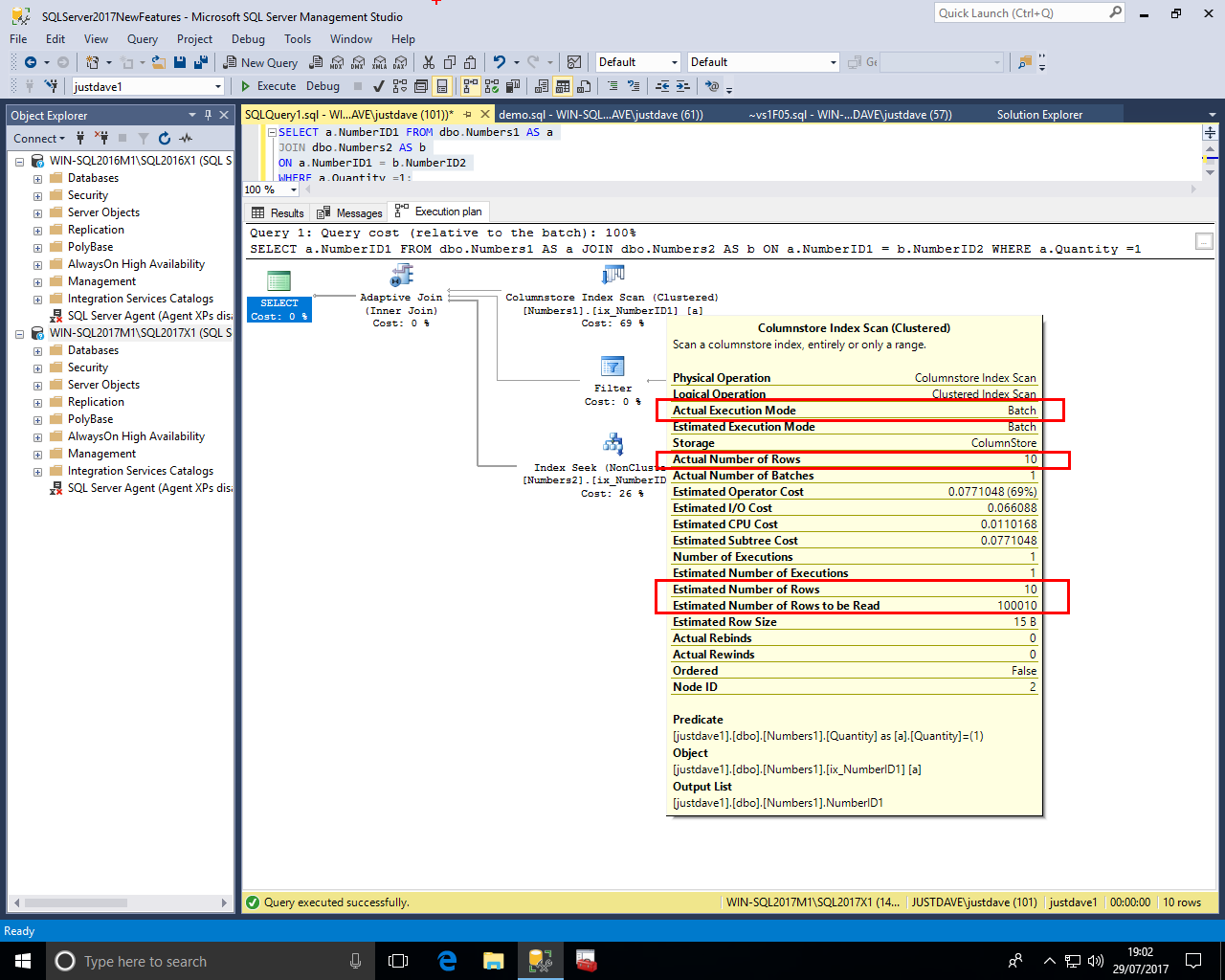
In the second branch we see a table scan on the second table with No "Actual Execution Mode" and "Actual Number of Rows" 0
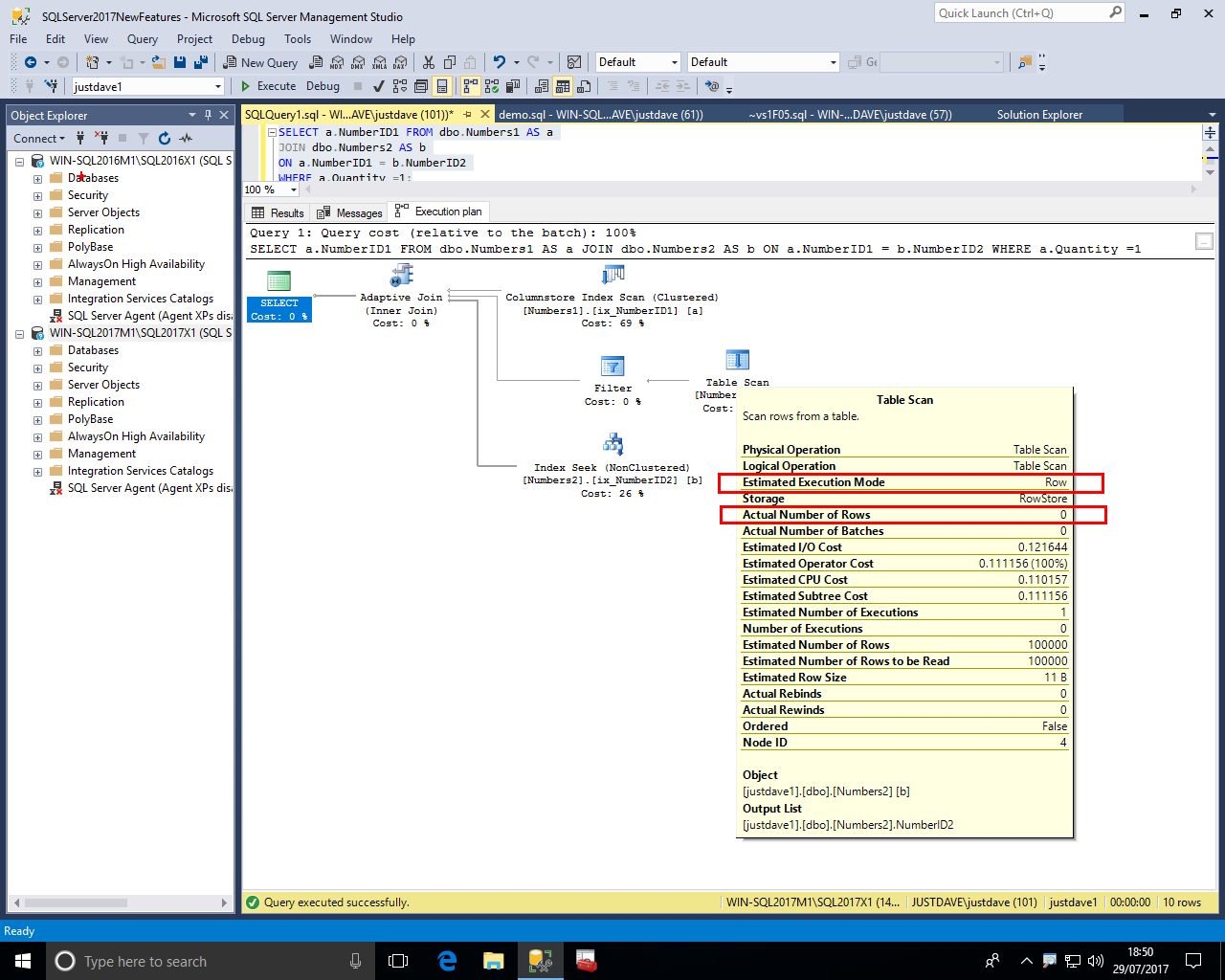
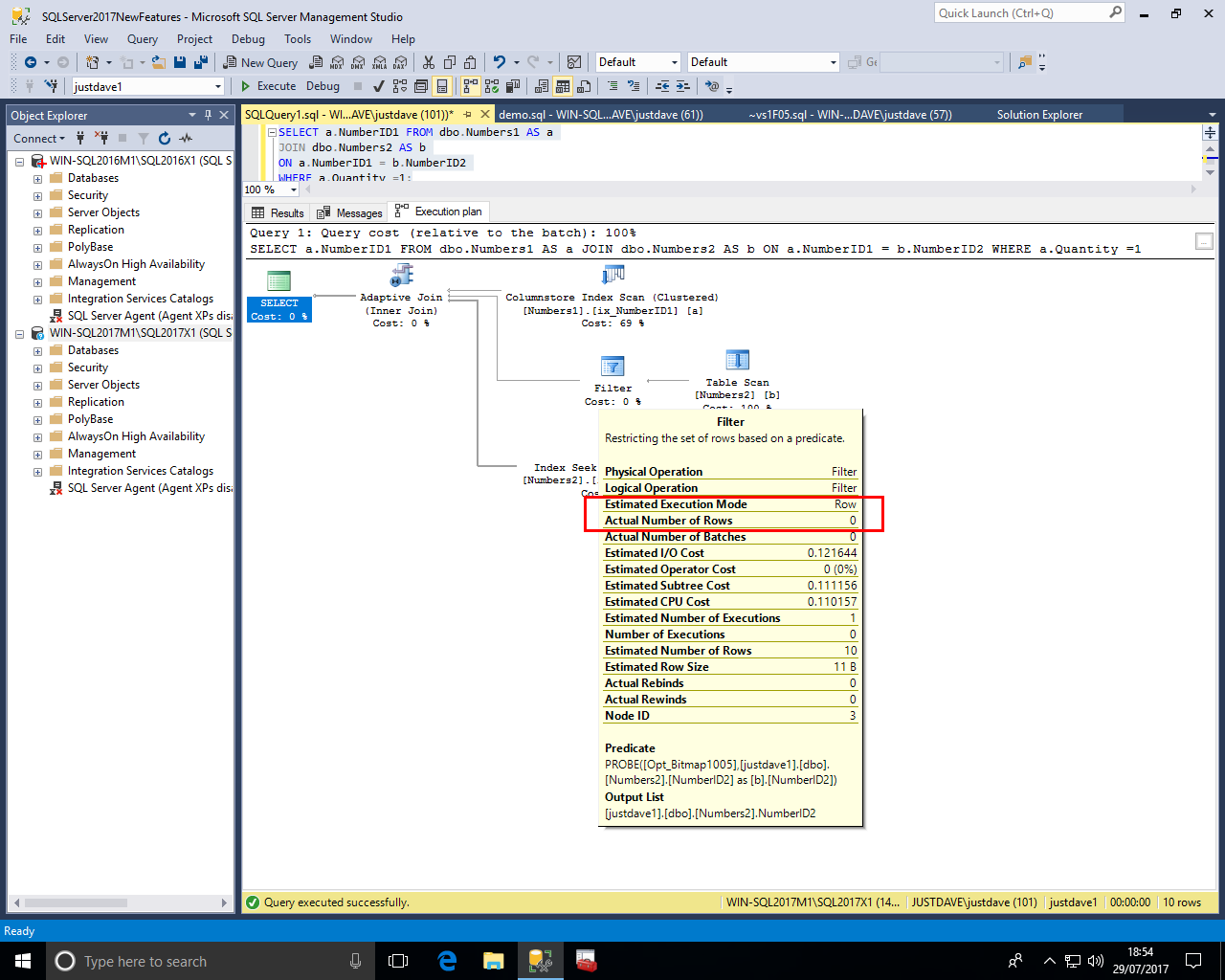
In the second branch we also see a filter operation with No "Actual Execution Mode" and "Actual Number of Rows" 0
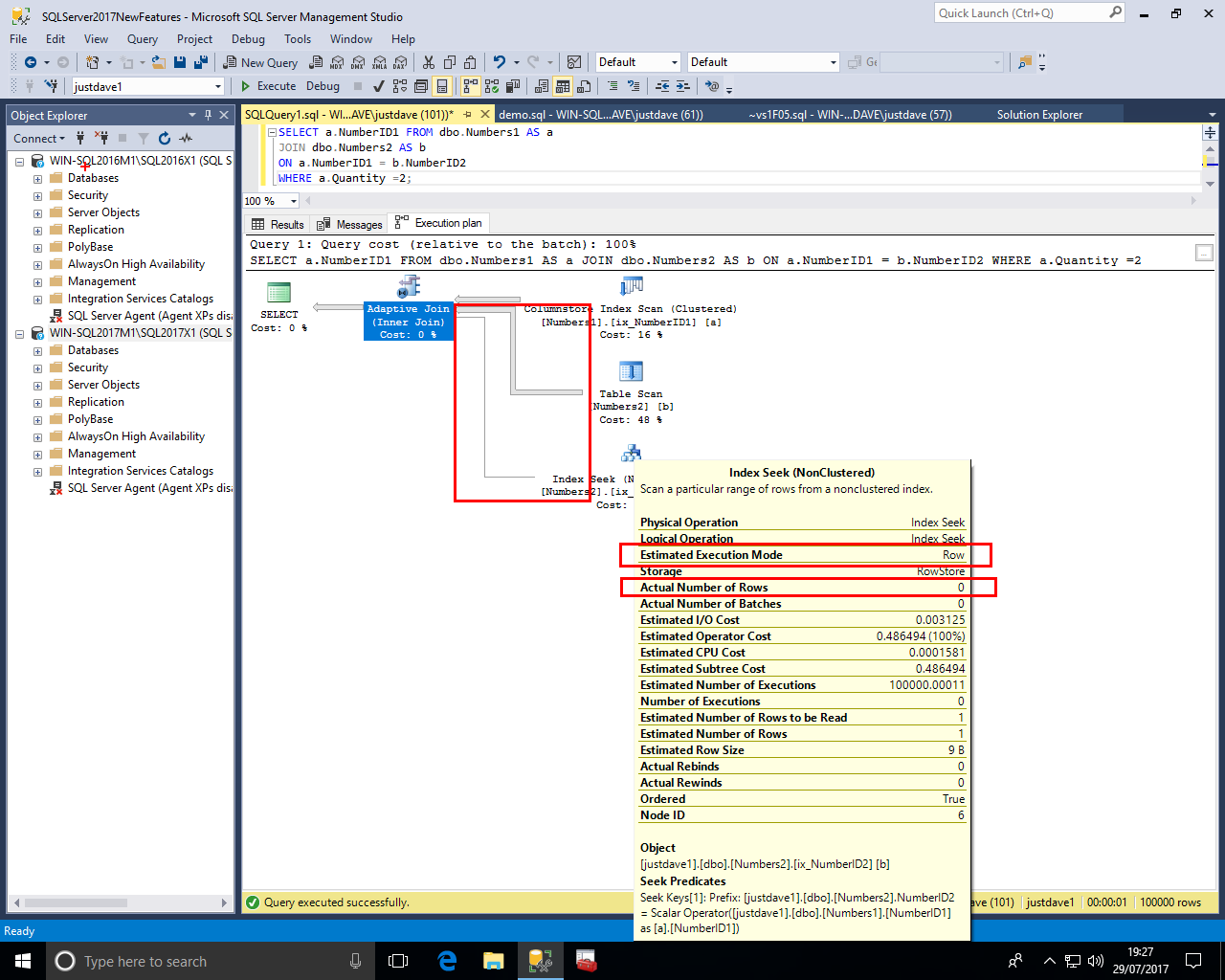
In the third branch we see a Nonclusteed Index Seek in Row Mode with an "Actual Execution Mode" and "Number of Rows Read"/"Actual Number of Rows" 10
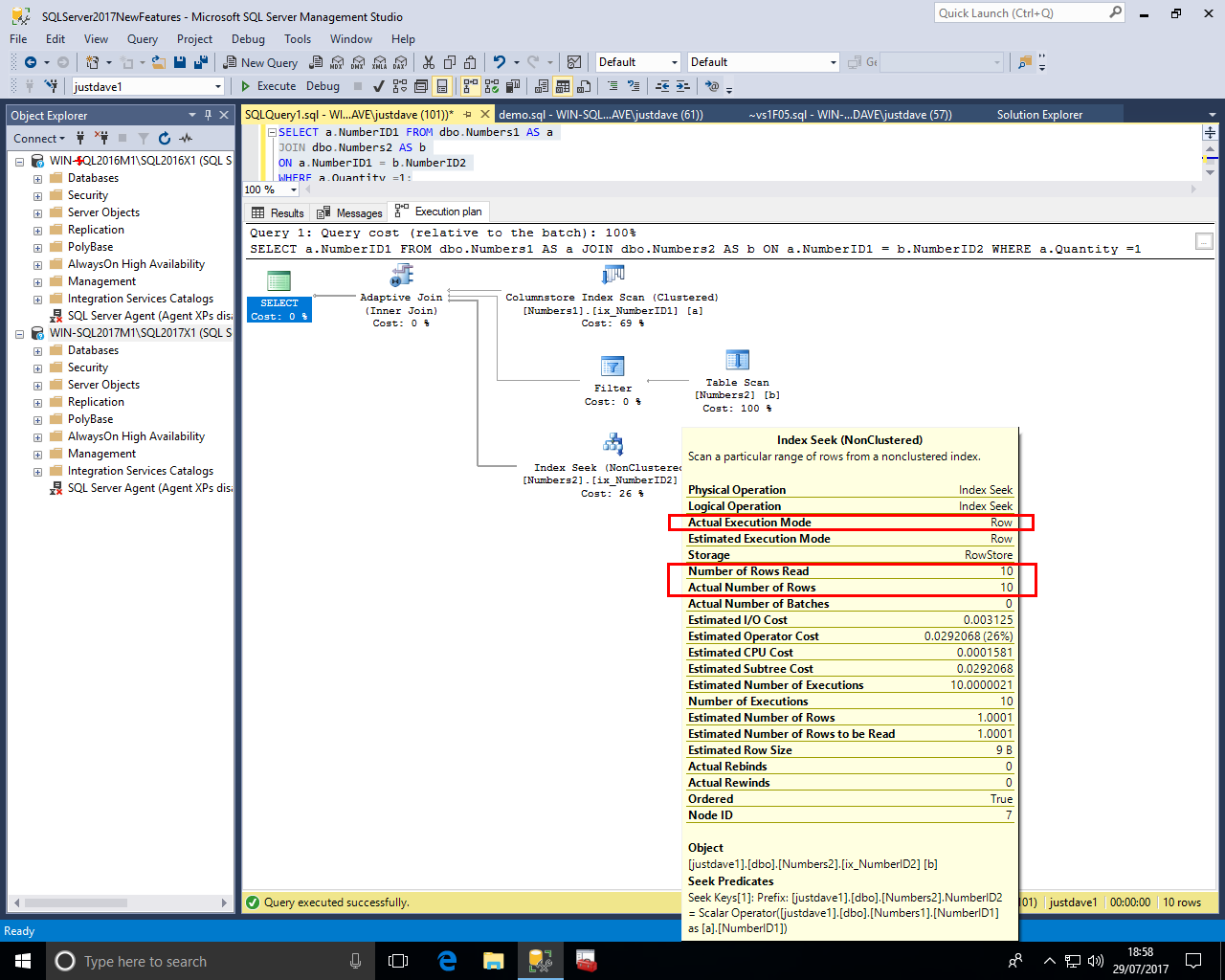
This makes sense at the join was done as a nested loop join hence the 3rd branch of the join rather than the 2nd branch of the join provided the query results
We rerun the query where Quantity is 2 i.e. pulling 100,000 rows from the first table Numbers1
Again we get an Adaptive Join but the "Actual Join Type" is "Hash Match"
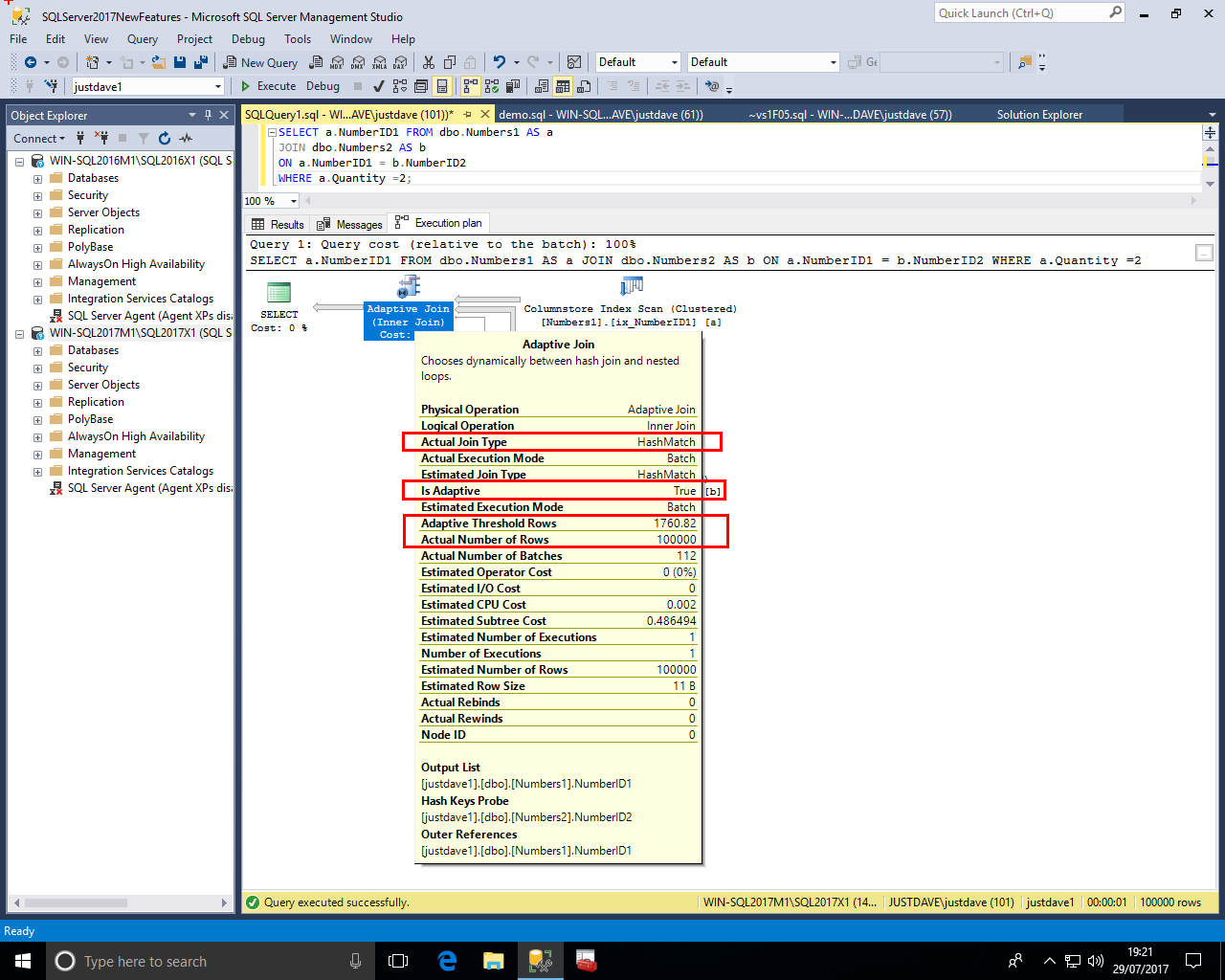
The Table Scan now has a "Actual Execution Mode" and "Number of Rows Read"/"Actual Number of Rows" 100000
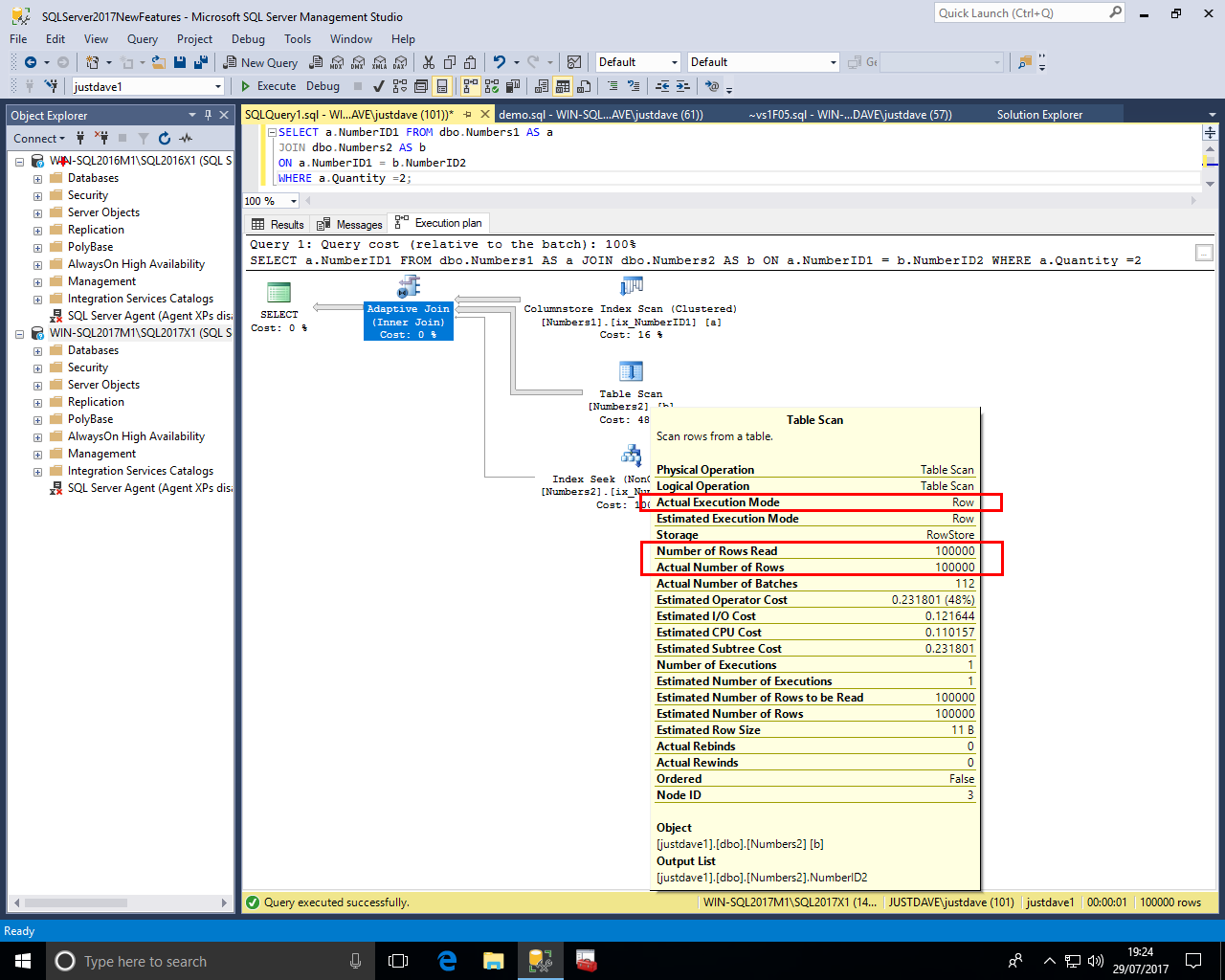
The Non Clustered Index Seek now has No "Actual Execution Mode" and "Actual Number of Rows" 0
Also notice the thickness of the arrows which shows the rows are coming from the Table Scan rather than the Non Clustered Index Seek
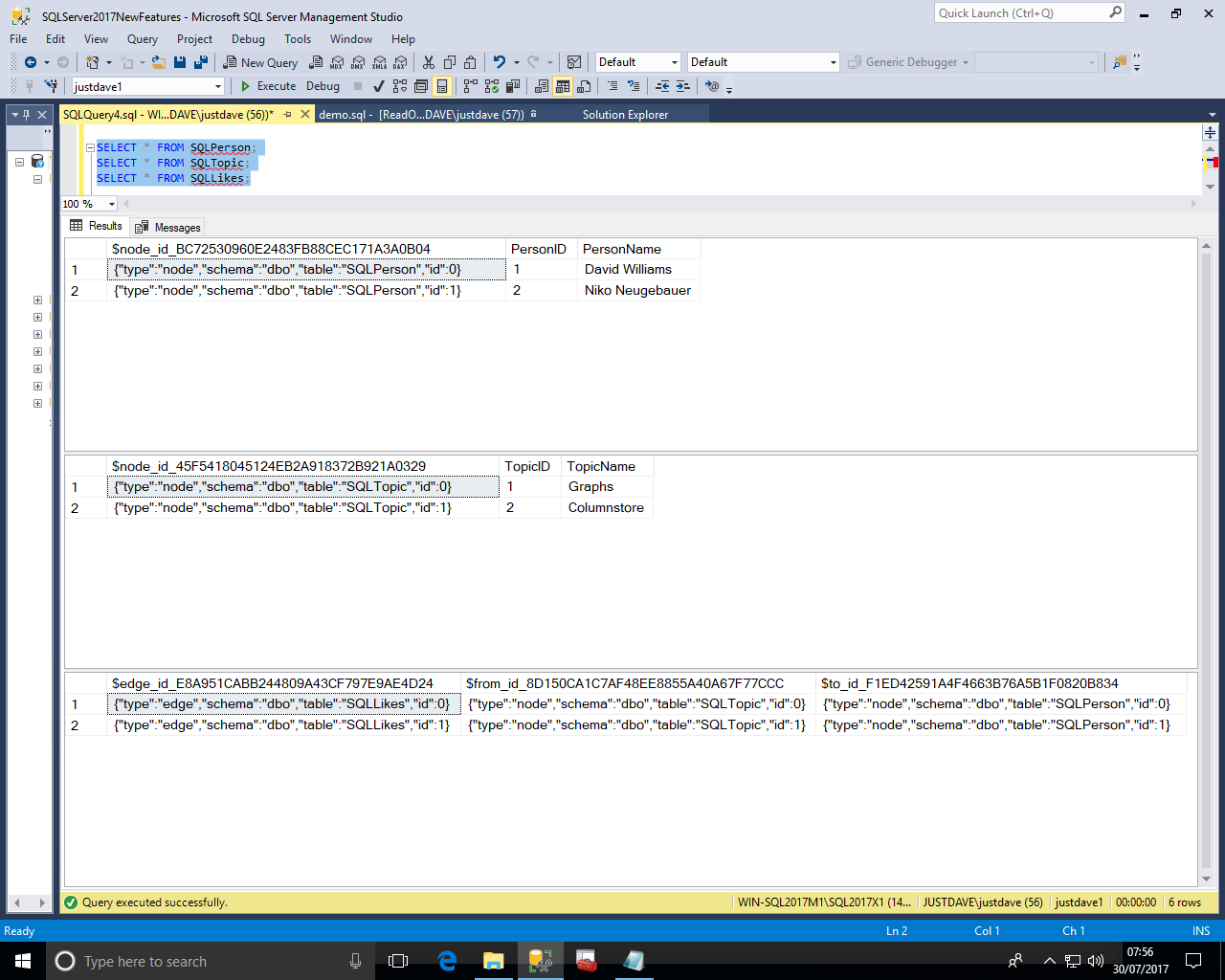
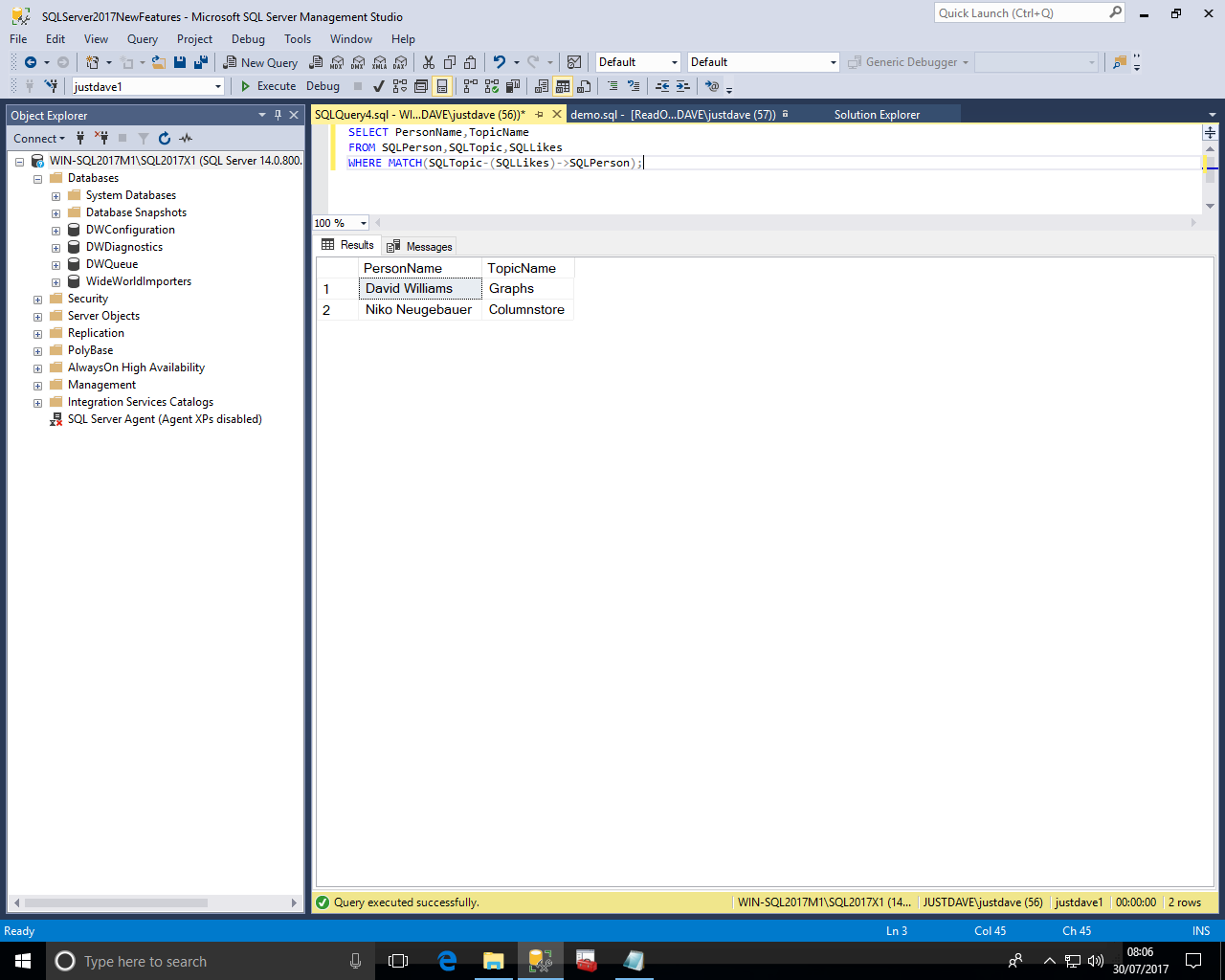
SQL Server now includes Graph Processing capabailities
We create node and edge table

First we create a database
CREATE DATABASE justdave1; USE justdave1;
We then create tables SQLPerson and SQLTopic as nodes with "CREATE TABLE...AS NODE"
DROP TABLE IF EXISTS SQLPerson; CREATE TABLE SQLPerson ( [PersonID] [int] IDENTITY(1,1) NOT NULL, [PersonName] [varchar](100) NULL ) AS NODE; DROP TABLE IF EXISTS SQLTopic; CREATE TABLE SQLTopic ( [TopicID] [int] IDENTITY(1,1) NOT NULL, [TopicName] [varchar](100) NULL ) AS NODE;
The node tables contains 1 pseudo column:
NOTE:
We then create table SQLLikes as the edge with "CREATE TABLE...AS EDGE"
DROP TABLE IF EXISTS SQLLikes; CREATE TABLE SQLLikes AS EDGE;
The edge table contains 3 pseudo columns:
We them populate the node tables
INSERT INTO SQLPerson(PersonName) VALUES ('David Williams');
INSERT INTO SQLTopic(TopicName) VALUES ('Graphs');
INSERT INTO SQLPerson(PersonName) VALUES ('Niko Neugebauer');
INSERT INTO SQLTopic(TopicName) VALUES ('Columnstore');
We then need to populate the edge table to link the relevant node records in each table
We add 2 records with a single comma seperated INSERT statement
Note the need to
INSERT into SQLLikes ($to_id,$from_id) values ( (select $node_id from dbo.SQLPerson where PersonName = 'David Williams' ), (select $node_id from dbo.SQLTopic where TopicName='Graphs' ) ), ( (select $node_id from dbo.SQLPerson where PersonName = 'Niko Neugebauer' ), (select $node_id from dbo.SQLTopic where TopicName='Columnstore' ) );
When we query the table we see that the real column names for the psuedo columns have an appended value (GUID?)
Also the node_id values are actually JSON documents(!) which contain schemaname,tablename and unique id within the table, this makes node_id values unique across the database allowing nodes from different tables to be in the same edge table!
SELECT * FROM SQLPerson; SELECT * FROM SQLTopic; SELECT * FROM SQLLikes;
We can then use operators to perform graph type queries on the tables
The first operator is MATCHES which says there is an edge between 2 nodes in a given direction, hence a SQLPerson "SQLLikes" a "SQLTopic".
SELECT PersonName,TopicName FROM SQLPerson,SQLTopic,SQLLikes WHERE MATCH(SQLTopic-(SQLLikes)->SQLPerson);
The expiration date on evaluation copies of CTPs is based on 180 days from Build Date rather then Installation date
We tested with Visual Studio 2015
First we build a CLR assembly with 2 user defined functions
File->New->Project->Database->SQL Server->Visual C# SQL CLR Database Project
Call the Project VerTest
Project->Add New Item->SQL CLR C#->SQL CLR# User Defined Function,call the Function DoubleMe1,then Click Add
Change the code for the function to
public partial class UserDefinedFunctions
{
public const double SALES_TAX = .086;
[SqlFunction()]
public static SqlDouble DoubleMe1(SqlDouble originalAmount)
{
SqlDouble doubleAmount = originalAmount * 2;
return doubleAmount;
}
[SqlFunction(IsDeterministic = true)]
[return: SqlFacet(MaxSize = -1)]
public static SqlString CLRInfo1()
{
SqlString CLRInfo1;
string CLRInfo1S = System.Environment.Version.ToString();
CLRInfo1 = (SqlString)(CLRInfo1S as string);
return CLRInfo1;
}
}
Choose Build->Build Solution
A DLL VerTest.dll will be created in a folder similar to C:\Users\David\Documents\Visual Studio 2015\Projects\VerTest\VerTest\bin\Debug
We then copy the assembly to /varopt/udr on the Linux Machine containing the database server
We then use SSMS to create the assembly and functions
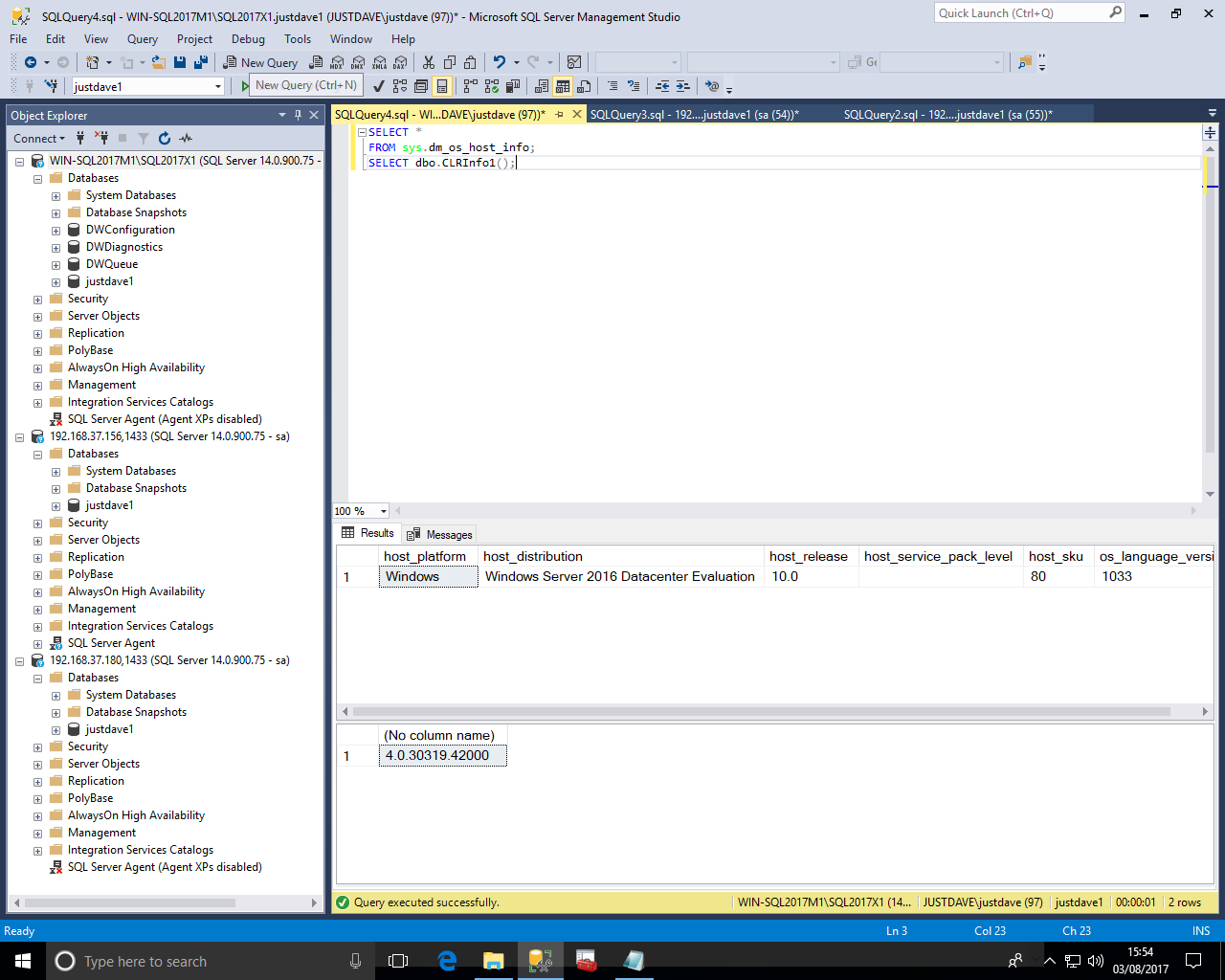
sp_configure 'clr enabled',1; RECONFIGURE; CREATE DATABASE justdave1; USE justdave1; ALTER DATABASE current SET TRUSTWORTHY ON; DROP FUNCTION IF EXISTS [dbo].[DoubleMe1]; DROP FUNCTION IF EXISTS [dbo].[CLRInfo1]; DROP ASSEMBLY IF EXISTS VerTest; -- Windows version CREATE ASSEMBLY VerTest FROM 'C:\x\VerTest.dll' WITH PERMISSION_SET = SAFE; -- Linux version CREATE ASSEMBLY VerTest FROM 'C:\var\opt\udr\VerTest.dll' WITH PERMISSION_SET = SAFE; CREATE FUNCTION [dbo].[DoubleMe1] (@originalAmount as float) RETURNS float AS EXTERNAL NAME [VerTest].[UserDefinedFunctions].[DoubleMe1]; SELECT dbo.DoubleMe1(3); CREATE FUNCTION [dbo].[CLRInfo1] () RETURNS NVARCHAR(MAX) AS EXTERNAL NAME [VerTest].[UserDefinedFunctions].[CLRInfo1]; SELECT dbo.CLRInfo1();
Windows returns
Redhat Linux 7.4 returns
Ubuntu Linux 16.04 returns
We then extend the code above to add function CLRInfo2() which uses registry calls to get the installed .NET Framework versions.
using System;
using System.Data;
using System.Data.SqlClient;
using System.Data.SqlTypes;
using System.Globalization;
using Microsoft.Win32;
using Microsoft.SqlServer.Server;
public partial class UserDefinedFunctions
{
public const double SALES_TAX = .086;
[SqlFunction()]
public static SqlDouble DoubleMe1(SqlDouble originalAmount)
{
SqlDouble doubleAmount = originalAmount * 2;
return doubleAmount;
}
[SqlFunction(IsDeterministic = true)]
[return: SqlFacet(MaxSize = -1)]
public static SqlString CLRInfo1()
{
SqlString CLRInfo1;
string CLRInfo1S = System.Environment.Version.ToString();
CLRInfo1 = (SqlString)(CLRInfo1S as string);
return CLRInfo1;
}
public static SqlString CLRInfo2()
{
SqlString CLRInfo2="";
string CLRInfo2S="";
string path = @"SOFTWARE\Microsoft\NET Framework Setup\NDP";
RegistryKey installed_versions = Registry.LocalMachine.OpenSubKey(path);
string[] version_names = installed_versions.GetSubKeyNames();
for (int i = 1; i <= version_names.Length - 1; i++)
{
string temp_name1 = (string) installed_versions.OpenSubKey(version_names[i]).GetValue("SP","");
string temp_name2;
if (temp_name1.Equals(""))
{
temp_name2 = "Microsoft .NET Framework " + version_names[i].ToString();
}
else
{
temp_name2 = "Microsoft .NET Framework " + version_names[i].ToString() + " SP" + temp_name1;
}
if (i==1)
{
CLRInfo2S = CLRInfo2S + temp_name2;
} else
{
CLRInfo2S = CLRInfo2S + "," + temp_name2;
}
}
CLRInfo2 = (SqlString)(CLRInfo2S as string);
return CLRInfo2;
}
}
Choose Build->Build Solution
A DLL VerTest.dll will be created in a folder similar to C:\Users\David\Documents\Visual Studio 2015\Projects\VerTest\VerTest\bin\Debug
We then drop the previous functions/assembly
DROP FUNCTION IF EXISTS [dbo].[DoubleMe1]; DROP FUNCTION IF EXISTS [dbo].[CLRInfo1]; DROP FUNCTION IF EXISTS [dbo].[CLRInfo2]; DROP ASSEMBLY IF EXISTS VerTest;
We then copy the dll in place and create the new assembly/functions and call the new function CLRInfo2().
-- Windows version CREATE ASSEMBLY VerTest FROM 'C:\x\VerTest.dll' WITH PERMISSION_SET = EXTERNAL_ACCESS; -- Linux version CREATE ASSEMBLY VerTest FROM 'C:\var\opt\udr\VerTest.dll' WITH PERMISSION_SET = EXTERNAL_ACCESS; CREATE FUNCTION [dbo].[CLRInfo2] () RETURNS NVARCHAR(MAX) AS EXTERNAL NAME [VerTest].[UserDefinedFunctions].[CLRInfo2]; SELECT dbo.CLRInfo2();
This work on Windows
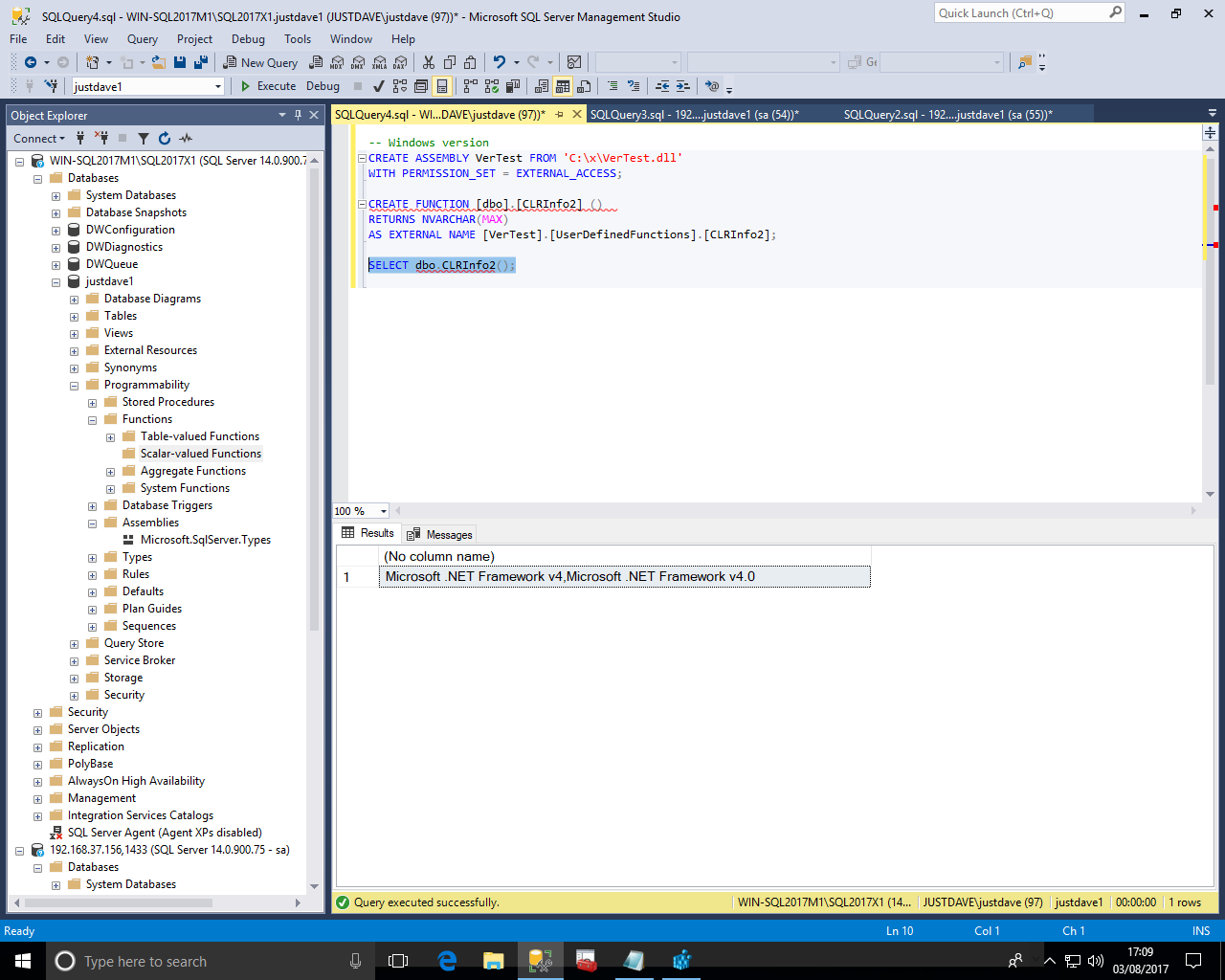
But fails on Linux as SQL Server 2017 RC2 on Linux can only load SAFE assemblies!
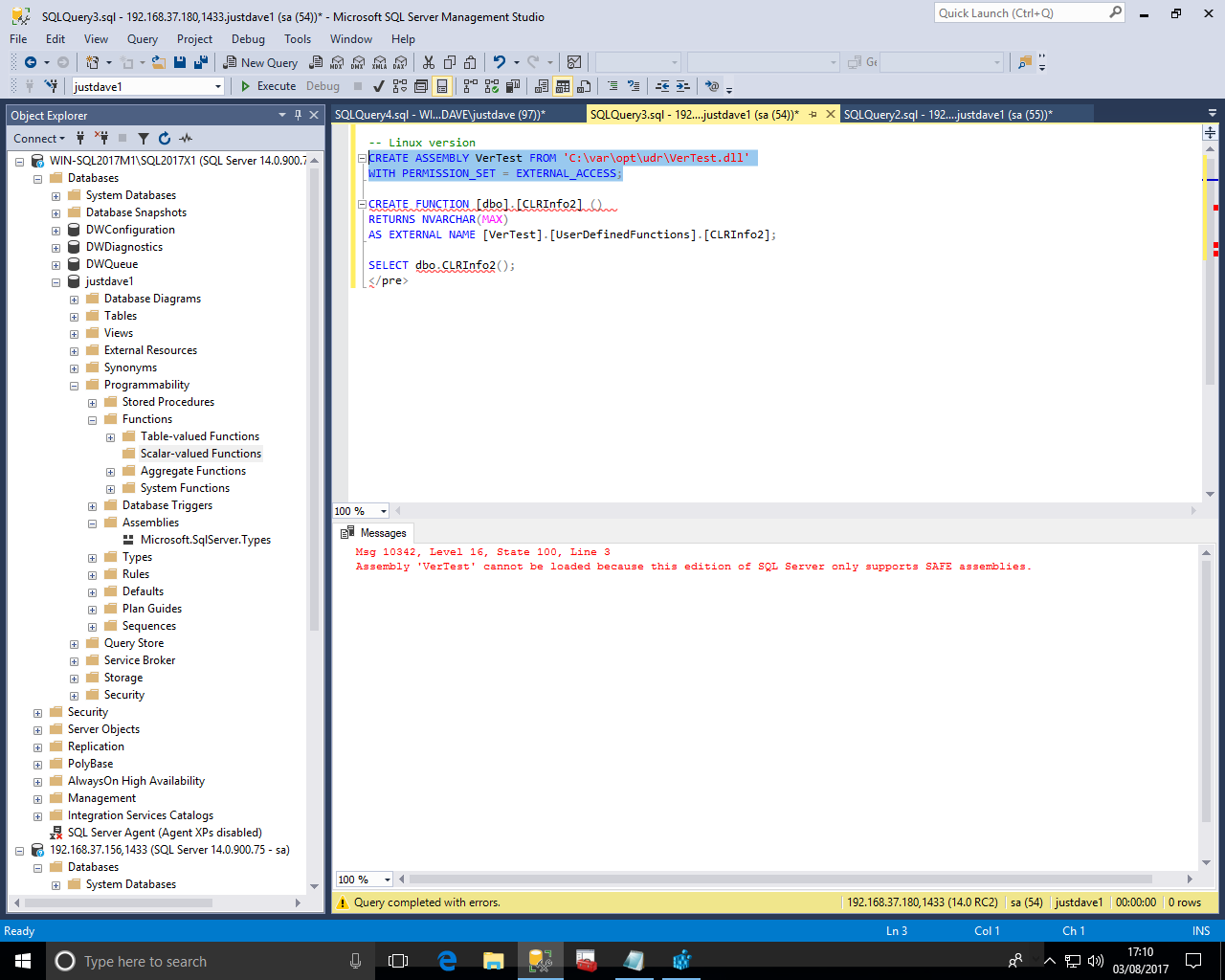
We then switch to Visual Studio 2017
First we start Visual Studio and check for any available updates under the flag with the yellow background and notifications tab.
Note this may launch the Visual Studio Installer which itself needs updating and fails to update as it cannot write to the Installer binary!
Retrying worked for me!
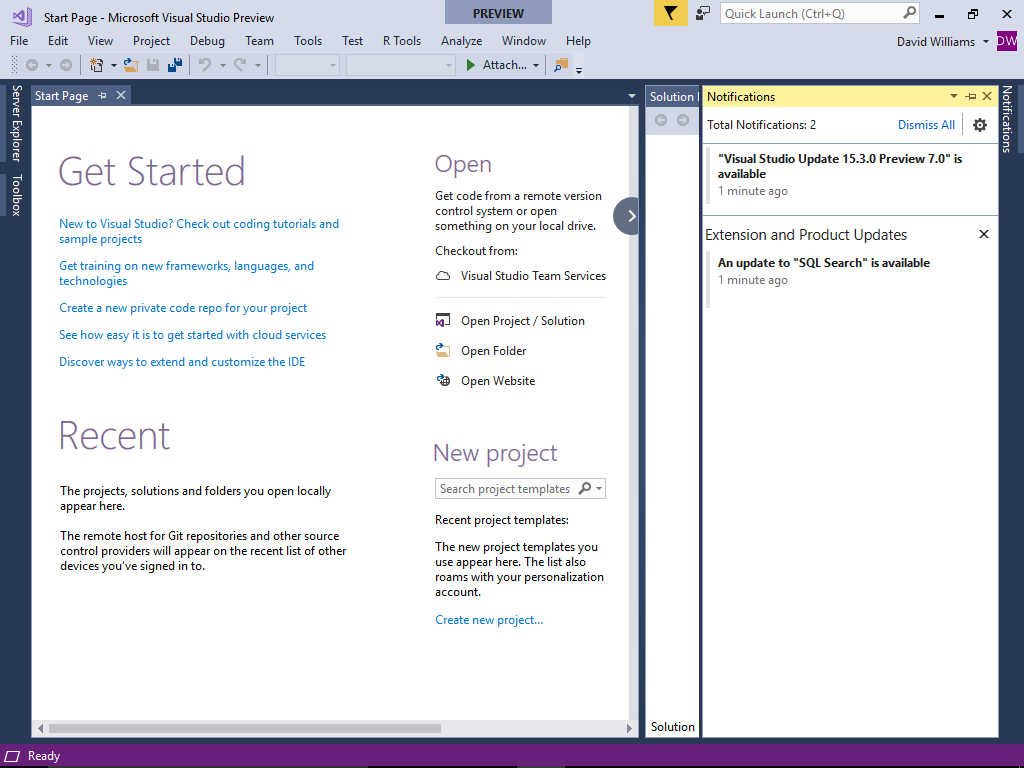
First we use the "Visual Studio Installer" from the start menu to check that the workload ".NET Core cross-platform development" is installed
If not select the workload, click Modify and follow instructions
First we build a CLR assembly with a new user defined function
File->New->Project->Database->SQL Server->Visual C# SQL CLR Database Project
Call the Project Ver2Test
Project->Add New Item->SQL CLR C#->SQL CLR# User Defined Function,call the Function CLRInfo3,then Click Add
Change the code for the function to
using System;
using System.Data;
using System.Data.SqlClient;
using System.Data.SqlTypes;
using System.Reflection;
using Microsoft.SqlServer.Server;
public partial class UserDefinedFunctions
{
public static SqlString CLRInfo3()
{
SqlString CLRInfo3;
string CLRInfo3S;
var appDomainType = typeof(object).GetTypeInfo().Assembly.GetType("System.AppDomain");
var currentDomain = appDomainType.GetProperty("CurrentDomain").GetValue(null);
var deps = appDomainType.GetMethod("GetData").Invoke(currentDomain, new[] { "FX_DEPS_FILE" });
if (deps == null)
{
CLRInfo3S = "(No deps method)";
}
else
{
var deps2 = appDomainType.GetMethod("GetCoreClrVersionImpl");
if (deps2 == null)
{
CLRInfo3S = "(No GetCoreClrVersionImpl)";
}
else
{
// CLRInfo3S = GetCoreClrVersionImpl(deps.ToString());
CLRInfo3S = (string) deps2.Invoke(currentDomain, new[] { deps.ToString() });
}
}
CLRInfo3 = (SqlString)(CLRInfo3S as string);
return CLRInfo3;
}
}
Choose Build->Build Solution
A DLL Ver2Test.dll will be created in a folder similar to C:\Users\David\Documents\Visual Studio 2017\Projects\Ver2Test\Ver2Test\bin\Debug
We copy the assembly in place and create the assembly/functions again
-- Windows version CREATE ASSEMBLY VerTest FROM 'C:\x\VerTest.dll' WITH PERMISSION_SET = EXTERNAL_ACCESS; -- Linux version CREATE ASSEMBLY Ver2Test FROM 'C:\var\opt\udr\Ver2Test.dll' WITH PERMISSION_SET = SAFE; CREATE FUNCTION [dbo].[CLRInfo3] () RETURNS NVARCHAR(MAX) AS EXTERNAL NAME [Ver2Test].[UserDefinedFunctions].[CLRInfo3]; SELECT dbo.CLRInfo3();
We get the following so this is not .NET core
We change the function to look what types are available
using System;
using System.Data;
using System.Data.SqlClient;
using System.Data.SqlTypes;
using System.Reflection;
using Microsoft.SqlServer.Server;
public partial class UserDefinedFunctions
{
public static SqlString CLRInfo3()
{
SqlString CLRInfo3 = null;
string CLRInfo3S = "4.7";
System.Type CLRInfo3T = Type.GetType("System.Web.Caching.CacheInsertOptions, System.Web, Version=4.0.0.0, Culture=neutral, PublicKeyToken=b03f5f7f11d50a3a", false);
if (CLRInfo3T == null)
{
CLRInfo3S = "4.6.2";
CLRInfo3T = Type.GetType("System.Security.Cryptography.AesCng, System.Core, Version=4.0.0.0, Culture=neutral, PublicKeyToken=b77a5c561934e089", false);
}
if (CLRInfo3T == null)
{
CLRInfo3S = "4.6.1";
CLRInfo3T = Type.GetType("System.Data.SqlClient.SqlColumnEncryptionCngProvider, System.Data, Version=4.0.0.0, Culture=neutral, PublicKeyToken=b77a5c561934e089", false);
}
if (CLRInfo3T == null)
{
CLRInfo3S = "4.6.0";
CLRInfo3T = Type.GetType("System.AppContext, mscorlib, Version=4.0.0.0, Culture=neutral, PublicKeyToken=b77a5c561934e089", false);
}
if (CLRInfo3T == null)
{
CLRInfo3S = "(Unknown)";
}
else
{
CLRInfo3S = ".Net Framework " + CLRInfo3S;
}
CLRInfo3 = (SqlString)(CLRInfo3S as string);
return CLRInfo3;
}
}
We now copy the DLL in place and create the assembly/function
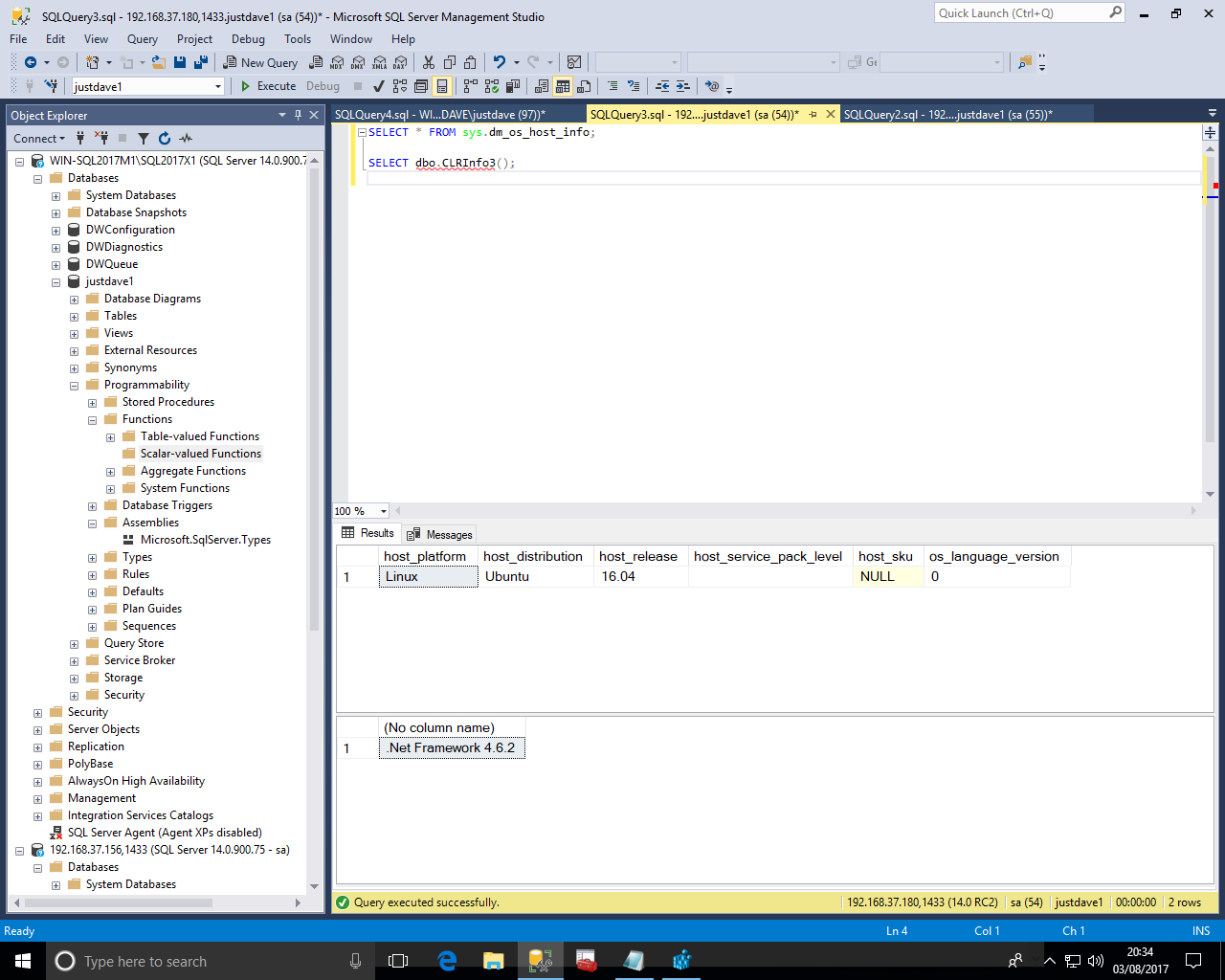
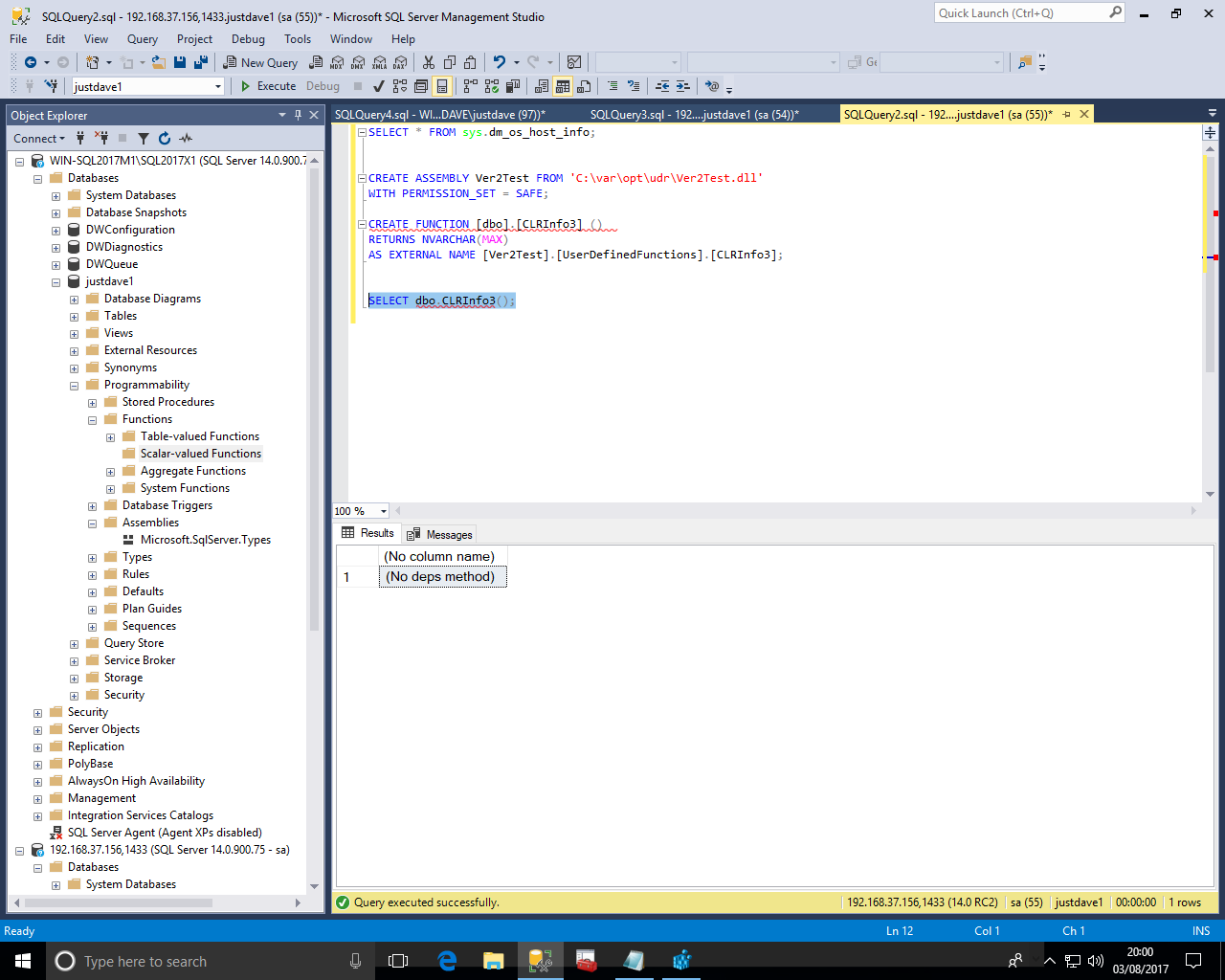
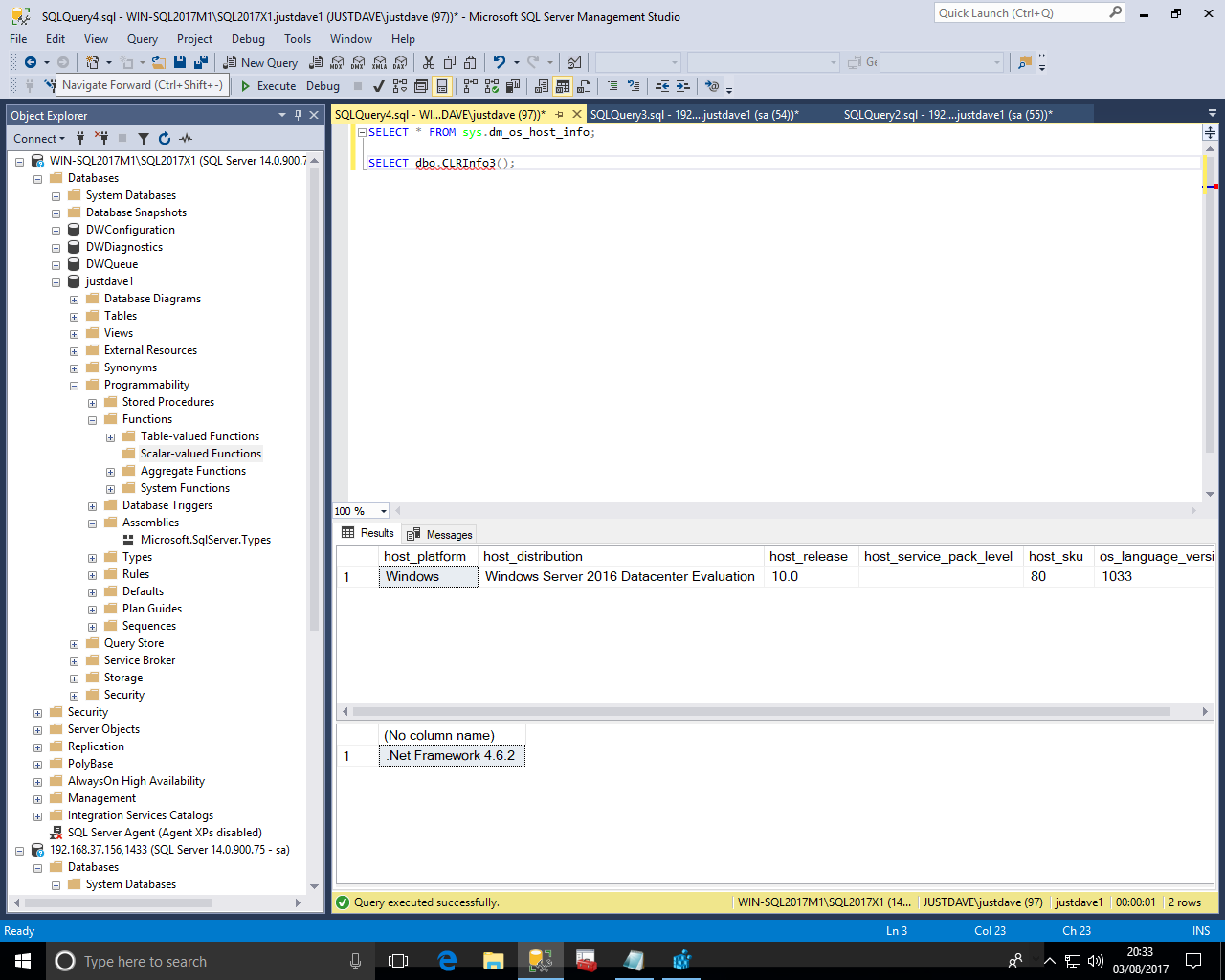
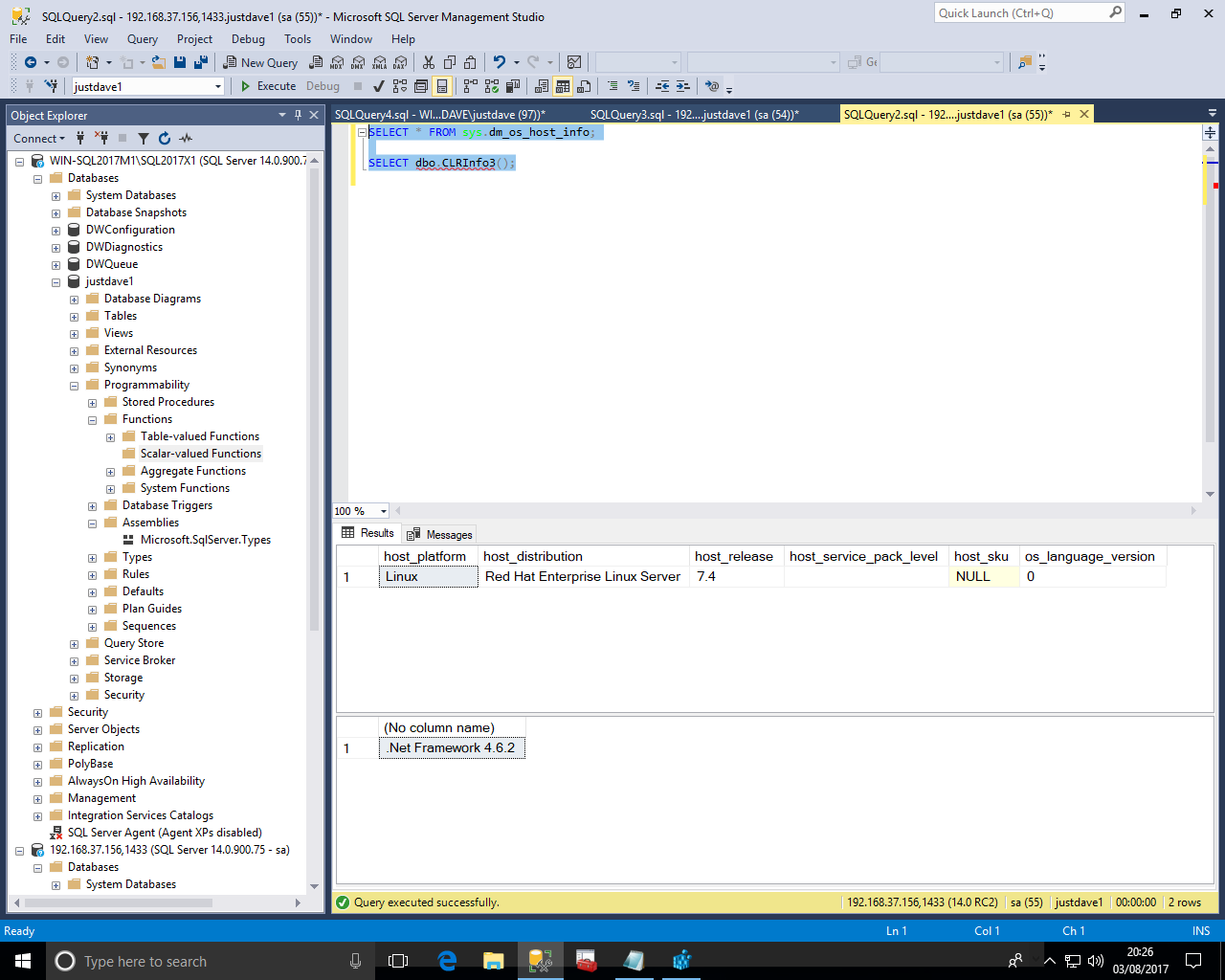
-- Windows version CREATE ASSEMBLY Ver2Test FROM 'C:\x\Ver2Test.dll' WITH PERMISSION_SET = SAFE; -- Linux version CREATE ASSEMBLY Ver2Test FROM 'C:\var\opt\udr\Ver2Test.dll' WITH PERMISSION_SET = SAFE; CREATE FUNCTION [dbo].[CLRInfo3] () RETURNS NVARCHAR(MAX) AS EXTERNAL NAME [Ver2Test].[UserDefinedFunctions].[CLRInfo3]; SELECT * FROM sys.dm_os_host_info; SELECT dbo.CLRInfo3();
We get the following so this is .NET framework 4.6.2!
On Windows
On Redhat 7.4
On Ubuntu 16.04