2. Database Engine
2.1 Database Engine Feature Enhancements
2.1.1 Columnstore Indexes
2.1.1.1 Many enhancements (CTP 2.0)
2.1.1.2 A read-only nonclustered columnstore index is updateable after upgrade (CTP 3.0)
2.1.1.3 Performance improvements for analytics queries on columnstore indexes (CTP 3.0)
2.1.1.4 DMVs and XEvents have supportability improvements (CTP 3.0)
2.1.2 In-Memory OLTP
2.1.2.1 Transact-SQL Improvements
2.1.2.1.1 Query Surface Area in Native Modules (CTP 2.0/CTP 3.0/CTP 3.1/CTP 3.2)
2.1.2.1.2 Altering Natively Compiled Stored Procedures (CTP 2.0)
2.1.2.1.2 Altering Memory-Optimized Tables (CTP 2.0)
2.1.2.1.3 Full support for all Collation and Unicode Support (CTP 2.0)
2.1.2.1.4 Scalar User-Defined Functions (CTP 2.0)
2.1.2.1.5 Constraints (CTP 3.0)
2.1.2.1.6 Triggers (CTP 3.0)
2.1.2.1.7 NULLable index key columns,LOB types,UNIQUE indexes (CTP 3.1)
2.1.2.2 Performance and Scaling improvements
2.1.2.2.1 Increased data size to 2TB (CTP 2.0)
2.1.2.2.2 Scalability improvements in the persistence layer (CTP 2.0)
2.1.2.2.3 Parallel plan support for Accessing Memory-Optimized Tables Using Interpreted Transact-SQL (CTP 2.0)
2.1.2.2.4 Parallel scan support for HASH indexes (CTP 2.0)
2.1.2.3 Enhancements in SQL Server Management Studio
2.1.2.3.1 Determining if a Table or Stored Procedure Should Be Ported to In-Memory OLTP (CTP 2.0)
2.1.2.3.2 PowerShell Cmdlet for Migration Evaluation (CTP 2.0)
2.1.2.3.3 Generate migration checklists by right-clicking on a database (CTP 2.0)
2.1.2.4 Cross-feature support
2.1.2.4.1 Multiple Active Result Sets (MARS) (CTP 2.0)
2.1.2.4.2 Transparent Data Encryption (CTP 2.0)
2.1.2.4.3 Temporal Tables (CTP 3.0)
2.1.2.4.4 Query Store (CTP 3.0)
2.1.2.4.5 Row Level Security (CTP 3.0)
2.1.3 Live Query Statistics (CTP 2.0)
2.1.4 Query Store
2.1.4.1 Base release (CTP 2.0)
2.1.4.2 Remove Columns from sys.query_store_query view (CTP 2.1)
2.1.4.3 ALTER DATABASE now validates minimal value for flush_interval_seconds (CTP 2.1)
2.1.4.4 Align naming in sys.database_query_store_options and ALTER statements (CTP 2.1)
2.1.4.5 Disabled on master and tempdb (CTP 2.1)
2.1.4.6 Force_failure_count parameter is now cleared after plan is enforced (CTP 2.1)
2.1.4.7 Query Store Read only Mode (CTP 2.2)
2.1.4.8 Query Store UI enhancements and bug fixes (CTP 2.2)
2.1.4.9 No force plan recompiles after MAX_PLANS_PER_QUERY is hit (CTP 2.2)
2.1.5 Temporal Tables
2.1.5.1 Base release (CTP 2.0)
2.1.5.2 Support for computed columns (CTP 2.1)
2.1.5.3 Support for marking one or both period columns with HIDDEN flag (CTP 2.1)
2.1.5.4 Full support column with ROWVERSION (TIMESTAMP) (CTP 2.2)
2.1.5.5 COLUMNPROPERTY exposes ‘ishidden’ property (CTP 2.2)
2.1.5.6 Several improvements in SQL Server Management Studio (CTP 2.2)
2.1.5.7 One or both period columns can be marked with the hidden flag (CTP 2.3)
2.1.5.8 In-memory OLTP support (CTP 3.0)
2.1.5.9 Alter table support (CTP 3.0)
2.1.5.10 FOR SYSTEM_TIME ALL (CTP 3.0)
2.1.5.11 Optimized CONTAINED IN implementation with minimized locking on current table (CTP 3.0)
2.1.6 Backup to Microsoft Azure
2.1.7 Managed Backup
2.1.8 Trace Flag 4199
2.1.9 JSON
2.1.9.1 FOR JSON (CTP 2.0)
2.1.9.2 OPENJSON (CTP 3.0)
2.1.9.3 ISJSON (CTP 3.0)
2.1.9.4 JSON_VALUE (CTP 3.0)
2.1.9.5 JSON_QUERY (CTP 3.0)
2.1.9.6 AdventureWorks sample database support (CTP 3.0)
2.1.9.7 FOR JSON/WITHOUT_ARRAY_WRAPPER (CTP 3.2)
2.1.10 Always Encrypted
2.1.10.1 Always Encrypted (CTP 2.0)
2.1.10.2 Management Studio enhancements related to dialog boxes, and the Always Encrypted Wizard (CTP 3.0)
2.1.10.3 Elimination of some restrictions (CTP 3.0)
2.1.10.4 The word DEFINITION was removed from column master keys (CTP 3.0)
2.1.10.5 The COLUMN MASTER KEY argument of CREATE COLUMN ENCRYPTION KEY (Transact-SQL) has been renamed to COLUMN_MASTER_KEY (CTP 3.0)
2.1.10.6 Built-in support for using column master keys stored in hardware security modules (HSMs) that provide Crypto API (CAPI) or Cryptography API - Next Generation (CNG) (CTP 3.0)
2.1.10.7 The CREATE USER syntax is enhanced with the ALLOW_ENCRYPTED_VALUE_MODIFICATIONS option to support the Always Encrypted feature (CTP 3.0)
2.1.11 PolyBase
2.1.12 Stretch Database
2.1.12.1 Base release (CTP 2.0)
2.1.12.2 Lock Escalation (CTP 2.1)
2.1.12.3 Automatic encryption and validation requirement of remote server certification (CTP 2.1)
2.1.12.4 Security Policies and Row Level Security (CTP 2.2)
2.1.12.5 Stretch Database Advisor (CTP 2.2)
2.1.12.6 SSMS enhancements (CTP 3.0)
2.1.12.7 Enable Stretch Database Wizard enhancements (CTP 3.0)
2.1.12.8 Database scoped credentials (CTP 3.0)
2.1.12.9 Join Performance improvement (CTP 3.0)
2.1.12.10 AdventureWorks sample database (CTP 3.0)
2.1.12.11 Specify a predicate which must call an inline table-valued function (CTP 3.1)
2.1.12.12 Compatibile with Temporal tables (CTP 3.1)
2.1.12.12 Unmigrate tables (CTP 3.1)
2.1.12.12 Compatibile with Always On (CTP 3.1)
2.1.13 TempDB Enhancements
2.2 Transact-SQL Enhancements
2.2.1 TRUNCATE TABLE for specific partitions (CTP 2.0)
2.2.2 ALTER TABLE many actions whilst table is still available (CTP 2.0)
2.2.3 New query hint NO_PERFORMANCE_SPOOL (CTP 2.0)
2.2.4 The FORMATMESSAGE (Transact-SQL) statement accepts a msg_string argument (CTP 2.0)
2.2.5 Additional DROP IF syntax (CTP 3.0)
2.2.6 A MAXDOP option has been added to DBCC CHECKTABLE/DBCC CHECKDB/DBCC CHECKFILEGROUP (CTP 3.0)
2.2.7 SESSION_CONTEXT can now be set (CTP 3.0)
2.2.8 Advanced Analytics Extensions allow users to execute scripts written in a supported language such as R (CTP 3.0)
2.2.9 The CREATE USER syntax is enhanced with the ALLOW_ENCRYPTED_VALUE_MODIFICATIONS option (CTP 3.0)
2.2.10 GZIP COMPRESS/UNCOMPRESS functions (CTP 3.1)
2.2.11 DATEDIFF_BIG/AT TIME ZONE/sys.time_zone_info (CTP 3.1)
2.3 System View Enhancements
2.3.1 Two new views support row level security (CTP 2.0)
2.3.2 Seven new views support the Query Store feature (CTP 2.0)
2.3.3 24 new columns are added to sys.dm_exec_query_stats to provide information about memory grants (CTP 2.0)
2.3.4 Two new query hints (MIN_GRANT_PERCENT and MAX_GRANT_PERCENT) are added to specify memory grants (CTP 2.0)
2.3.5 sys.dm_exec_session_wait_stats (Transact-SQL) provides a per session report similar to the server wide sys.dm_os_wait_stats (CTP 2.2)
2.3.6 sys.dm_exec_function_stats (Transact-SQL) provides execution statistics regarding scalar valued functions (CTP 2.3)
2.3.7 sys.dm_fts_index_keywords_position_by_document (CTP 2.0)
2.4 Security Enhancements
2.4.1 Row Level Security
2.4.1.1 Row-Level Security (CTP 2.0)
2.4.1.2 Row-level security is supported for memory-optimized tables (CTP 2.3)
2.4.1.3 Row-level security adds support for block predicates. SESSION_CONTEXT can now be set for use in a security policy. (CTP 3.0)
2.4.2 Dynamic Data Masking
2.4.2.1 Dynamic Data Masking (CTP 2.0)
2.4.2.2 Many enhancements (CTP 3.0)
2.4.3 New Permissions
2.4.3.1 ALTER ANY SECURITY POLICY for row level security (CTP 2.0)
2.4.3.2 ALTER ANY MASK and UNMASK for dynamic data masking (CTP 2.0)
2.4.3.3 ALTER ANY COLUMN ENCRYPTION KEY, VIEW ANY COLUMN ENCRYPTION KEY, ALTER ANY COLUMN MASTER KEY DEFINITION for Always Encrypted (CTP 2.0)
2.4.3.4 ALTER ANY EXTERNAL DATA SOURCE/ALTER ANY EXTERNAL FILE FORMAT for Analytics Platform System (SQL Data Warehouse) (CTP 3.2)
2.4.3.5 EXECUTE ANY EXTERNAL SCRIPT for supporting R scripts (CTP 3.0)
2.4.4 Transparent Data Encryption
2.4.4.1 Support for Intel AES-NI hardware acceleration of encryption (CTP 2.0)
2.4.5 AES Encryption for Endpoints
2.5 High Availability Enhancements
2.5.1 SQL Server 2016 CTP Standard Edition now supports AlwaysOn Basic Availability Groups (CTP 3.2)
2.5.2 Load-balancing of read-intent connection requests is now supported across a set of read-only replicas (CTP 2.0)
2.5.3 The number of replicas that support automatic failover has been increased from two to three (CTP 2.0)
2.5.4 Group Managed Service Accounts are now supported for AlwaysOn Failover Clusters (CTP 2.0)
2.5.5 AlwaysOn Availability Groups supports distributed transactions and the DTC on Windows Server 2016 (CTP 2.0)
2.5.6 AlwaysOn Availability Groups can be configure to failover when a database goes offline (CTP 2.0)
2.5.7 AlwaysOn now supports encrypted databases (CTP 2.2)
2.6 Tools Enhancements
2.6.1 SQL Server Management Studio
2.6.1.1 SSMS supports the Active Directory Authentication Library (ADAL) for connecting to Microsoft Azure (CTP 2.0)
2.6.1.2 SSMS requires .NET Framework 4.6 (CTP 2.0)
2.6.1.3 SSMS new query result grid option supports keeping Carriage Return/Line Feed characters (CTP 3.0)
2.6.2 Upgrade Advisor
2.6.2.1 QL Server 2016 Upgrade Advisor Preview 1 standalone tool (CTP 2.2)
2.7 Replication Enhancements
2.7.1 Replication for memory optimized tables (CTP 3.0)
2.7.2 Replication to Azure SQL Database (CTP 3.0)
- Batch execution for single threaded queries
IF OBJECT_ID('dbo.Numbers1', 'U') IS NOT NULL
DROP TABLE dbo.Numbers1;
CREATE TABLE dbo.Numbers1 (
NumberID int NOT NULL,
INDEX ix_NumberID1 CLUSTERED COLUMNSTORE
);
WITH
Pass0 as (select 1 as C union all select 1), --2 rows
Pass1 as (select 1 as C from Pass0 as A, Pass0 as B),--4 rows
Pass2 as (select 1 as C from Pass1 as A, Pass1 as B),--16 rows
Pass3 as (select 1 as C from Pass2 as A, Pass2 as B),--256 rows
Pass4 as (select 1 as C from Pass3 as A, Pass3 as B),--65536 rows
Pass5 as (select 1 as C from Pass4 as A, Pass4 as B),--4,294,967,296 rows
Tally as (select row_number() over(order by C) as Number from Pass5)
INSERT dbo.Numbers1 (NumberID)
select TOP(1000) Number
from Tally;
ALTER INDEX ix_NumberID1 ON dbo.Numbers1 REORGANIZE;
-- Check row groups
SELECT b.name,a.partition_number,a.row_group_id,a.state_description,a.total_rows,a.size_in_bytes
FROM sys.column_store_row_groups a
INNER JOIN sys.objects b
ON a.object_id = b.object_id
WHERE b.object_id IN (OBJECT_ID('dbo.Numbers1', 'U'))
ORDER BY b.name,a.partition_number,a.row_group_id;
-- SSMs
-- Include Actual Execution Plan
-- Batch mode for serial query - NEW!
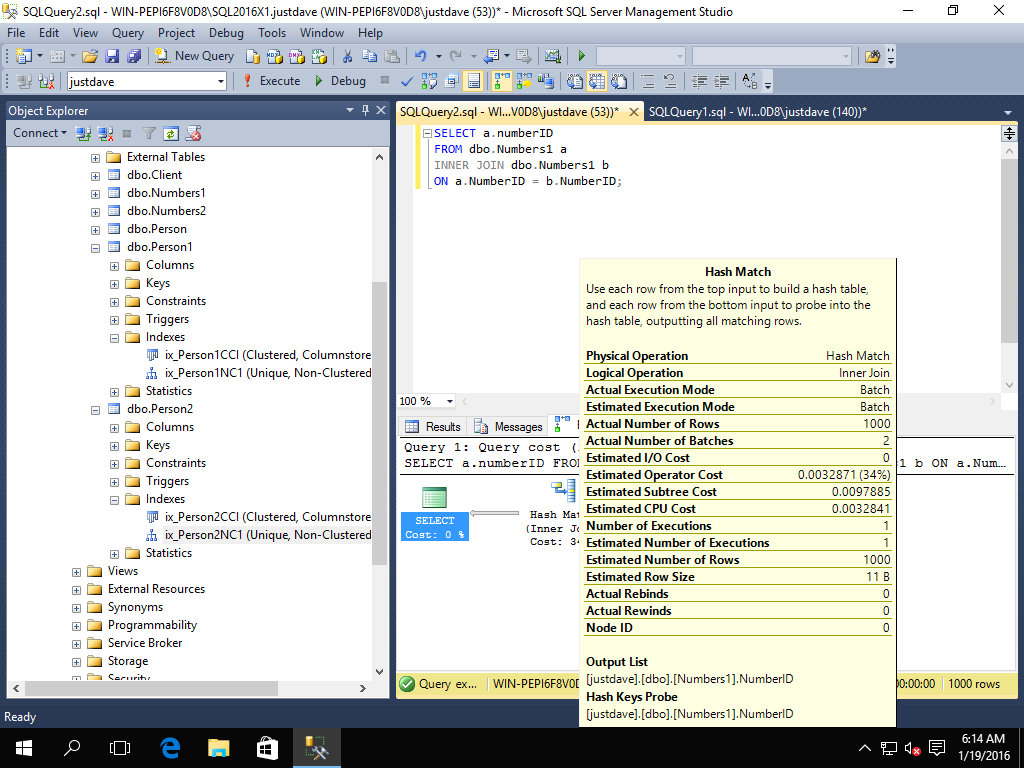
SELECT a.numberID
FROM dbo.Numbers1 a
INNER JOIN dbo.Numbers1 b
ON a.NumberID = b.NumberID;
The server only has 1 CPU so we get a serial plan yet the hash match is run in batch mode
 Snapshot isolation and read-committed snapshot isolation are supported
Snapshot isolation and read-committed snapshot isolation are supported
IF OBJECT_ID('dbo.Person', 'U') IS NOT NULL
DROP TABLE dbo.Person;
CREATE TABLE dbo.Person
(
PersonID INT NOT NULL,
PersonName NVARCHAR(100),
);
ALTER DATABASE justdave SET ALLOW_SNAPSHOT_ISOLATION ON;
CREATE CLUSTERED COLUMNSTORE INDEX ix_PersonName ON dbo.Person;
SET TRANSACTION ISOLATION LEVEL SNAPSHOT;
DBCC USEROPTIONS;
BEGIN TRAN;
-- Transaction isolation level snapshot - NEW!
-- 2014 gives
-- Msg 35371, Level 16, State 1, Line 3
-- SNAPSHOT isolation level is not supported on a table which has a clustered columnstore index.
INSERT INTO Person(PersonID,PersonName) VALUES (1,'Person 1');
COMMIT TRAN;
SET TRANSACTION ISOLATION LEVEL READ COMMITTED;
Specify columnstore index when creating a table
IF OBJECT_ID('dbo.Numbers1', 'U') IS NOT NULL
DROP TABLE dbo.Numbers1;
CREATE TABLE dbo.Numbers1 (
NumberID int NOT NULL,
INDEX ix_NumberID1 CLUSTERED COLUMNSTORE
);
AlwaysOn readable secondary supports updateable columnstore indexes
AlwaysOn readable secondary supports updateable columnstore indexes!
Updateable nonclustered columnstore index on heap or btree
There can only be 1 Updatable Non-Clustered Columnstore Index!
IF OBJECT_ID('dbo.Person', 'U') IS NOT NULL
DROP TABLE dbo.Person;
CREATE TABLE dbo.Person
(
PersonID INT NOT NULL,
PersonName NVARCHAR(100),
);
CREATE CLUSTERED INDEX ix_PersonID ON Person(PersonID);
CREATE NONCLUSTERED COLUMNSTORE INDEX ix_PersonName ON Person(PersonName);
-- Table is writable - NEW!
INSERT INTO dbo.Person VALUES (1,'Person 1');
Btree index on a clustered columnstore index
IF OBJECT_ID('dbo.Person1', 'U') IS NOT NULL
DROP TABLE dbo.Person1;
CREATE TABLE dbo.Person1
(
PersonID INT NOT NULL,
PersonName NVARCHAR(100),
);
--Store the table as a columnstore.
CREATE CLUSTERED COLUMNSTORE INDEX ix_Person1CCI ON Person1;
-- Unique B-tree NC index - NEW
CREATE UNIQUE INDEX ix_Person1NC1 ON Person1(PersonID);
IF OBJECT_ID('dbo.Person2', 'U') IS NOT NULL
DROP TABLE dbo.Person2;
CREATE TABLE dbo.Person2
(
PersonID INT NOT NULL,
PersonName NVARCHAR(100),
);
--Store the table as a columnstore.
CREATE CLUSTERED COLUMNSTORE INDEX ix_Person2CCI ON Person2;
-- Unique B-tree NC index - NEW
CREATE UNIQUE INDEX ix_Person2NC1 ON Person2(PersonID);
TRUNCATE TABLE dbo.Person1;
INSERT INTO Person1 (PersonID,PersonName) VALUES(1,'Person1');
TRUNCATE TABLE dbo.Person2;
INSERT INTO Person2 (PersonID,PersonName) VALUES(1,'First Person');
INSERT INTO Person2 (PersonID,PersonName) VALUES(2,'Second Person');
ALTER INDEX ix_Person1CCI ON dbo.Person1 REORGANIZE;
ALTER INDEX ix_Person2CCI ON dbo.Person2 REORGANIZE;
SELECT * FROM Person1;
SELECT * FROM Person2;
# Not supported
MERGE Person1 AS T
USING Person2 AS S
ON (T.PersonID = S.PersonID)
WHEN NOT MATCHED BY TARGET
THEN INSERT (PersonID,PersonName) VALUES (S.PersonID,S.PersonName)
WHEN MATCHED
THEN UPDATE SET T.PersonName=S.PersonName;
Columnstore index on a memory-optimized table
IF OBJECT_ID('dbo.Person', 'U') IS NOT NULL
DROP TABLE dbo.Person;
-- NOTE: This must be durability SCHEMA_AND_DATA though
CREATE TABLE dbo.Person
(
PersonID INT PRIMARY KEY NONCLUSTERED,
PersonName NVARCHAR(100),
INDEX ix_PersonID CLUSTERED COLUMNSTORE
) WITH (MEMORY_OPTIMIZED=ON, DURABILITY=SCHEMA_ONLY);
-- Primary key still has to be nonclustered
-- Therefore memory-optimized tables can be Columnstore+Clustered not B-tree+Clustered
-- Non-clustered B-tree index supports foreign keys
-- The columnstore index has to be created when the table is created
-- The columnstore index cannot be filtered
-- The olumnstore index is accessed in interOP mode, not in-memory native mode
IF OBJECT_ID('dbo.Person', 'U') IS NOT NULL
DROP TABLE dbo.Person;
CREATE TABLE dbo.Person
(
PersonID INT PRIMARY KEY NONCLUSTERED,
PersonName NVARCHAR(100),
INDEX ix_PersonID CLUSTERED COLUMNSTORE
) WITH (MEMORY_OPTIMIZED=ON, DURABILITY=SCHEMA_AND_DATA);
-- NOTE: ALTER TABLE is not supported on memory optimized tables that have a column store index.
-- Msg 10794, Level 16, State 15, Line 2
-- The operation 'ALTER TABLE' is not supported with memory optimized tables that have a column store index.
ALTER TABLE Person
ADD PersonComments NVARCHAR(150);
Nonclustered columnstore index definition supports using a filtered condition
-- Hot and Cold Data
IF OBJECT_ID('dbo.Orders', 'U') IS NOT NULL
DROP TABLE dbo.Orders;
CREATE TABLE Orders
(
OrderID int NOT NULL PRIMARY KEY,
OrderDate INT,
UnitsSold INT
);
CREATE NONCLUSTERED COLUMNSTORE INDEX Orders_NCCI1 ON Orders(OrderDate,UnitsSold)
WHERE OrderDate < 2016;
CREATE NONCLUSTERED INDEX Orders_NCI1 ON Orders(OrderDate)
WHERE OrderDate >= 2016;
-- Memory optimized + columnstore (or b-tree) + filtered index
IF OBJECT_ID('dbo.Orders', 'U') IS NOT NULL
DROP TABLE dbo.Orders;
CREATE TABLE Orders
(
OrderID int NOT NULL PRIMARY KEY NONCLUSTERED,
OrderDate INT,
UnitsSold INT
) WITH (MEMORY_OPTIMIZED=ON, DURABILITY=SCHEMA_AND_DATA);
-- Msg 10794, Level 16, State 12, Line 1
-- The operation 'CREATE INDEX' is not supported with memory optimized tables.
CREATE NONCLUSTERED COLUMNSTORE INDEX Orders_NCCI1 ON Orders(OrderDate,UnitsSold)
WHERE OrderDate < 2016;
-- Msg 10794, Level 16, State 12, Line 1
-- The operation 'CREATE INDEX' is not supported with memory optimized tables.
CREATE NONCLUSTERED INDEX Orders_NCI1 ON Orders(OrderDate)
WHERE OrderDate >= 2016;
Improved Seek Performance (CTP 2.1) WIP
Improved scan performance with partitioned tables (CTP 2.1) WIP
After the upgrade process read-only nonclustered columnstore index are writeable
Additional logical operators can run in batch mode
IF OBJECT_ID('dbo.Numbers1', 'U') IS NOT NULL
DROP TABLE dbo.Numbers1;
CREATE TABLE dbo.Numbers1 (
NumberID int NOT NULL,
Name varchar(10)
);
CREATE CLUSTERED COLUMNSTORE INDEX ix_NumberID1 ON dbo.Numbers1;
WITH
Pass0 as (select 1 as C union all select 1), --2 rows
Pass1 as (select 1 as C from Pass0 as A, Pass0 as B),--4 rows
Pass2 as (select 1 as C from Pass1 as A, Pass1 as B),--16 rows
Pass3 as (select 1 as C from Pass2 as A, Pass2 as B),--256 rows
Pass4 as (select 1 as C from Pass3 as A, Pass3 as B),--65536 rows
Pass5 as (select 1 as C from Pass4 as A, Pass4 as B),--4,294,967,296 rows
Tally as (select row_number() over(order by C) as Number from Pass5)
INSERT dbo.Numbers1 (NumberID)
select TOP(10000) Number
from Tally;
ALTER INDEX ix_NumberID1 ON dbo.Numbers1 REORGANIZE;
-- Check row groups
SELECT b.name,a.partition_number,a.row_group_id,a.state_description,a.total_rows,a.size_in_bytes
FROM sys.column_store_row_groups a
INNER JOIN sys.objects b
ON a.object_id = b.object_id
WHERE b.object_id IN (OBJECT_ID('dbo.Numbers1', 'U'))
ORDER BY b.name,a.partition_number,a.row_group_id;
- Clustered Index Scan (Serial Plan),added CTP 2.0
SELECT a.numberID
FROM dbo.Numbers1 a
INNER JOIN dbo.Numbers1 b
ON a.NumberID = b.NumberID;
Compute Scalar (Serial Plan),added CTP 2.0
SELECT a.numberID*2
FROM dbo.Numbers1 a
INNER JOIN dbo.Numbers1 b
ON a.NumberID = b.NumberID;
Concatenation (Serial Plan),added CTP 2.0
SELECT a.numberID
FROM dbo.Numbers1 a
UNION ALL
SELECT a.numberID
FROM dbo.Numbers1 a
UNION ALL
SELECT a.numberID
FROM dbo.Numbers1 a;
Filter (Serial Plan),added CTP 2.0
SELECT a.numberID
FROM dbo.Numbers1 a
INNER JOIN dbo.Numbers1 b
ON a.NumberID = b.NumberID
WHERE a.Name is NOT NULL;
Hash Match (Serial Plan),added CTP 2.0
SELECT a.numberID
FROM dbo.Numbers1 a
INNER JOIN dbo.Numbers1 b
ON a.NumberID = b.NumberID;
Index Scan Nonclustered (Serial Plan),added CTP 2.0
-- Change create index statement to
-- change to insert data, create index and do not reorganize as only this order is supported under 2014
CREATE NONCLUSTERED COLUMNSTORE INDEX ix_NumberID1 ON dbo.Numbers1(NumberID);
SELECT a.numberID
FROM dbo.Numbers1 a
WITH (INDEX(ix_NumberID1))
INNER JOIN dbo.Numbers1 b
WITH (INDEX(ix_NumberID1))
ON a.NumberID = b.NumberID
Additional operators can run in batch mode - WIP
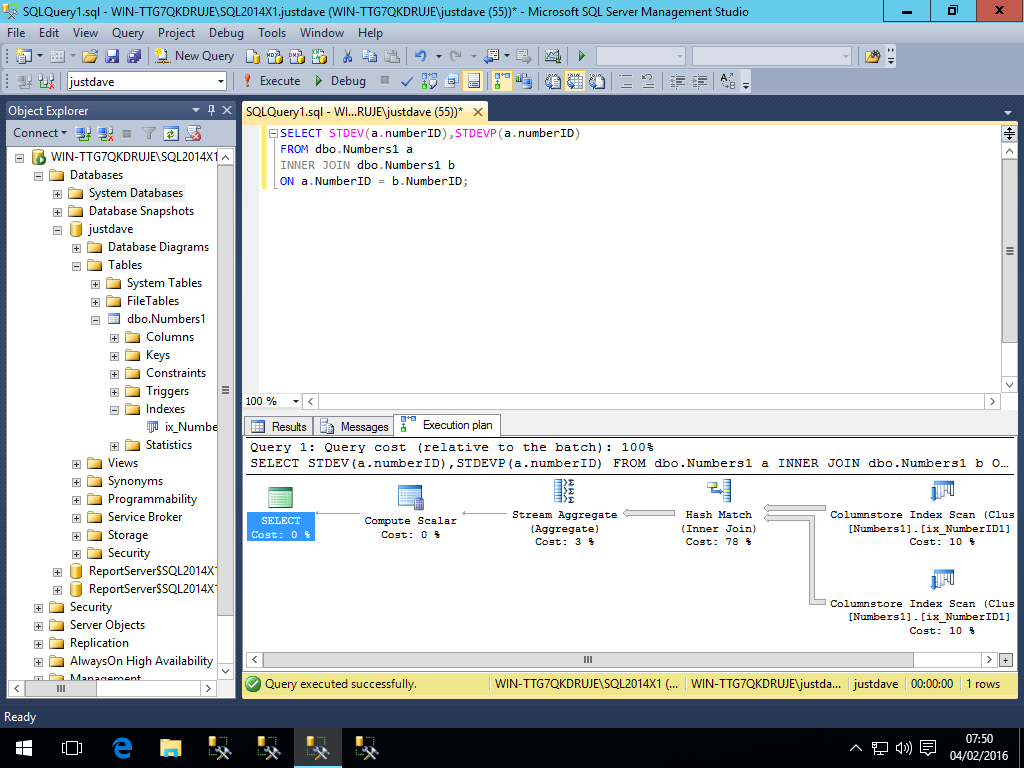
- STDEV/STDEVP,added CTP 2.0
SELECT STDEV(a.numberID),STDEVP(a.numberID)
FROM dbo.Numbers1 a
INNER JOIN dbo.Numbers1 b
ON a.NumberID = b.NumberID;
We have a compute scalar operator running in batch mode
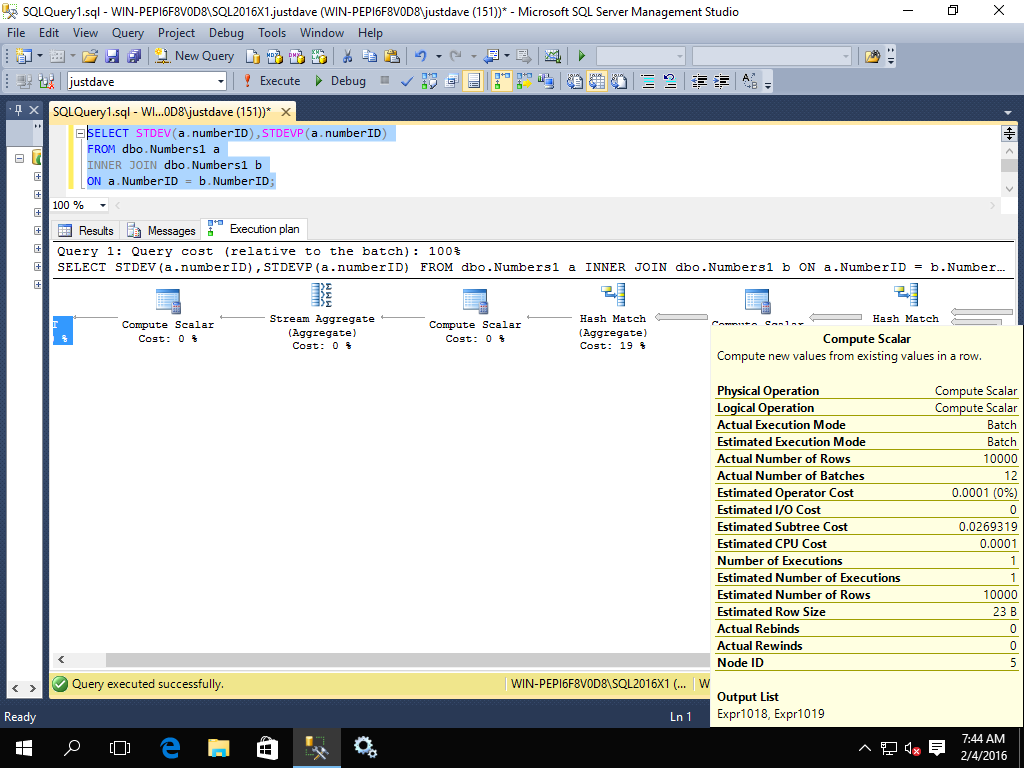
A hash match aggregate running in batch mode
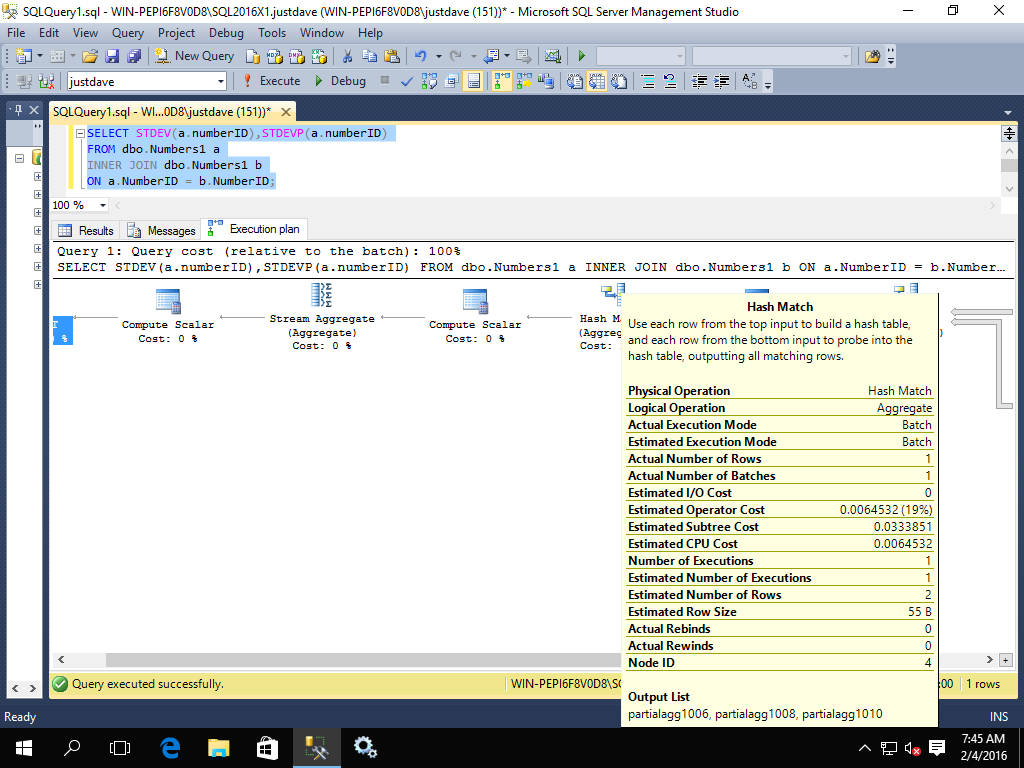
Another compute scalar running in batch mode
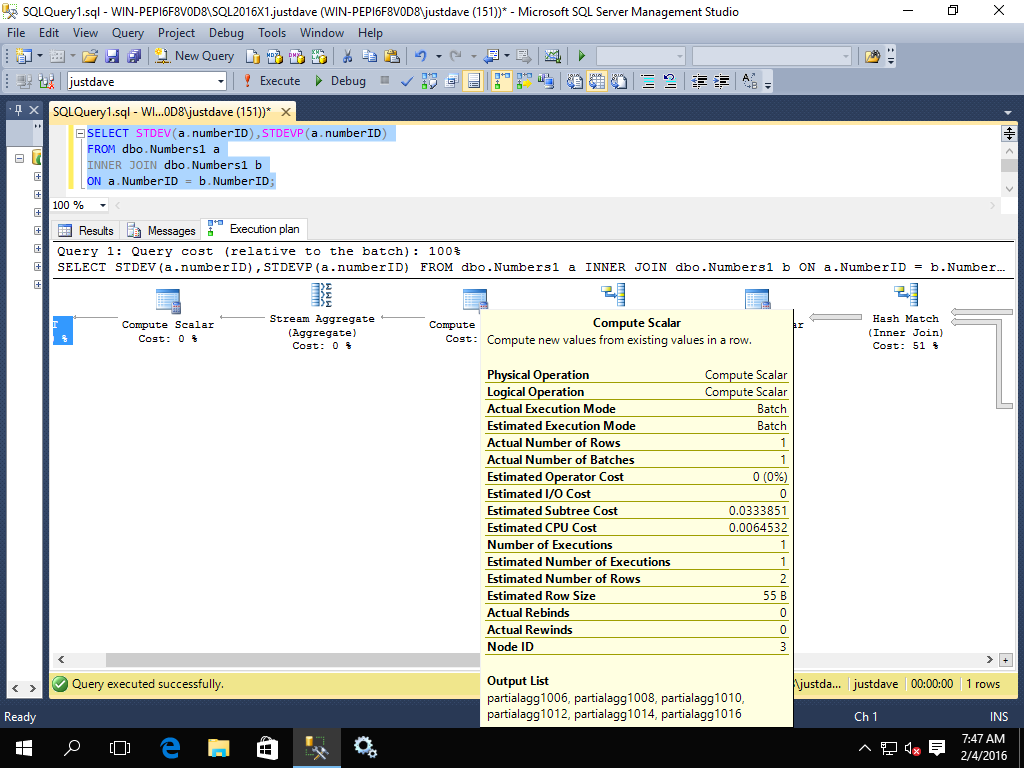
Before we finally go to row mode for the stream aggregate and final computer scalar
With SQL Server 2014 we went straight from the hash match join to the row mode stream aggregate
- SUM/AVG/COUNT/MIN/MAX,added CTP 2.0
SELECT SUM(a.numberID),AVG(a.numberID),COUNT(a.numberID),MIN(a.numberID),MAX(a.numberID)
FROM dbo.Numbers1 a
INNER JOIN dbo.Numbers1 b
ON a.NumberID = b.NumberID;
We get a hash match aggregate and compute scalar in batch mode before we go to a row mode stream aggregate
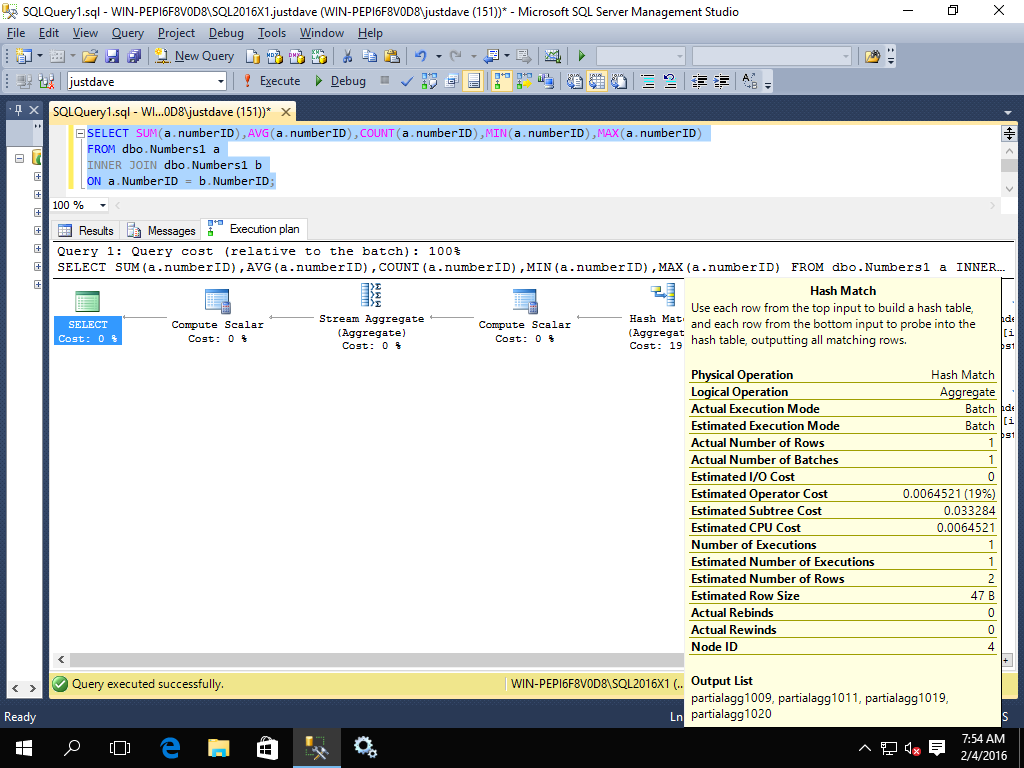
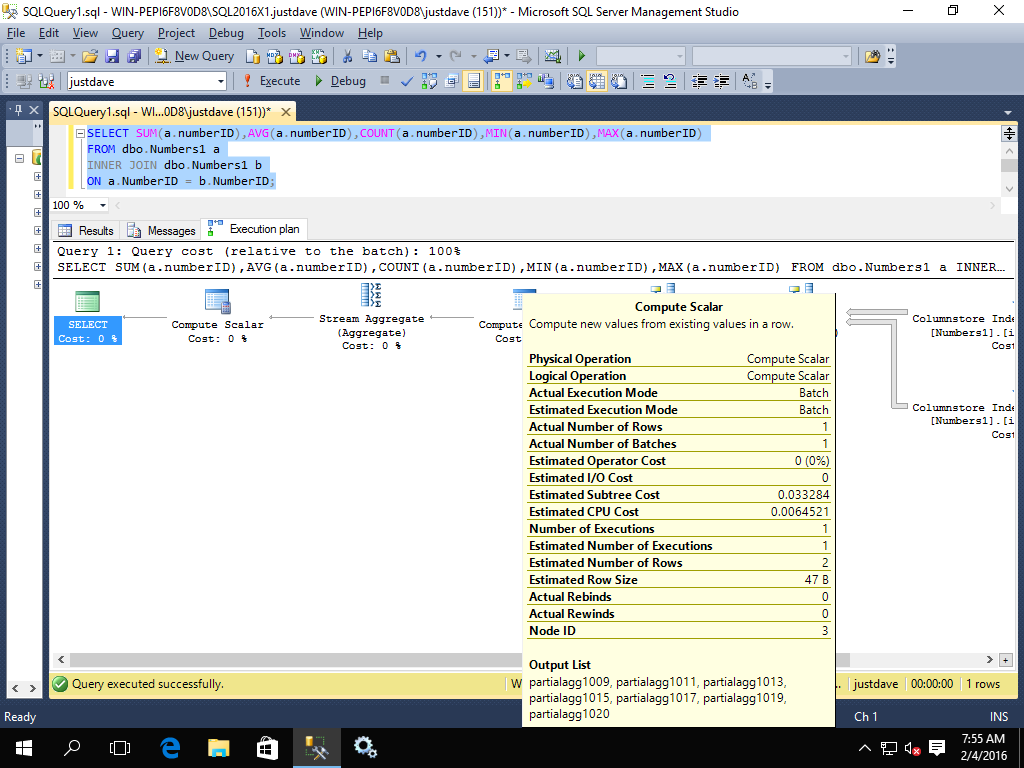
Whereas 2014 does not have these operators
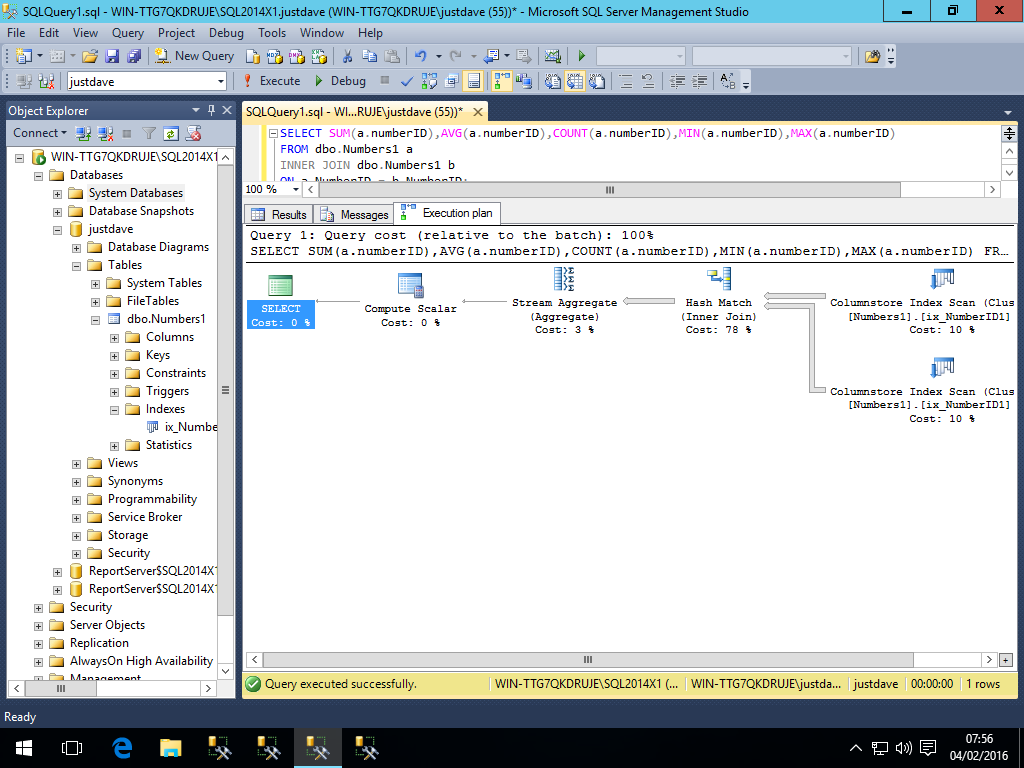
- COUNT_BIG/VAR/VARP,added CTP 2.0
SELECT COUNT_BIG(a.numberID),VAR(a.numberID),VARP(a.numberID)
FROM dbo.Numbers1 a
INNER JOIN dbo.Numbers1 b
ON a.NumberID = b.NumberID;
Similarly we get a 2 compute scalars and hash match aggregate all running in match mode
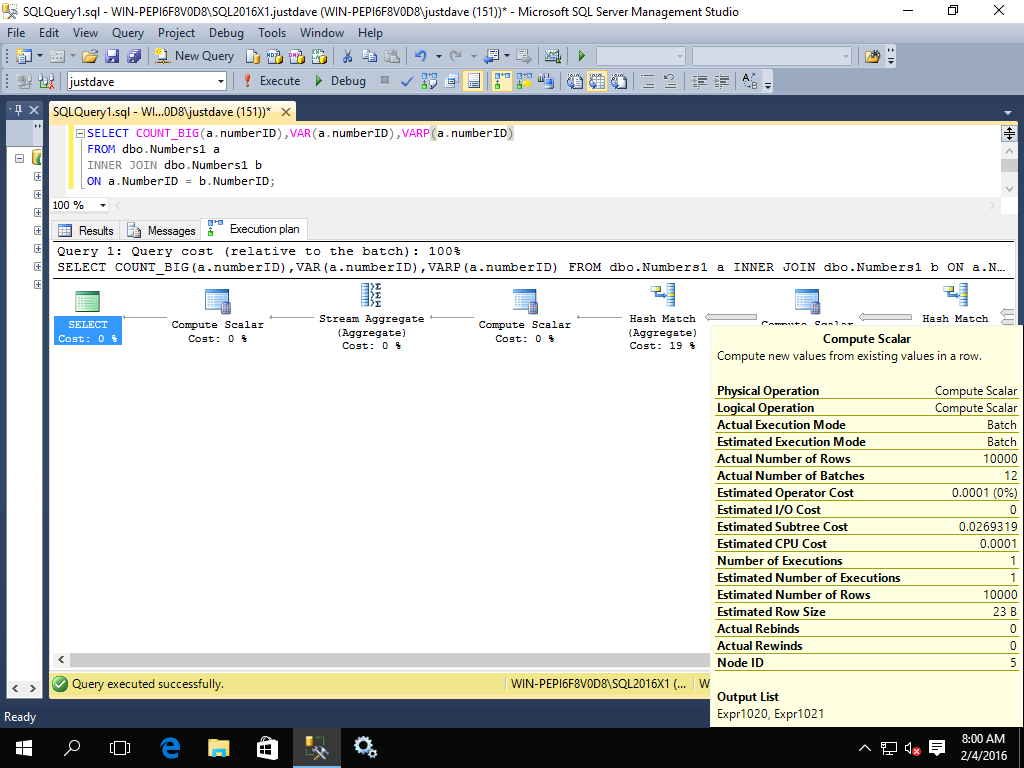
Again 2014 does not have these operators
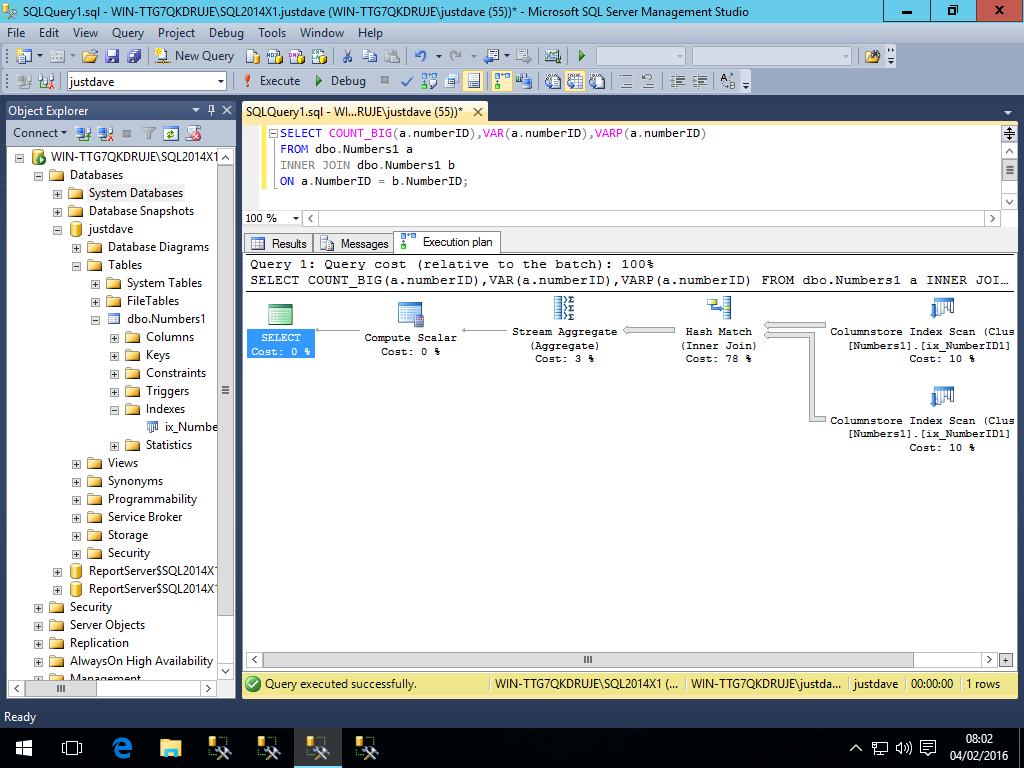
- CHECKSUM_AGG (CTP 3.2 still runs in row mode!) WIP
SELECT CHECKSUM_AGG(CAST(a.numberID as INT))
FROM dbo.Numbers1 a
INNER JOIN dbo.Numbers1 b
ON a.NumberID = b.NumberID;
- CLR - WIP
- CUME_DIST,added CTP 2.0
IF OBJECT_ID('dbo.Numbers1', 'U') IS NOT NULL
DROP TABLE dbo.Numbers1;
CREATE TABLE dbo.Numbers1 (
NumberID int NOT NULL,
DeptID int NOT NULL,
DivisionID int NOT NULL
);
CREATE CLUSTERED COLUMNSTORE INDEX ix_NumberID1 ON dbo.Numbers1;
WITH
Pass0 as (select 1 as C union all select 1), --2 rows
Pass1 as (select 1 as C from Pass0 as A, Pass0 as B),--4 rows
Pass2 as (select 1 as C from Pass1 as A, Pass1 as B),--16 rows
Pass3 as (select 1 as C from Pass2 as A, Pass2 as B),--256 rows
Pass4 as (select 1 as C from Pass3 as A, Pass3 as B),--65536 rows
Pass5 as (select 1 as C from Pass4 as A, Pass4 as B),--4,294,967,296 rows
Tally as (select row_number() over(order by C) as Number from Pass5)
INSERT dbo.Numbers1 (NumberID,DeptID,DivisionID)
select TOP(10000) Number,Number/10,Number/100
from Tally;
ALTER INDEX ix_NumberID1 ON dbo.Numbers1 REORGANIZE;
SELECT a.NumberID,a.DeptID,a.DivisionID,
CUME_DIST() OVER (PARTITION BY a.DivisionID ORDER BY a.DeptID) AS CumeDist
FROM dbo.Numbers1 a
INNER JOIN dbo.Numbers1 b
ON a.NumberID = b.NumberID;
We get a sort,2 window aggregates and a compute scalar all running in batch mode
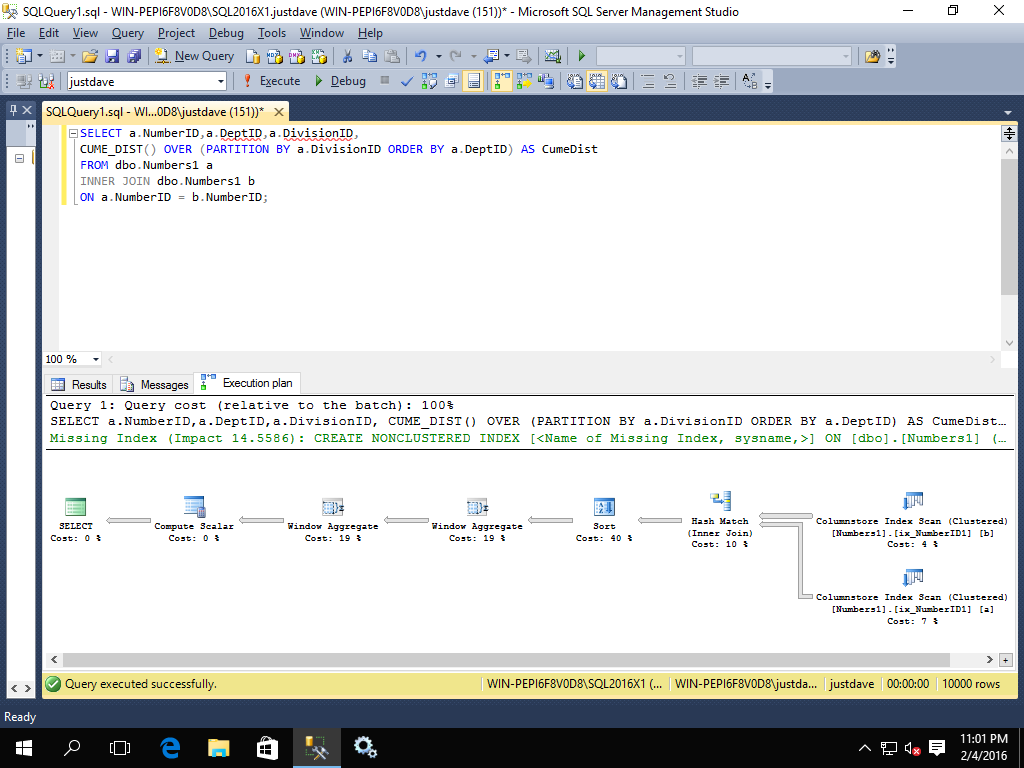
Whereas with 2014 we get table spools, segment operators all running in row mode
Only the upper right index scans/hash match and the leftmost computer scalar run in batch mode
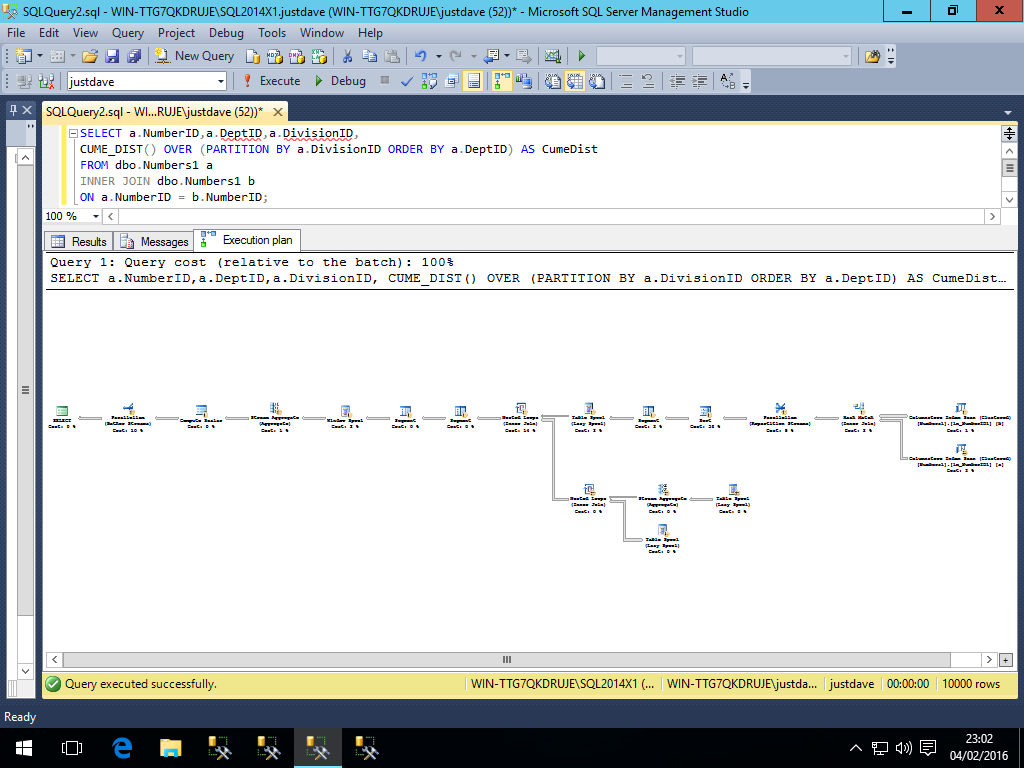 /li>
/li>
- FIRST_VALUE - WIP
SELECT NumberID,DeptID,
FIRST_VALUE(NumberID) OVER (ORDER BY DeptID) AS FirstValue
FROM dbo.Numbers1;
- GROUPING,added CTP 2.0
SELECT DivisionID,DeptID,SUM(NumberID)
FROM dbo.Numbers1
GROUP BY GROUPING SETS ((DivisionID), (DeptID))
The query plan has all operators in batch mode
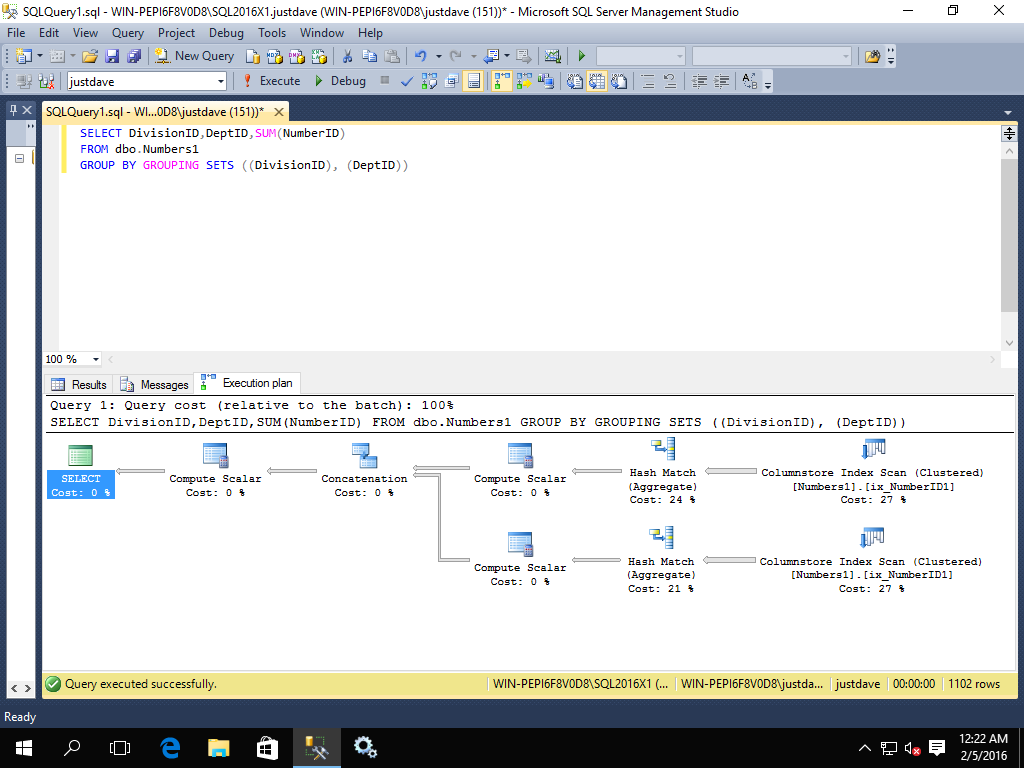
Whereas in 2014 all operators are in row mode
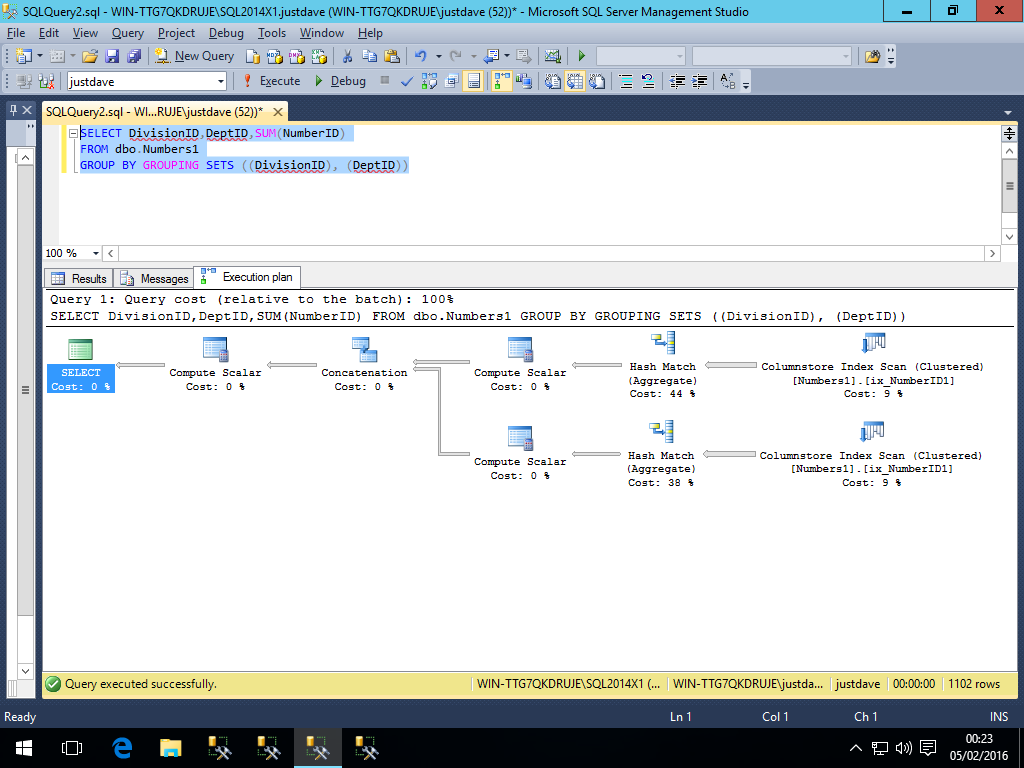
- GROUPING_ID,added CTP 2.0
SELECT DivisionID,DeptID,SUM(NumberID),GROUPING_ID(DivisionID)
FROM dbo.Numbers1
GROUP BY GROUPING SETS ((DivisionID), (DeptID))
The query plan has all operators in batch mode
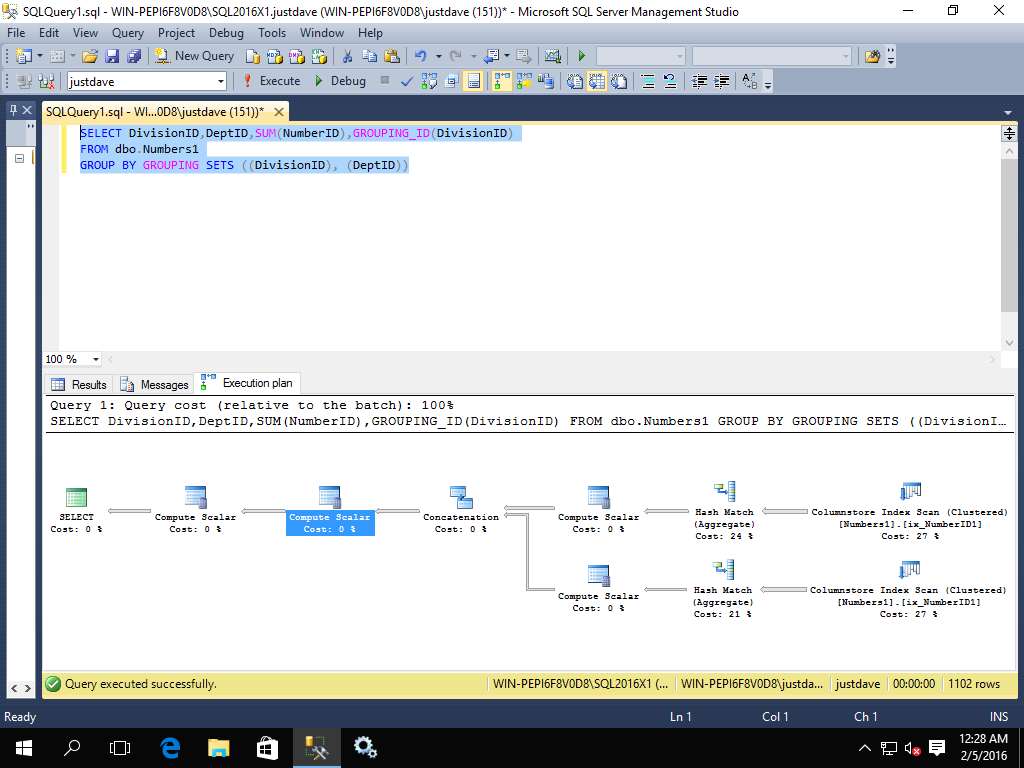
Whereas in 2014 all operators are in row mode
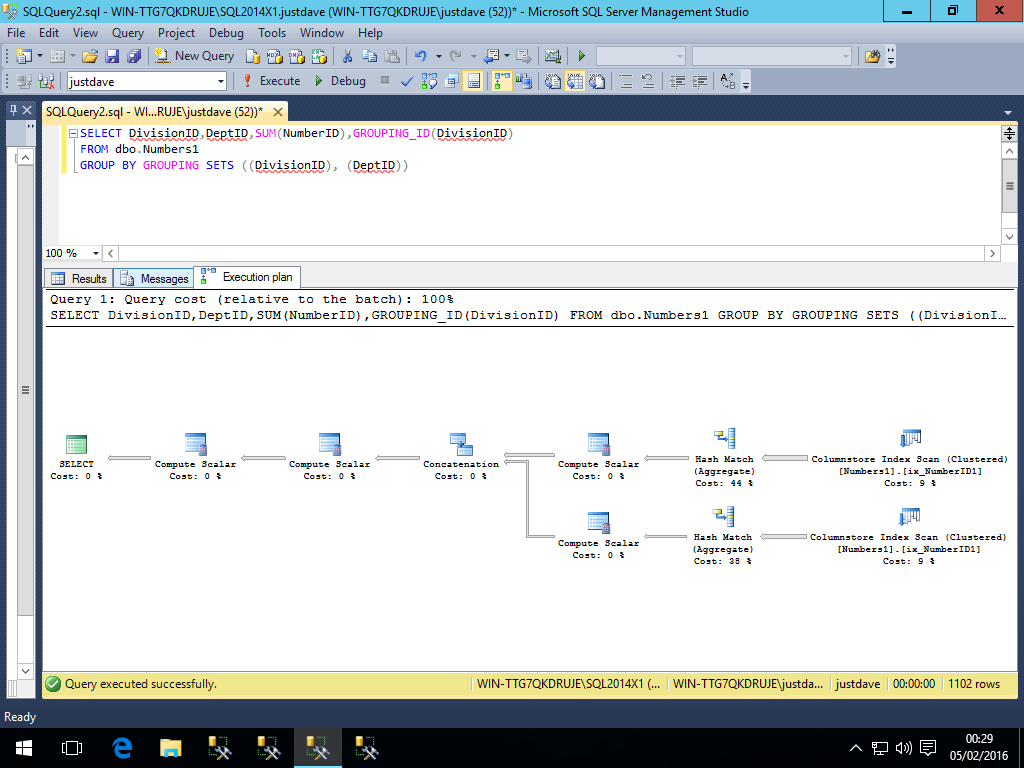
- LAST_VALUE- WIP
- LAG - WIP
SELECT NumberID,DeptID,
LAG(NumberID) OVER (ORDER BY DeptID) AS FirstValue
FROM dbo.Numbers1;
SELECT a.NumberID,a.DeptID,a.DivisionID,
LAG(NumberID) OVER (PARTITION BY a.DivisionID ORDER BY a.DeptID) AS CumeDist
FROM dbo.Numbers1 a
INNER JOIN dbo.Numbers1 b
ON a.NumberID = b.NumberID;
- LEAD- WIP
- PERCENTILE_CONT/PERCENTILE_DISC/PERCENT_RANK,added CTP 2.0
SELECT a.NumberID,a.DeptID,a.DivisionID,
PERCENTILE_CONT(0.5) WITHIN GROUP (ORDER BY a.DeptID) OVER (PARTITION BY a.DivisionID) AS PercCont,
PERCENTILE_DISC(0.5) WITHIN GROUP (ORDER BY a.DeptID) OVER (PARTITION BY a.DivisionID) AS PercDisc,
PERCENT_RANK() OVER (PARTITION BY a.DivisionID ORDER BY a.DeptID ) AS PercRank
FROM dbo.Numbers1 a
INNER JOIN dbo.Numbers1 b
ON a.NumberID = b.NumberID;
The query plan has all operators in batch mode
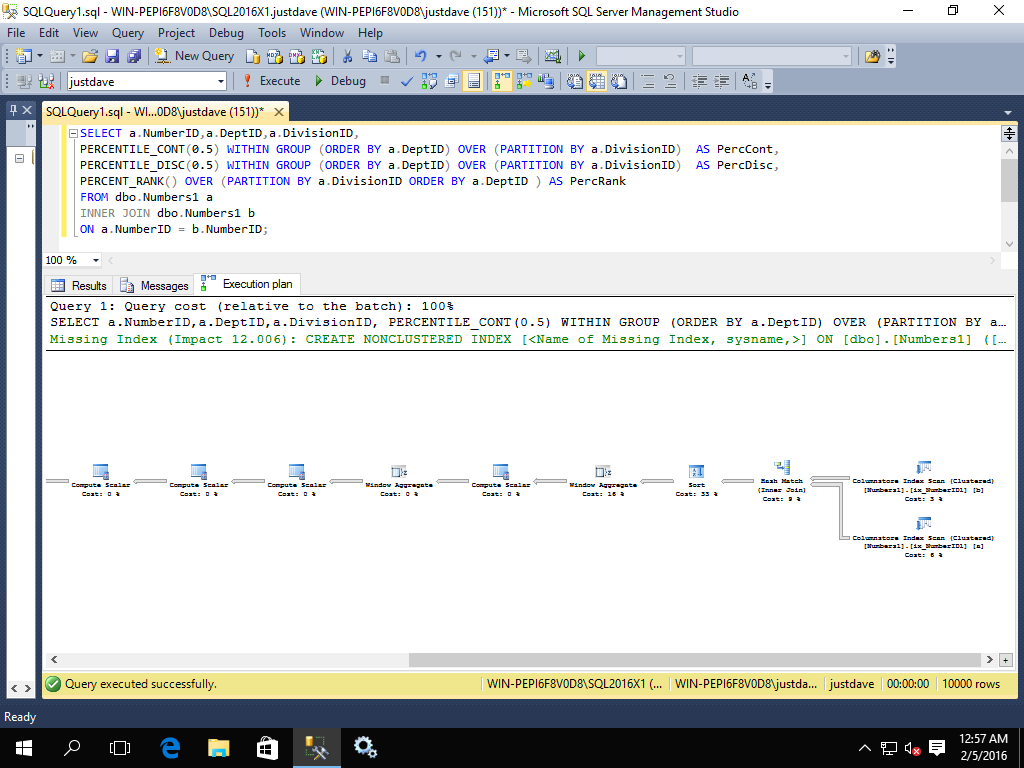
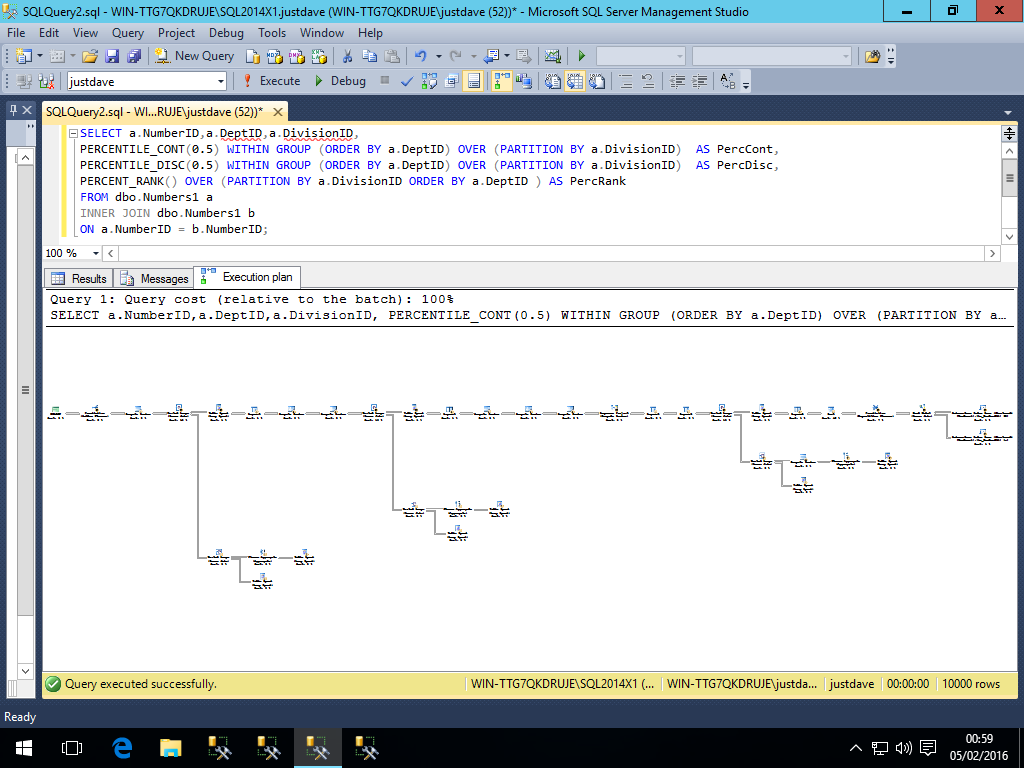
Whereas in 2014 all operators to the left of the hash match from the index scan (apart from the final computer scalar)are in row mode with spools/nested loop joins
Aggregate computation can be pushed down to be done during the scan node of the query plan
The following operations support pushing the aggregate calculation down to be done during the SCAN node of a query plan
Limitations are:
- Any datatype <= 64 bits is supported
- The aggregate operator must be on top of SCAN node or SCAN node with group by
The aggregation is done on compressed/encoded data in cache-friendly execution and by leveraging SIMD
String predicates can be pushed down in the SCAN node during a query plan
The primary/secondary dictionary created for column compression is used for predicate processing
The predicate is computed against just the dictionary entries rather than each row
If the dictionary entry passes the predicate all rows referring to the dictionary entry are automatically qualified
This results in potential performance improvements:
- Only the qualified rows are passed out of the SCAN node in the query plan rather than all rows
- The number of string comparisions matches the number of dictionary entries rather than the number of index rows
New DMVs
- sys.dm_db_column_store_row_group_operational_stats, added in CTP 2.0 - row-level I/O, locking, and access method activity for compressed rowgroups in a columnstore index
- sys.dm_db_column_store_row_group_physical_stats, added in CTP 2.0 - rowgroup-level information including why a rowgroup was trimmed to contain less than the maximum mrows and why the rowgroup moved from the delta store to the compress columnstore
- sys.internal_partitions, added in CTP 2.0 - tracks internal rowset data,deleted rows, rowgroup mappings, and delta store rowgroups
Updated DMVs
- sys.dm_db_xtp_hash_index_stats - adds xtp_object_id, added in CTP 2.0
- sys.dm_db_xtp_index_stats - adds xtp_object_id, added in CTP 2.0
- sys.dm_db_xtp_memory_consumers - adds xtp_object_id, added in CTP 2.0
- sys.dm_db_xtp_nonclustered_index_stats - adds xtp_object_id,uses_key_normalization, added in CTP 2.0
- sys.dm_db_xtp_object_stats - adds xtp_object_id, added in CTP 2.0
Need to add XEvents - WIP
Newly supported constructs are
- ALTER TABLE
- ALTER PROCEDURE
- Natively compiled inline table-valued functions (TVFs)
- Nesting natively compiled stored procedures (Nesting natively compiled stored procedures)
- Scalar User Defined Functions
- EXECUTE AS CALLER support - the EXECUTE AS clause is no longer required for native modules
- INSERT SELECT
- SELECT DISTINCT - DISTINCT aggregates are not supported
- UNION ALL and UNION
- COLUMNSTORE
- COLLATE
- LEFT OUTER JOIN, RIGHT OUTER JOIN, CROSS JOIN (not just SELECT queries) and INNER JOIN (not just SELECT queries)
- NOT, OR, and IN operators in SELECT, UPDATE and DELETE statements, in the WHERE clause, HAVING clause, and JOIN conditions.
This support extends to NOT IN and NOT BETWEEN
AND and EXISTS in the WHERE clause for SELECTs
WHERE is supported with UPDATE and DELETE statements,Subqueries are not supported. In the WHERE or HAVING clause, AND and BETWEEN are supported; OR, NOT, and IN are not supported.
- GROUP BY clause with no aggregate functions in the SELECT clause
- Scaler subqueries
- Subqueries [AS] table_alias
- Declaring variables as NULL or NOT NULL. If a variable is declared as NOT NULL, the declaration must have an initializer.
If a variable is not declared as NOT NULL, an initializer is optional
- All Math functions not just ACOS, ASIN, ATAN, ATN2, COS, COT, DEGREES, EXP, LOG, LOG10, PI, POWER, RADIANS, RAND, SIN, SQRT, SQUARE, and TAN
- Row level security functions IS_MEMBER({'group' | 'role'}), IS_ROLEMEMBER ('role' [, 'database_principal']),
IS_SRVROLEMEMBER ('role' [, 'login']), ORIGINAL_LOGIN(), SESSION_USER, CURRENT_USER, SUSER_ID(['login']),
SUSER_SID(['login'] [, Param2]), SUSER_SNAME([server_user_sid]), SYSTEM_USER, SUSER_NAME, USER,
USER_ID(['user']), USER_NAME([id]), CONTEXT_INFO()
IF OBJECT_ID('dbo.Person', 'U') IS NOT NULL
DROP TABLE dbo.Person;
CREATE TABLE Person
(
PersonID INT NOT NULL,
PersonName NVARCHAR(80),
PersonQuality NVARCHAR(50),
INDEX ix_PersonID NONCLUSTERED HASH (PersonId) WITH (BUCKET_COUNT=2000)
) WITH (MEMORY_OPTIMIZED=ON, DURABILITY=SCHEMA_ONLY);
INSERT into dbo.Person (PersonID) Values(1);
IF OBJECT_ID('dbo.PersonUpdateQuality', 'P') IS NOT NULL
DROP PROCEDURE dbo.PersonUpdateQuality;
CREATE PROCEDURE dbo.PersonUpdateQuality(@PersonID INTEGER)
WITH NATIVE_COMPILATION,SCHEMABINDING,EXECUTE AS SELF
AS
BEGIN ATOMIC
WITH (TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = N'us_english')
UPDATE dbo.Person Set PersonQuality='OK'
WHERE PersonID=@PersonID;
END;
SELECT * FROM dbo.Person;
EXECUTE dbo.PersonUpdateQuality 1;
SELECT * FROM dbo.Person;
ALTER PROCEDURE dbo.PersonUpdateQuality(@PersonID INTEGER,@PersonQuality NVARCHAR(50))
WITH NATIVE_COMPILATION,SCHEMABINDING,EXECUTE AS SELF
AS
BEGIN ATOMIC
WITH (TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = N'us_english')
UPDATE dbo.Person Set PersonQuality=@PersonQuality
WHERE PersonID=@PersonID;
END;
SELECT * FROM dbo.Person;
EXECUTE dbo.PersonUpdateQuality 1,'Excellent';
SELECT * FROM dbo.Person;
-- CTP 2.2 add EXECUTE AS CALLER
CREATE PROCEDURE dbo.PersonUpdateQuality(@PersonID INTEGER)
WITH NATIVE_COMPILATION,SCHEMABINDING,EXECUTE AS CALLER
AS
BEGIN ATOMIC
WITH (TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = N'us_english')
UPDATE dbo.Person Set PersonQuality='OK'
WHERE PersonID=@PersonID;
END
IF OBJECT_ID('dbo.PersonUpdateQuality', 'P') IS NOT NULL
DROP PROCEDURE dbo.PersonUpdateQuality;
IF OBJECT_ID('dbo.Person', 'U') IS NOT NULL
DROP TABLE dbo.Person;
CREATE TABLE dbo.Person
(
PersonID INT NOT NULL,
PersonName NVARCHAR(80),
PersonQuality NVARCHAR(50) NOT NULL,
INDEX ix_PersonID NONCLUSTERED HASH (PersonId) WITH (BUCKET_COUNT=2000)
) WITH (MEMORY_OPTIMIZED=ON, DURABILITY=SCHEMA_ONLY);
INSERT into dbo.Person (PersonID,PersonQuality) Values(1,'First Person');
INSERT into dbo.Person (PersonID,PersonQuality) Values(2,'Second Person');
-- Alter Memory Optimized Table - NEW
ALTER TABLE dbo.Person
ADD PersonComments NVARCHAR(200) NOT NULL CONSTRAINT PersonOK DEFAULT 'OK' WITH VALUES;
ALTER TABLE dbo.Person
ADD CONSTRAINT PK_PersonID PRIMARY KEY NONCLUSTERED (PersonID);
ALTER TABLE dbo.Person
ADD INDEX Quality (PersonQuality);
ALTER TABLE dbo.Person
DROP INDEX Quality;
ALTER TABLE dbo.Person
DROP CONSTRAINT PersonOK;
ALTER TABLE dbo.Person
DROP COLUMN PersonComments;
ALTER TABLE dbo.Person
ALTER INDEX ix_PersonID
REBUILD WITH (BUCKET_COUNT=5000);
In CTP 2.0 In-Memory OLTP now fully supports collations.
- (var)char columns can use any code page supported by SQL Server
- Character columns in index keys can use any SQL Server collation
- Expressions in natively compiled modules as well as constraints on memory-optimized tables can use any SQL Server collation
-- All syntax needed
-- Msg 10796, Level 15, State 2, Procedure fn_securitypredicate, Line 27
-- The SCHEMABINDING option is supported only for natively compiled modules, and is required for those modules.
-- Msg 10783, Level 15, State 2, Procedure fn_securitypredicate, Line 19
-- The body of a natively compiled module must be an ATOMIC block.
-- Msg 10784, Level 15, State 1, Procedure fn_securitypredicate, Line 18
-- The WITH clause of BEGIN ATOMIC statement must specify a value for the option 'transaction isolation level'.
-- Msg 10784, Level 15, State 1, Procedure fn_securitypredicate, Line 18
-- The WITH clause of BEGIN ATOMIC statement must specify a value for the option 'language'.
IF OBJECT_ID('dbo.fn_AddOne', 'FN') IS NOT NULL
DROP FUNCTION dbo.fn_AddOne;
CREATE FUNCTION dbo.fn_AddOne(@Number INTEGER)
RETURNS INTEGER
WITH NATIVE_COMPILATION,SCHEMABINDING,EXECUTE AS SELF
AS
BEGIN ATOMIC
WITH (TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = N'us_english')
RETURN @Number+1;
END;
-- CTP 2.2 add EXECUTE AS CALLER
IF OBJECT_ID('dbo.fn_AddOne', 'FN') IS NOT NULL
DROP FUNCTION dbo.fn_AddOne;
CREATE FUNCTION dbo.fn_AddOne(@Number INTEGER)
RETURNS INTEGER
WITH NATIVE_COMPILATION,SCHEMABINDING,EXECUTE AS CALLER
AS
BEGIN ATOMIC
WITH (TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = N'us_english')
RETURN @Number+1;
END;
Constraints on in-memory OLTP tables
- Primary
- Foreign - cascade, not yet! currently must reference a primary key!
- Unique
- Check
IF OBJECT_ID('dbo.Person', 'U') IS NOT NULL
DROP TABLE dbo.Person;
CREATE TABLE Person
(
PersonID INT NOT NULL PRIMARY KEY NONCLUSTERED,
PersonName NVARCHAR(80),
PersonAge INT CONSTRAINT cc_Page CHECK (PersonAge>0),
PersonEmployeeID INT NOT NULL,
PersonQuality NVARCHAR(50),
INDEX ix_PersonID NONCLUSTERED HASH (PersonId) WITH (BUCKET_COUNT=2000),
CONSTRAINT uc_PersonEmployeeID UNIQUE (PersonEmployeeID)
) WITH (MEMORY_OPTIMIZED=ON, DURABILITY=SCHEMA_ONLY);
IF OBJECT_ID('dbo.Orders', 'U') IS NOT NULL
DROP TABLE dbo.Orders;
CREATE TABLE Orders
(
OrderID INT NOT NULL PRIMARY KEY NONCLUSTERED,
SalesPerson INT FOREIGN KEY (SalesPerson) REFERENCES dbo.Person(PersonID),
UnitsSold INT
) WITH (MEMORY_OPTIMIZED=ON, DURABILITY=SCHEMA_ONLY);
Triggers on memory optimizerd tables
IF OBJECT_ID('dbo.Orders', 'U') IS NOT NULL
DROP TABLE dbo.Orders;
CREATE TABLE Orders
(
OrderID INT NOT NULL PRIMARY KEY NONCLUSTERED,
Department VARCHAR(20),
UnitsSold INT
) WITH (MEMORY_OPTIMIZED=ON, DURABILITY=SCHEMA_ONLY);
IF OBJECT_ID('dbo.TotalOrders', 'U') IS NOT NULL
DROP TABLE dbo.TotalOrders;
CREATE TABLE TotalOrders
(
Department VARCHAR(20) PRIMARY KEY NONCLUSTERED,
TotalOrders INT NOT NULL,
LastAction CHAR(1)
) WITH (MEMORY_OPTIMIZED=ON, DURABILITY=SCHEMA_ONLY);
INSERT INTO dbo.TotalOrders (Department,TotalOrders) VALUES ('Sales',0);
IF OBJECT_ID('dbo.OrderInsert', 'TR') IS NOT NULL
DROP TRIGGER dbo.OrderInsert;
CREATE TRIGGER OrderInsert
ON dbo.Orders
WITH NATIVE_COMPILATION,SCHEMABINDING
AFTER INSERT
AS
BEGIN ATOMIC
WITH (TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = N'us_english')
UPDATE dbo.TotalOrders
SET TotalOrders=TotalOrders+1,
LastAction='I'
WHERE Department='Sales';
END;
SELECT * FROM dbo.Orders;
SELECT * FROM dbo.TotalOrders;
INSERT INTO dbo.Orders(OrderID,Department,UnitsSold) VALUES(1,'Sales',10);
INSERT INTO dbo.Orders(OrderID,Department,UnitsSold) VALUES(2,'Sales',20);
SELECT * FROM dbo.Orders;
SELECT * FROM dbo.TotalOrders;
IF OBJECT_ID('dbo.OrderDelete', 'TR') IS NOT NULL
DROP TRIGGER dbo.OrderDelete;
CREATE TRIGGER OrderDelete
ON dbo.Orders
WITH NATIVE_COMPILATION,SCHEMABINDING
AFTER DELETE
AS
BEGIN ATOMIC
WITH (TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = N'us_english')
UPDATE dbo.TotalOrders
SET TotalOrders=TotalOrders-1,
LastAction='D'
WHERE Department='Sales';
END;
SELECT * FROM dbo.Orders;
SELECT * FROM dbo.TotalOrders;
DELETE FROM dbo.Orders where OrderID=1;
SELECT * FROM dbo.Orders;
SELECT * FROM dbo.TotalOrders;
IF OBJECT_ID('dbo.OrderUpdate', 'TR') IS NOT NULL
DROP TRIGGER dbo.OrderUpdate;
CREATE TRIGGER OrderUpdate
ON dbo.Orders
WITH NATIVE_COMPILATION,SCHEMABINDING
AFTER UPDATE
AS
BEGIN ATOMIC
WITH (TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = N'us_english')
UPDATE dbo.TotalOrders
SET LastAction='U'
WHERE Department='Sales';
END;
SELECT * FROM dbo.Orders;
SELECT * FROM dbo.TotalOrders;
UPDATE dbo.Orders SET UnitsSold = 5 WHERE OrderID=2;
SELECT * FROM dbo.Orders;
SELECT * FROM dbo.TotalOrders;
In CTP 3.1
- NULLable index key columns
- LOB types [varchar(max), nvarchar(max), and varbinary(max)]
- UNIQUE indexes
IF OBJECT_ID('dbo.Person', 'U') IS NOT NULL
DROP TABLE dbo.Person;
CREATE TABLE Person
(
PersonID INT NOT NULL PRIMARY KEY NONCLUSTERED,
PersonName NVARCHAR(80),
PersonAge INT CHECK (PersonAge>0),
PersonEmployeeID INT NULL, -- Nullable index column
PersonQuality1 VARCHAR(MAX),
PersonQuality2 NVARCHAR(MAX),
PersonQuality3 VARBINARY(MAX),
INDEX ix_PersonID NONCLUSTERED HASH (PersonId) WITH (BUCKET_COUNT=2000),
INDEX ix_PersonEmployeeID UNIQUE (PersonEmployeeID)
) WITH (MEMORY_OPTIMIZED=ON, DURABILITY=SCHEMA_ONLY);
A database can now have up to 2 terabytes of user data in memory-optimized tables with SCHEMA_AND_DATA
- Multiple threads to persist memory-optimized tables
- Multi-threaded recovery
- MERGE Operation is now multi-threaded
- The In-memory OLTP engine continues to use memory-optimized filegroup based on FILESTREAM, but the individual files in the filegroup are decoupled from FILESTREAM
- These files are fully managed (such as for create, drop, and garbage collection) by the In-Memory OLTP engine.
- DBCC SHRINKFILE (Transact-SQL) is not supported.
- Manual Merge has been disabled as multi-threaded merge is expected to keep up with the load.
v
The Save-SqlMigrationReport cmdlet is a tool that evaluates the migration fitness of multiple objects in a SQL Server database.
Currently, it is limited to evaluating the migration fitness for In-Memory OLTP.
Save-SqlMigrationReport [ -MigrationType OLTP ] [ -Server server -Database database [ -Object object_name ] ] | [ -InputObject smo_object ] -FolderPath path
The report goes into 2 folders under FolderPath (Tables and Stored Procedures)
2.1.4.7 Query Store Read only Mode (CTP 2.2)
2.1.4.8 Query Store UI enhancements and bug fixes (CTP 2.2)
2.1.4.9 No force plan recompiles after MAX_PLANS_PER_QUERY is hit (CTP 2.2)
2.1.5 Temporal Tables
2.1.5.1 Base release (CTP 2.0)
2.1.5.2 Support for computed columns (CTP 2.1)
2.1.5.3 Support for marking one or both period columns with HIDDEN flag (CTP 2.1)
2.1.5.4 Full support column with ROWVERSION (TIMESTAMP) (CTP 2.2)
2.1.5.5 COLUMNPROPERTY exposes ‘ishidden’ property (CTP 2.2)
2.1.5.6 Several improvements in SQL Server Management Studio (CTP 2.2)
2.1.5.7 One or both period columns can be marked with the hidden flag (CTP 2.3)
2.1.5.8 In-memory OLTP support (CTP 3.0)
2.1.5.9 Alter table support (CTP 3.0)
2.1.5.10 FOR SYSTEM_TIME ALL (CTP 3.0)
2.1.5.11 Optimized CONTAINED IN implementation with minimized locking on current table (CTP 3.0)
2.1.6 Backup to Microsoft Azure
2.1.7 Managed Backup
2.1.8 Trace Flag 4199
2.1.9 JSON
2.1.9.1 FOR JSON (CTP 2.0)
2.1.9.2 OPENJSON (CTP 3.0)
2.1.9.3 ISJSON (CTP 3.0)
2.1.9.4 JSON_VALUE (CTP 3.0)
2.1.9.5 JSON_QUERY (CTP 3.0)
2.1.9.6 AdventureWorks sample database support (CTP 3.0)
2.1.9.7 FOR JSON/WITHOUT_ARRAY_WRAPPER (CTP 3.2)
2.1.10 Always Encrypted
2.1.10.1 Always Encrypted (CTP 2.0)
2.1.10.2 Management Studio enhancements related to dialog boxes, and the Always Encrypted Wizard (CTP 3.0)
2.1.10.3 Elimination of some restrictions (CTP 3.0)
2.1.10.4 The word DEFINITION was removed from column master keys (CTP 3.0)
2.1.10.5 The COLUMN MASTER KEY argument of CREATE COLUMN ENCRYPTION KEY (Transact-SQL) has been renamed to COLUMN_MASTER_KEY (CTP 3.0)
2.1.10.6 Built-in support for using column master keys stored in hardware security modules (HSMs) that provide Crypto API (CAPI) or Cryptography API - Next Generation (CNG) (CTP 3.0)
2.1.10.7 The CREATE USER syntax is enhanced with the ALLOW_ENCRYPTED_VALUE_MODIFICATIONS option to support the Always Encrypted feature (CTP 3.0)
2.1.11 PolyBase
2.1.12 Stretch Database
2.1.12.1 Base release (CTP 2.0)
2.1.12.2 Lock Escalation (CTP 2.1)
2.1.12.3 Automatic encryption and validation requirement of remote server certification (CTP 2.1)
2.1.12.4 Security Policies and Row Level Security (CTP 2.2)
2.1.12.5 Stretch Database Advisor (CTP 2.2)
2.1.12.6 SSMS enhancements (CTP 3.0)
2.1.12.7 Enable Stretch Database Wizard enhancements (CTP 3.0)
2.1.12.8 Database scoped credentials (CTP 3.0)
2.1.12.9 Join Performance improvement (CTP 3.0)
2.1.12.10 AdventureWorks sample database (CTP 3.0)
2.1.12.11 Specify a predicate which must call an inline table-valued function (CTP 3.1)
2.1.12.12 Compatibile with Temporal tables (CTP 3.1)
2.1.12.12 Unmigrate tables (CTP 3.1)
2.1.12.12 Compatibile with Always On (CTP 3.1)
2.2 Transact-SQL Enhancements
2.2.1 TRUNCATE TABLE for specific partitions (CTP 2.0)
2.2.2 ALTER TABLE many actions whilst table is still available (CTP 2.0)
2.2.3 New query hint NO_PERFORMANCE_SPOOL (CTP 2.0)
2.2.4 The FORMATMESSAGE (Transact-SQL) statement accepts a msg_string argument (CTP 2.0)
2.2.5 Additional DROP IF syntax (CTP 3.0)
2.2.6 A MAXDOP option has been added to DBCC CHECKTABLE/DBCC CHECKDB/DBCC CHECKFILEGROUP (CTP 3.0)
2.2.7 SESSION_CONTEXT can now be set (CTP 3.0)
2.2.8 Advanced Analytics Extensions allow users to execute scripts written in a supported language such as R (CTP 3.0)
2.2.9 The CREATE USER syntax is enhanced with the ALLOW_ENCRYPTED_VALUE_MODIFICATIONS option (CTP 3.0)
2.2.10 GZIP COMPRESS/UNCOMPRESS functions (CTP 3.1)
2.2.11 DATEDIFF_BIG/AT TIME ZONE/sys.time_zone_info (CTP 3.1)
2.3 System View Enhancements
2.3.1 Two new views support row level security (CTP 2.0)
2.3.2 Seven new views support the Query Store feature (CTP 2.0)
2.3.3 24 new columns are added to sys.dm_exec_query_stats to provide information about memory grants (CTP 2.0)
2.3.4 Two new query hints (MIN_GRANT_PERCENT and MAX_GRANT_PERCENT) are added to specify memory grants (CTP 2.0)
2.3.5 sys.dm_exec_session_wait_stats (Transact-SQL) provides a per session report similar to the server wide sys.dm_os_wait_stats (CTP 2.2)
2.3.6 sys.dm_exec_function_stats (Transact-SQL) provides execution statistics regarding scalar valued functions (CTP 2.3)
2.3.7 sys.dm_fts_index_keywords_position_by_document (CTP 2.0)
2.4 Security Enhancements
2.4.1 Row Level Security
2.4.1.1 Row-Level Security (CTP 2.0)
2.4.1.2 Row-level security is supported for memory-optimized tables (CTP 2.3)
2.4.1.1 Row-level security adds support for block predicates. SESSION_CONTEXT can now be set for use in a security policy. (CTP 3.0)
2.4.2 Dynamic Data Masking
2.4.1.1 Dynamic Data Masking (CTP 2.0)
2.4.1.2 Many enhancements (CTP 3.0)
2.4.3 New Permissions
2.4.3.1 ALTER ANY SECURITY POLICY for row level security (CTP 2.0)
2.4.3.2 ALTER ANY MASK and UNMASK for dynamic data masking (CTP 2.0)
2.4.3.3 ALTER ANY COLUMN ENCRYPTION KEY, VIEW ANY COLUMN ENCRYPTION KEY, ALTER ANY COLUMN MASTER KEY DEFINITION for Always Encrypted (CTP 2.0)
2.4.3.4 ALTER ANY EXTERNAL DATA SOURCE/ALTER ANY EXTERNAL FILE FORMAT for Analytics Platform System (SQL Data Warehouse) (CTP 3.2)
2.4.3.5 EXECUTE ANY EXTERNAL SCRIPT for supporting R scripts (CTP 3.0)
2.4.4 Transparent Data Encryption
2.4.4.1 Support for Intel AES-NI hardware acceleration of encryption (CTP 2.0)
2.4.5 AES Encryption for Endpoints
2.5 High Availability Enhancements
2.5.1 SQL Server 2016 CTP Standard Edition now supports AlwaysOn Basic Availability Groups (CTP 3.2)
2.5.2 Load-balancing of read-intent connection requests is now supported across a set of read-only replicas (CTP 2.0)
2.5.3 The number of replicas that support automatic failover has been increased from two to three (CTP 2.0)
Group Managed Service Accounts are now supported for AlwaysOn Failover Clusters (CTP 2.0)
AlwaysOn Availability Groups supports distributed transactions and the DTC on Windows Server 2016 (CTP 2.0)
2.5.6 AlwaysOn Availability Groups can be configure to failover when a database goes offline (CTP 2.0)
2.5.2 AlwaysOn now supports encrypted databases (CTP 2.2)
2.6 Tools Enhancements
2.6.1 SQL Server Management Studio
2.6.1.1 SSMS supports the Active Directory Authentication Library (ADAL) for connecting to Microsoft Azure (CTP 2.0)
2.6.1.2 SSMS requires .NET Framework 4.6 (CTP 2.0)
2.6.1.3 SSMS new query result grid option supports keeping Carriage Return/Line Feed characters (CTP 3.0)
2.6.2 Upgrade Advisor
2.6.2.1 QL Server 2016 Upgrade Advisor Preview 1 standalone tool (CTP 2.2)
2.7 Replication Enhancements
2.7.1 Replication for memory optimized tables (CTP 3.0)
2.7.2 Replication to Azure SQL Database (CTP 3.0)